
Bringt Apache Spark (SQL) Licht ins Datendickicht?
Apache Spark ist immer weiter auf dem Vormarsch. Wie interagiert dieses Framework für Cluster Computing mit anderen Technologien, wozu wird es verwendet und wie lässt es sich in ihre bestehende IT-Umgebung integrieren?
Apache Spark – der neue Stern am Analytics-Himmel oder doch nur eine Wunderkerze?
Seit Spark die Analytics-Szene erreicht hat, werden immer mehr Stimmen laut, das diese Open Source Lösung beinahe alle Probleme löst. Auf den ersten Blick klingt das zwar verlockend, letztendlich entspricht es aber nicht den Tatsachen. Denn hoch performante Datenverarbeitung und anschließende Analyse sind alles andere als einfach. Dennoch werden für komplexe Aufgaben einfach anzuwendende Lösungen gesucht.
Folgende interessante Gespräche habe ich in der letzten Zeit führen können:
Interessent:
Wie positioniert sich Exasol im Vergleich zu Spark?
Ich:
Spark ist eine “general purpose platform (GPP)”, d.h. eine Plattform, die sehr vielseitig einsetzbar ist und auf einem modernen Loading...In-Memory Ansatz für verteilte Datenverarbeitung basiert. Wir von Exasol halten Spark für ein hervorragendes Add-on, dass auch als Teilersatz für das Arbeiten mit dem Loading...Hadoop File System fungieren kann. Exasol integriert sich vollkommen nahtlos in Spark, dennoch denke ich, dass Ansatz und Anwendungsgebiete von Exasol und Spark sich stark voneinander unterscheiden.
Interessent:
Aber es ist doch auch eine Loading...In-Memory Datenbank wie Exasol, richtig?
Ich:
Nun, es gibt in der Tat ein Datenbankmodul namens Spark SQL, welches auf der Standard Spark Plattform läuft.
Interessent:
(panisch) Wenn es jetzt eine weitere Datenbank gibt, die auch noch kostenlos ist – macht ihnen das keine Sorgen? Wer würde eine Exasol-Lizenz kaufen, wenn er Spark umsonst bekommt?
Ich:
(gelassen) Immer mit der Ruhe. Schauen wir uns doch erst einmal die Fakten an:
| Analytische Datenbank EXASOL | Apache Spark | |
|---|---|---|
| What is it? | Die Lösung wurde von Grund auf als analytische In-Memory Datenbank für Loading...Big Data entwickelt. | Spark wurde als Plattform konzipiert, für vielfältige Einsatzmöglichkeiten in der Verarbeitung von Big Data. |
| Worauf basiert die Technologie? | EXASOL ist in C++ geschrieben und stützt sich auf Algorithmen die gleichzeitig niedrige Latenz und hohe Performance sicherstellen sowie auf spezialisierte Subsysteme. | Spark und Spark SQL sind auf JVM Basis geschrieben (um genau zu sein in Scala). Scala ermöglicht zwar schnelle Entwicklungszyklen, eignet sich aber nicht unbedingt für Anwendungen in Echtzeit. |
| Optimierung | Optimiert für schnelle Abfragen, hohen Datendurchsatz, sowie parallel Verarbeitung | Da Spark SQL mit Spark auf einer GPP basiert, kann die Lösung nur eingeschränkt zu Datenbankenzwecken optimiert werden. |
| Performance | Schnellste Loading...relationale Datenbank auf dem Markt (1) | Ziemlich schnell, aber nicht die schnellste Datenbank auf Hadoop (2) und ein vielfaches langsamer als EXASOL. |
| Marktreife | In 2000 gegründet. Erster Kunde 2006 produktiv. Eine Vielzahl an Kunden setzt die Lösung zur Analyse geschäftskritische Bereiche ein. | Entwicklung begann 2013. Erste Version wurde in 2014 veröffentlicht. |
| Benutzerfreundlichkeit | Einfach zu installieren und zu verwalten. Schwerpunkt liegt auf auf niedriger TCO. | Äußerst technisch und als Share-Plattform konzipiert – daher ist gewissenhaftes Ressourcenmanagement ein Muss. |
| Nutzen für Unternehmen | Umfangreiche Backupmöglichkeiten, Fernwartungsinterfaces, externe Datenbankreplikation und viele weitere Enterprise-Features. Über 100 Kunden setzten bei ihren Analysen bereits auf EXASOL. | Keine auf Geschäftskunden zugeschnittenen Features vorhanden. |
(1) Basierend auf TPC-H Ergebnissen: TPC-H Benchmark – Exasol
(2) https://blog.cloudera.com/apache-impala-leads-traditional-analytic-database/
Interessent:
OK, also ist Spark keine echte Alternative zu Exasol, wenn es um maximale Abfragegeschwindigkeit geht oder wenn die Lösung in unternehmenskritischen Bereichen eingesetzt werden soll? Wieso macht sie Spark dann nervös?
