Normalization vs Denormalization

Normalization and denormalization are two opposing approaches to structuring data in a database. Normalization splits data into related tables to reduce redundancy and maintain consistency. Denormalization combines or duplicates data to simplify queries and improve read performance, often resulting in duplicated data across tables, also known as denormalized data.
The difference is not about which approach is better. It is about trade-offs. Normalization prioritizes data integrity and reliable updates. Denormalization prioritizes faster reads and simpler queries by reducing joins.
Most production systems use both approaches. In many systems, data is normalized first to establish a clean structure, then selectively denormalized to meet performance requirements. The right choice depends on how the data is queried, updated, and scaled.

Try Exasol Personal for Free
Run real workloads at full Exasol performance.
Side-by-side Comparison
Normalization stores data in separate, related tables to eliminate duplication. Denormalization stores related data together, even if it introduces duplication.
The result is a trade-off between data integrity and query performance. Normalization ensures that each piece of data exists in one place, which prevents inconsistencies during updates. Denormalization reduces the need for joins by storing pre-combined or duplicated data, which simplifies queries and improves read performance. The difference becomes clearer when comparing how each approach handles structure, queries, and updates.
| Aspect | Normalization | Denormalization |
|---|---|---|
| Data structure | Data is split into multiple related tables based on entities | Related data is combined or duplicated across tables |
| Redundancy | Eliminated by storing each fact once | Introduced intentionally to avoid joins |
| Data integrity | High, because each value has a single source of truth | Lower, because duplicate values must be kept consistent |
| Query complexity | Higher, requires joins across tables | Lower, fewer joins or none required |
| Read performance | Can decrease as joins increase | Improves for read-heavy workloads by reducing joins |
| Write behavior | Simpler updates, changes occur in one place | More complex updates, changes may affect multiple records |
| Storage usage | More efficient due to minimal duplication | Less efficient due to duplicated data |
| Maintenance | Easier to maintain consistency | Requires additional logic to prevent inconsistencies |
| Best use case | Transactional systems and consistency-critical applications | Read-heavy systems, analytics, and performance optimization |
Normalization reduces redundancy by ensuring each fact is stored once, which avoids update anomalies such as conflicting values across rows. Denormalization improves read performance by shifting complexity from query execution to data storage.
In practice, these approaches are often combined. A system may use normalized tables for core data and introduce denormalized structures where query performance becomes a bottleneck.
What is Normalization?
Normalization is the process of organizing data into separate, related tables so that each piece of information is stored only once.
As a core principle of database design, the goal of normalization is to reduce redundancy and maintain consistency. Instead of repeating the same data across multiple rows, normalized databases store that data in one place and reference it using relationships, typically through primary and foreign keys.
This structure prevents common data anomalies. For example, when the same value is stored in multiple rows, an update can leave inconsistent versions of that value. Normalization avoids this by ensuring there is a single source of truth.
Why Normalization Reduces Redundancy
Normalization separates data based on logical relationships. For example, customer information and order data are stored in different tables instead of being repeated in every order record. This eliminates duplicate values and reduces storage overhead.
Why Normalization Improves Data Integrity
When each piece of data exists in only one place, updates are consistent by design. Changing a value updates it at the source, ensuring all references remain consistent. This prevents update, insert, and delete anomalies that occur when duplicated data becomes inconsistent.
How Normalized Databases Are Structured
Normalized databases use multiple related tables connected through keys within relational database models. Each table represents a single entity, such as customers, orders, or products. Relationships between these tables allow queries to reconstruct the full dataset using joins.
