
Database vs Data Warehouse: Key Differences, Use Cases, and Best Practices

Databases and data warehouses play different roles in how organizations manage and analyze information. A database handles day-to-day transactions and operational data; every order, payment, or log entry. A data warehouse aggregates large volumes of historical data from multiple sources to support analytics, reporting, and machine-learning workloads.
Knowing the difference helps teams choose the right system for speed, scalability, and analytical depth. This article explains how databases and data warehouses differ in architecture, performance, and use cases, and when each delivers the most value.
For comparisons with data lakes, take a look at our guide on data warehouse vs data lake.
What Is a Database?
A database is a structured system designed to store and manage current operational data. It supports day-to-day business transactions: processing orders, recording payments, updating inventory, or logging user activity. Most enterprise databases follow the OLTP (Online Transaction Processing) model, optimized for frequent writes and quick lookups rather than large-scale analytics.
Databases use row-oriented storage, meaning data is stored record by record. This layout speeds up insert and update operations but limits performance for analytical queries that scan millions of rows. Typical examples include PostgreSQL, MySQL, Oracle Database, Microsoft SQL Server, and Exasol Analytics Engine.
In a modern stack, a database forms the operational layer that keeps applications running in real time. Its data later flows into analytical systems (such as a data warehouse) for historical reporting and trend analysis.
Every organization needs both: a system to record what’s happening right now, and a system to understand what happened over time. Databases keep the business running; data warehouses explain why it runs the way it does.
Dirk Beerbohm, Global Partner Solution Architect, Exasol
What Is a Data Warehouse?
A data warehouse is a centralized system built for analytics, not transactions. It consolidates data from multiple operational databases, applications, and external sources into a unified model optimized for querying, reporting, and long-term analysis.
Unlike an OLTP database, a data warehouse follows the OLAP (Online Analytical Processing) paradigm. It is optimized for reads, complex aggregations, and multi-dimensional analysis across millions or billions of records. Data is stored in columnar format, which allows analytical engines to scan only the relevant attributes needed for a query (dramatically improving performance for BI and AI workloads).
Data warehouses typically apply a schema-on-write approach, enforcing consistent structures (dimensions, facts, and hierarchies) before loading data. Examples include Exasol Data Warehouse, Snowflake, Google BigQuery, and Amazon Redshift.
In enterprise environments, the data warehouse acts as the analytical layer, turning raw operational data into insights used for decision-making, forecasting, and compliance reporting.

Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
Data Warehouse vs Database: Core Comparison
The difference between a database and a data warehouse lies in their purpose, structure, and how they process data. A database supports real-time operations; a data warehouse enables historical analysis and strategic insight.
A data warehouse stores integrated, historical, and often aggregated data from many systems. It is optimized for analytical queries that read large datasets.
A database, by contrast, manages current operational data for fast insert and update transactions. Their differences become clearer when viewed within the overall data warehouse architecture (how data flows, transforms, and scales across systems).
Both store structured data, but with different goals:
- Database (OLTP): real-time, row-based, normalized schema, high write frequency.
- Data Warehouse (OLAP): read-heavy, columnar, denormalized schema, complex joins and aggregations.
Here is a quick table overview with key differences:
| Aspect | Database (OLTP) | Data Warehouse (OLAP) |
|---|---|---|
| Primary purpose | Run daily business operations | Analyze historical data |
| Data scope | Current, transactional | Historical, integrated |
| Query type | Short, frequent reads/writes | Long, analytical scans |
| Schema | Normalized (3NF) | Denormalized (star/snowflake) |
| Storage | Row-based | Columnar |
| Performance focus | Write and concurrency | Aggregation speed |
| Users | Developers, apps | Analysts, BI tools |
| Example systems | PostgreSQL, MySQL | Exasol, Snowflake |
These differences explain why most organizations use both: databases to operate the business, and data warehouses to understand and optimize it.
Difference Between Data Warehouse and Database Management System (DBMS)
A Database Management System (DBMS) is the software layer that allows users and applications to create, read, update, and delete data within a database (so the two are related, but not identical). Think of it like this: the database is the content; the DBMS is the tool that manages the content.
It handles indexing, query parsing, transaction management, and data integrity. Examples include MySQL, PostgreSQL, SQL Server, and Oracle Database. (Note: Most practitioners and vendors use “database” loosely to refer to both the software and the stored data.)
A data warehouse, however, is not just a DBMS. It’s a complete analytical environment built on top of or alongside one or more databases. It integrates data from multiple DBMSs, applies transformations, and stores the results in a structure designed for analytics.
| Feature | DBMS | Data Warehouse |
|---|---|---|
| Purpose | Manage operational data transactions | Integrate and analyze large historical datasets |
| Optimization | ACID compliance, concurrency | Query speed, aggregation, scalability |
| Data source | Single application or domain | Many heterogeneous sources |
| Processing model | OLTP | OLAP |
Modern Architectures
In a modern stack, databases and data warehouses are complementary components, not alternatives. Operational systems record transactions in real time, while analytical systems use that data to reveal patterns and performance over time.