Ich:
Ich hab niemals behauptet, dass wir uns ernsthaft Sorgen machen. Wir wissen, dass Exasol viel besser für Datenanalysen bei großen, komplexen Datenmengen geeignet ist als Spark. Punkt.
Interessent:
OK, aber denken Sie, dass sich Spark für die Datenverarbeitung gut eignet?
Ich:
Ja definitiv. Spark hat das schwerfällige MapReduce Konzept von Hadoop in eine Form transformiert, die viel besser in das Internetzeitalter mit seinen kurzen Entwicklungszyklen passt. Etwa für „Data Streaming“ und polystrukturierte Daten ist es eine hervorragende Lösung.
Interessent:
Habe ich nun aber nicht zwei Lösungen, die voneinander isoliert sind? Exasol als hoch performante relationale Datenbank im Backend für unternehmenskritische Anwendungen und Spark für meine Datenverarbeitung?
Ich:
Nein, denn die beiden Technologien lassen sich leicht gemeinsam nutzen.
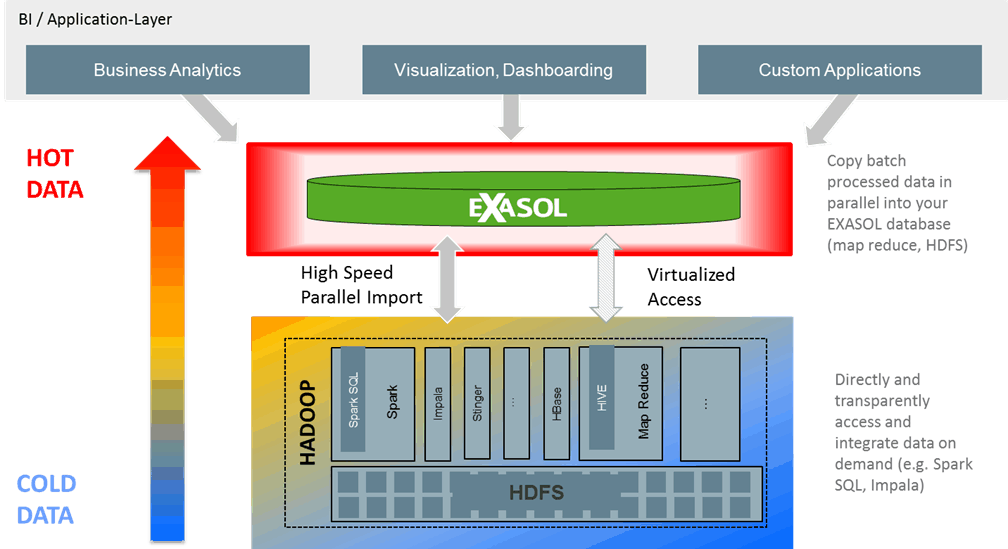
Sehen wir uns diese Grafik an:
Ich:
Wir integrieren Spark und Hadoop auf verschiedenen Ebenen.
- Beim Datenimport – üblicherweise werden zuerst Rohdatenbestände analysiert in Spark/Hadoop, die in verschiedenen Formaten vorhanden sind. Anschließend müssen die Daten für interaktive Analyse oder für ein weiteres Verarbeiten zur Verfügung stehen. Dafür importieren sie einfach parallel die Daten in Exasol (mehrere GB pro Sekunde) vom HDFS mithilfe unseres parallelen Importer oder importieren Sie diese direkt aus Hive, Impala, Spark SQL via JDBC.
- Sie möchten Ihre Daten nicht replizieren? Sie wollen Zugriff auf genau die Daten haben, die ihre Spark-Plattform gerade vor einigen Sekunden generiert hat? Hier kommt unser Datenvirtualisierungs-Framework zum Einsatz. Verbinden Sie einfach Spark SQL mit Exasol durch ein „virtuelles Schema“ und die Spark SQL Schemas sind sofort in Exasol sichtbar.
Aus Kundensicht ist es völlig transparent, ob die Daten in Exasol oder extern in Spark gespeichert sind. Der Kunde sieht alles als eine einzige Datenquelle, nämlich als Exasol. Sobald man auf ein virtuell verbundenes Schema zugreift, wird die Abfrage auf Spark SQL weitergeleitet, dann die (Unter)Abfrage ausgeführt und anschließend das Ergebnis an Exasol gesendet. Und wenn Sie noch schnelleren Zugriff auf ihre Daten möchten? Kein Problem: Materialisieren Sie einfach die Daten , die Sie aus der Spark SQL Abfrage erhalten in Exasol und nutzen Sie die blitzschnelle In-Memory Analyse in der Exasol Datenbank.
Haben Sie alles Verstanden?
Interessent: Ja, besten Dank!
Weitere Informationen sowie eine kostenlose Testversion finden Sie unter www.exasol.com/de/download