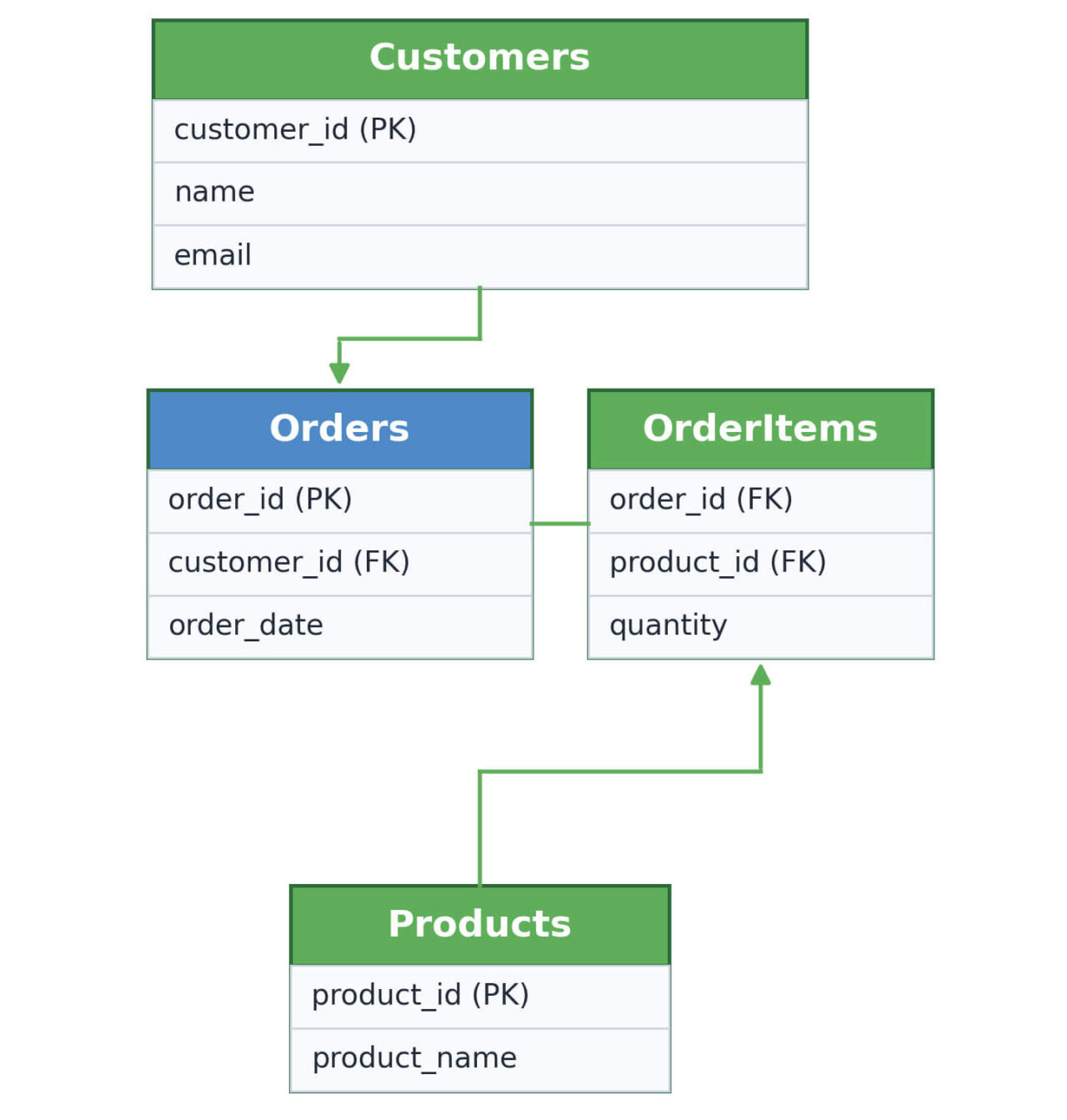
This structure increases query complexity, but it ensures that the data remains accurate and consistent as the system evolves.
What is Denormalization?
Denormalization is the process of combining or duplicating data across tables to simplify queries and improve read performance.
Instead of storing each piece of data in a single location, denormalized databases allow the same data to appear in multiple places. This reduces the need for joins when retrieving data, which can improve query speed in read-heavy workloads.