Data usually flows from multiple databases into a staging or integration layer, where it is transformed, validated, and loaded into the data warehouse. This separation keeps day-to-day applications fast and reliable while giving analysts consistent, query-ready data.
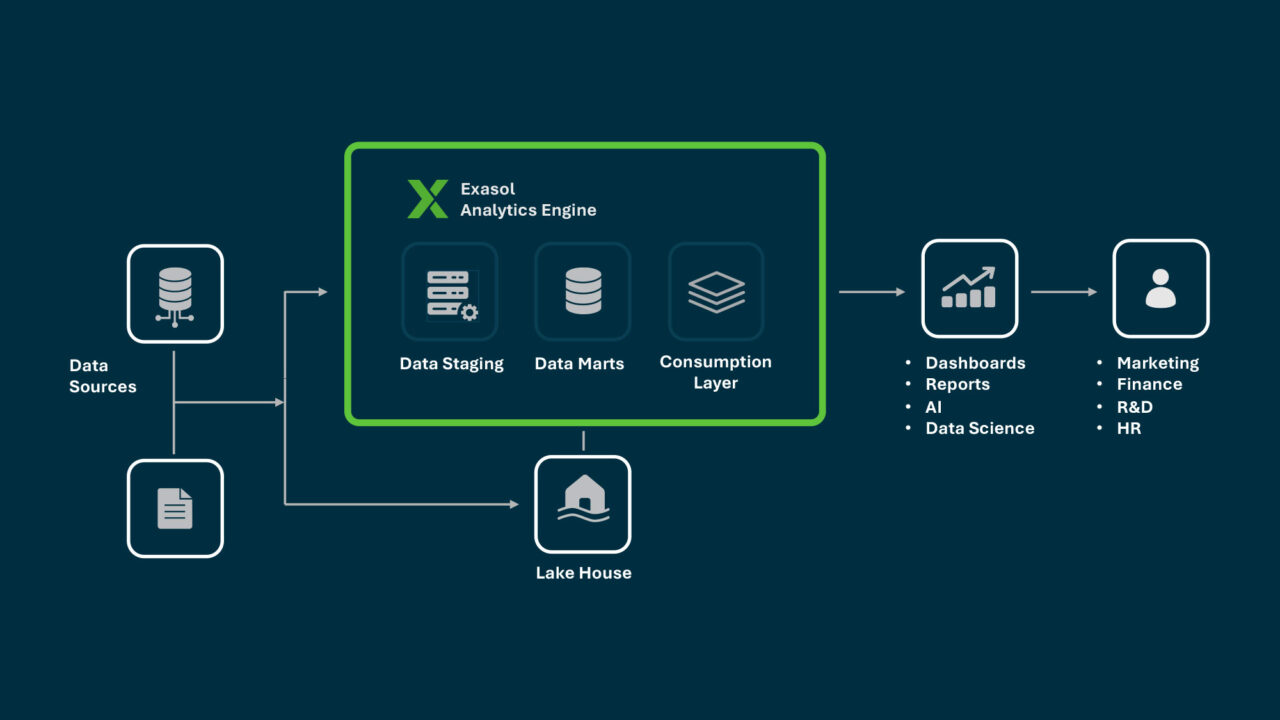
Common patterns include:
- Change Data Capture (CDC) or streaming pipelines to replicate updates.
- ELT workflows where raw data lands in the data warehouse and transformations happen inside it.
- Hybrid architectures that allow both layers to share metadata and governance.
Together, these systems form the backbone of a scalable analytics environment, later extended with unstructured layers. For a practical overview of how this integration works, see our guide on data warehouse integration.
Specialized Comparisons
While the core distinction between a database and a data warehouse is clear, many users look for more specific contrasts, highlighting how analytical workloads diverge from everyday operations.
Relational Database vs Data Warehouse
A relational database organizes data into normalized tables with strict relationships. This structure ensures data consistency and supports complex joins for transactional applications. It’s ideal when you need strong referential integrity and real-time updates, such as in e-commerce systems or ERP modules.
A data warehouse, by contrast, denormalizes data into fact and dimension tables to speed up analytical queries. Instead of minimizing redundancy, it optimizes for fast scans, aggregations, and cross-domain reporting. This shift from normalization to performance tuning is what makes a data warehouse suitable for business intelligence and forecasting.
Transactional Database vs Data Warehouse
A transactional database follows the OLTP model: many small, concurrent operations like inserts, updates, and deletes. Performance is measured in milliseconds and consistency is guaranteed through ACID transactions.
A data warehouse uses the OLAP model, designed for fewer but heavier read operations. It processes large-scale aggregations across millions of rows and can run complex analytical queries without affecting front-end systems.
In short: OLTP keeps the business running; OLAP helps improve how it runs.
Real-World Examples
Real implementations show why separating operational databases from analytical data warehouses matters.
bank99
The Austrian bank built a unified analytics platform on Exasol to replace fragmented reporting databases. By consolidating transactional data from multiple banking systems into a single data warehouse, the team gained consistent metrics for compliance and performance tracking. Analytical queries that once required manual extracts now run in seconds, enabling near real-time insights without slowing operational databases.