Denormalization shifts complexity from query execution to data storage. Queries become simpler because the data is already pre-combined, but updates become more complex because the same value may need to be changed in multiple locations.
Why Denormalization Improves Read Performance
Denormalization reduces the number of joins required to retrieve related data. Joins can become expensive as datasets grow, especially when multiple tables are involved. By storing related data together, queries can access the required information directly.
Why Denormalization Introduces Redundancy
Denormalization stores duplicate values across rows or tables. For example, customer details may be stored alongside each order instead of being referenced from a separate table. This simplifies reads but increases storage usage and creates the risk of inconsistent data if updates are not applied everywhere.
How Denormalized Databases Are Structured
Denormalized databases store related data in fewer tables or pre-joined formats, or duplicate data across existing tables. This can include flattening multiple entities into a single table or embedding related attributes directly within records.
This structure reduces query complexity but requires careful handling of updates to avoid inconsistencies. Systems that use denormalization often implement additional logic to keep duplicated data in sync.
Try Exasol Personal for Free
Run real workloads at full Exasol performance.
When To Use Normalization
Normalization is most appropriate when data consistency, accuracy, and reliable updates are the primary requirements. It ensures that each piece of data is stored in one place, which reduces the risk of inconsistencies and simplifies data maintenance.
Transactional Systems and Write-heavy Applications
Normalization works best in systems that handle frequent inserts, updates, and deletes. In these environments, storing each value once ensures that updates remain consistent and predictable.
For example, in an order management system, customer data should not be duplicated across every order. Storing it in a separate table ensures that a single update applies everywhere the data is referenced.
Systems With Frequent Updates Across Related Data
When the same data is used in multiple contexts, normalization prevents inconsistencies. If a value changes, it only needs to be updated in one place.
This is important in systems where data relationships are tightly connected, such as customer records, inventory systems, or financial data.
Situations Where Data Integrity Matters Most
Normalization is critical when incorrect or inconsistent data has direct consequences. This includes systems that require accurate reporting, auditing, or compliance.
By enforcing a single source of truth, normalization prevents anomalies such as:
- conflicting values across rows
- incomplete inserts due to missing dependencies
- unintended data loss during deletions
In these cases, normalization ensures that the database remains consistent as it grows and evolves.
When To Use Denormalization
Denormalization is most appropriate when read performance, query simplicity, and fast data retrieval are the primary requirements. It reduces the need for joins by storing related data together, which makes queries faster and easier to execute. The choice depends on workload type, such as OLTP and OLAP database types.
Read-heavy Applications
Denormalization is effective in systems where data is read far more often than it is updated. By reducing joins, queries can retrieve data directly from a single table or a smaller number of tables.
This is common in applications where response time is critical, such as user-facing dashboards or high-traffic web services.
Analytics, Reporting, and Precomputed Data
Analytical workloads often require aggregating large amounts of data across multiple dimensions. Denormalization simplifies these queries by storing pre-joined or pre-aggregated data.
For example, reporting systems may store customer and order data together to avoid repeated joins during query execution. This reduces query time and simplifies query logic.
Performance Optimization After Normalization
Denormalization is often applied after a normalized schema is already in place, as part of broader steps in database design process. When query performance becomes a bottleneck, selected parts of the schema are denormalized to reduce join overhead.
This approach preserves the benefits of normalization while improving performance where it matters. It allows systems to balance consistency and speed without fully sacrificing either.
Try Exasol Personal for Free
Run real workloads at full Exasol performance.
Normalized vs Denormalized Tables: Practical Example
The difference between normalized and denormalized tables becomes clearer when comparing how the same data is structured.
Example of a Normalized Schema
In a normalized design, related data is stored in separate tables and connected through keys.
Customers table:
| customer_id | name | |
|---|---|---|
| 1 | Alice Smith | alice@email.com |
Orders table:
| order_id | customer_id | order_date |
|---|---|---|
| 101 | 1 | 2024-01-10 |
Products table:
| product_id | product_name |
|---|---|
| 55 | Laptop |
Each table stores a single type of entity. Relationships are created using identifiers such as customer_id. Queries reconstruct the full dataset by joining these tables.
Example of a Denormalized Schema
In a denormalized design, related data is stored together, even if it results in duplication.
Orders table (denormalized)
| order_id | customer_name | customer_email | product_name | order_date |
|---|---|---|---|---|
| 101 | Alice Smith | alice@email.com | Laptop | 2024-01-10 |
Customer and product data are stored directly in the orders table. This removes the need for joins when retrieving order information.
What Changes Between the Two Designs
- Data duplication: The denormalized table repeats customer and product data for each order, while the normalized schema stores it once.
- Query complexity: The normalized schema requires joins to retrieve complete data. The denormalized table can be queried directly.
- Update behavior: In the normalized schema, updates occur in one place. In the denormalized table, updates may need to be applied to multiple rows.
- Read performance: The denormalized table reduces query overhead by avoiding joins, which can improve performance in read-heavy workloads.
SQL Examples of Normalization and Denormalization
SQL examples show how normalization and denormalization affect both schema design and query behavior.
A Simple Normalized Schema In SQL
In a normalized design, data is separated into related tables.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);Customer data is stored once in the customers table. The orders table references it using customer_id.
Querying Normalized Tables with Joins
To retrieve order data with customer details, a join is required:
SELECT o.order_id, c.name, c.email, o.order_date
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;This approach ensures consistency but increases query complexity as more tables are involved.
A Denormalized Schema Example
In a denormalized design, related data is stored together:
CREATE TABLE orders_denormalized (
order_id INT PRIMARY KEY,
customer_id INT,
customer_name VARCHAR(100),
customer_email VARCHAR(100),
order_date DATE
);Customer data is duplicated in the same table as orders.
Querying Denormalized Data with Simpler Reads
Retrieving the same data no longer requires a join:
SELECT order_id, customer_name, customer_email, order_date
FROM orders_denormalized;This simplifies queries and can improve read performance in read-heavy workloads by reducing the need for joins. However, updates may require modifying multiple rows, which increases write complexity.
What The SQL Examples Reveal About Trade-offs
- Consistency: The normalized schema keeps customer data in one place, which simplifies updates.
- Query complexity: The normalized query requires a join, while the denormalized query does not.
- Data duplication: The denormalized table stores repeated customer data.
- Performance trade-off: Normalization reduces redundancy, while denormalization reduces join complexity in queries.
Try Exasol Personal for Free
Run real workloads at full Exasol performance.
Normal Forms Explained Briefly
Normalization is typically applied in stages called normal forms, which define how data should be structured to reduce redundancy and improve consistency.
1NF, 2NF, and 3NF in Plain English
- First Normal Form (1NF):
Each column contains atomic values, and each row represents a unique record. This removes repeating groups and ensures that data is stored in a consistent format. - Second Normal Form (2NF):
In tables with composite primary keys, all non-key attributes must depend on the entire key. This prevents partial dependencies, where some data depends on only part of a composite key. - Third Normal Form (3NF):
Non-key attributes depend only on the primary key, not on other non-key attributes. This removes transitive dependencies and reduces redundancy caused by indirect relationships.
These forms progressively reduce redundancy and improve data integrity by enforcing stricter rules on how data is organized.
Why Denormalization Usually Starts from a Normalized Baseline
Denormalization is often applied after a schema has been normalized to at least 3NF. Starting from a normalized structure ensures that the data model is consistent and free of unnecessary duplication.
Once the baseline is established, selected parts of the schema can be denormalized to improve performance. This approach preserves data integrity while allowing targeted optimization where query performance becomes a concern.
Pros and Cons of Normalization
Normalization improves data consistency and reduces redundancy, but it also increases query complexity. The trade-off depends on how the data is accessed and maintained.
Pros
- Data integrity: Each piece of data is typically stored in one place, which reduces the risk of inconsistent values.
- Reduced redundancy: Duplicate data is minimized, which lowers the chance of update anomalies.
- Consistent updates: Changes are applied in a single location, which keeps all references consistent.
- Reduced duplication: Storing each value once minimizes unnecessary data repetition.
Cons
- More joins: Queries often require combining multiple tables to retrieve complete data.
- Higher query complexity: As the number of tables increases, queries become more complex to write and maintain.
- Potential read overhead: Join operations can increase query execution time as query complexity grows.
Normalization provides a structured and consistent data model, but it requires more complex queries to assemble related data during retrieval.
Pros and Cons of Denormalization
Denormalization improves read performance and simplifies data access, but it introduces redundancy and increases the complexity of maintaining consistent data.
Pros
- Faster reads: Storing related data together can improve query performance in read-heavy workloads by reducing joins.
- Simpler queries: Queries can retrieve complete datasets from a single table or fewer tables, which reduces query complexity.
- Reduced join complexity: Pre-combined data reduces the need for joins during query execution.
Cons
- Data redundancy: Duplicate values are stored across rows or tables, which increases storage usage.
- Update complexity: Changes to duplicated data may need to be applied in multiple places, which increases the risk of inconsistencies.
- Maintenance overhead: Additional logic is often required to keep duplicated data synchronized.
Denormalization simplifies data retrieval but requires careful handling of updates to maintain consistency across duplicated data.
Common Mistakes and Misconceptions
Misunderstanding normalization and denormalization often leads to poor database design decisions. These approaches are not opposites in a strict sense, and neither is universally better.
“Normalization is always better”
Normalization improves consistency and reduces redundancy, but it is not always the best choice for every system. In read-heavy workloads, highly normalized schemas can introduce unnecessary query complexity due to joins.
The correct approach depends on how the data is used. Systems that prioritize consistency and frequent updates benefit from normalization, while others may require different trade-offs.
“Denormalization is bad design”
Denormalization is often misunderstood as poor design because it introduces redundancy. In practice, it is a deliberate optimization technique used to improve query performance.
When applied selectively, denormalization can simplify data access and reduce query latency. The key is to manage duplication carefully to avoid inconsistencies.
“You have to choose one forever”
Normalization and denormalization are not mutually exclusive. Most systems combine both approaches depending on workload requirements. A common pattern is to start with a normalized schema and introduce denormalization in specific areas where performance becomes a concern. This allows systems to maintain consistency while optimizing critical queries.
Try Exasol Personal for Free
Run real workloads at full Exasol performance.
FAQs
Normalization stores data in separate, related tables to reduce redundancy and maintain consistency. Denormalization stores related data together, even if it introduces duplication, to simplify queries and improve read performance.
- 1NF (First Normal Form): Each column contains atomic values, and each row is uniquely identifiable.
- 2NF (Second Normal Form): In tables with composite keys, all non-key attributes depend on the entire primary key.
- 3NF (Third Normal Form): Non-key attributes depend only on the primary key, not on other non-key attributes, which removes transitive dependencies.
A common example is storing customer details directly in an orders table instead of referencing a separate customers table. This removes the need for joins when retrieving order data but duplicates customer information across multiple rows.
Yes. Denormalization is useful in read-heavy systems where query performance is critical. It is often applied selectively to reduce join complexity and improve response times, especially in analytics and reporting workloads.
Data warehouses are typically denormalized. They often use structures like star or snowflake schemas to optimize query performance for analytical workloads, where fast reads are more important than minimizing redundancy.
OLTP systems are usually normalized. They prioritize data integrity and consistent updates, which requires storing data in structured, related tables with minimal redundancy.
The three most commonly referenced forms are:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
These represent progressive steps in reducing redundancy and improving data structure.
Normalization organizes data within a database to reduce redundancy and maintain consistency. Validation checks whether data meets specific rules or constraints, such as format, range, or required fields.