Companies like bank99 illustrate how modern enterprise data warehouses replace fragmented reporting databases with unified analytics platforms.
Spread Group
The e-commerce company moved from application-centric reporting to a dedicated data warehouse built on Exasol. This shift allowed them to analyze millions of customer and product records for personalization, forecasting, and logistics optimization, tasks that were impractical in their transactional systems.
C.H. Beck
The publisher used Exasol to accelerate large SQL queries, reducing execution times from minutes to seconds. Their editorial and finance teams now run analytics directly on integrated data, separating operational workloads from analysis without maintaining multiple copies of data.
Together, these examples show how organizations outgrow conventional databases and adopt data warehouses to handle scale, concurrency, and advanced analytics.
Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
Performance and Optimization
Performance is one of the clearest dividing lines between a database and a data warehouse. Both manage structured data, but they are tuned for very different workloads.
A transactional database focuses on speed per transaction, processing thousands of small operations per second while keeping latency in the millisecond range. Its optimization centers on indexes, caching, and concurrency controls that protect data integrity during inserts and updates.
A data warehouse, on the other hand, maximizes throughput per query. It’s designed for heavy analytical workloads that scan large volumes of data at once. Columnar storage, compression, and distributed processing (MPP) enable faster aggregations, joins, and reporting.
When query workloads shift from operational systems into a dedicated analytical engine, latency drops and teams gain freedom to iterate. That’s the real advantage of a purpose-built data warehouse: scalability without affecting production.
Florian Wenzel, VP of Product, Exasol
Benchmarks from Exasol deployments, such as bank99 and C.H. Beck (see above), show query times reduced from minutes to seconds once analytics moved from transactional databases to Exasol’s data warehouse engine. This separation ensures that front-end systems remain responsive while analysts run complex queries freely.
Performance tuning in modern data stacks typically involves:
- Parallel query execution across nodes for massive datasets.
- Adaptive caching that prioritizes frequently queried dimensions.
- Workload management to isolate analytical users from operational ones.
The result is a system that scales horizontally, maintains low latency for operations, and delivers analytical results fast enough for AI, forecasting, and real-time dashboards.
When to Use Each
Choosing between a database and a data warehouse depends on the workload, data volume, and business objective. Most enterprises use both—each optimized for a different phase of the data lifecycle.
When to Use a Database
Use a database when you need to:
- Power transactional systems such as e-commerce platforms, banking apps, or CRM tools.
- Handle frequent inserts, updates, and deletes in real time.
- Guarantee strict consistency and immediate feedback for users.
- Store only current operational data, not long-term history.
A relational database is ideal for OLTP workloads that prioritize integrity, availability, and concurrency.
When to Use a Data Warehouse
Use a data warehouse when you need to:
- Analyze large volumes of data collected over time.
- Combine multiple sources for unified reporting and BI.
- Run complex aggregations, joins, and machine learning workloads.
- Separate analytical queries from production systems to prevent performance impact.
A data warehouse is best for OLAP workloads that focus on trends, patterns, and decisions rather than transactions.
When to Use Both
In practice, most organizations integrate both layers. Data flows from operational databases into the data warehouse via ETL or streaming pipelines. This hybrid approach delivers fast transactions and deep analytics without compromising either.
Final Thoughts
A database and a data warehouse serve different but complementary purposes in the data ecosystem. The database keeps daily operations running: recording every order, payment, and interaction in real time. The data warehouse turns that information into long-term insight, revealing trends, performance gaps, and opportunities.
Enterprises rarely choose one over the other. They build systems where databases feed the data warehouse, creating a reliable flow from operations to analytics. This separation improves both performance and decision-making: transactions stay fast, and analysis becomes scalable.
As data volumes and AI workloads grow, the line between the two systems keeps shifting. What remains constant is the need for clear architecture and governance, using each tool for what it does best.
Frequently Asked Questions
Microsoft SQL Server is a database management system. It can function as a database for transactions or, with SQL Server Analysis Services (SSAS), as part of a data warehouse for analytics. Its role depends on how it is implemented within the data architecture.
The main database types are:
-Relational databases (e.g., PostgreSQL, Oracle, Exasol)
-NoSQL databases (e.g., MongoDB)
-Object-oriented databases
-Distributed or cloud databases
Each serves different workloads, from structured transactions to large-scale or semi-structured data processing. Note: Exasol belongs to the relational category but is optimized for analytical performance, bridging traditional database and data warehouse capabilities.
Data is raw information; numbers, text, or records. A database is the structured system used to store, organize, and retrieve that data efficiently, often managed by a DBMS such as MySQL or SQL Server.
No. SQL (Structured Query Language) is a programming language used to query and manage databases. It isn’t a database itself but the standard interface for interacting with both transactional databases and data warehouses.
The key difference is workload type. Databases are optimized for OLTP (many small read/write operations). Data warehouses are optimized for OLAP (fewer, large analytical queries) that summarize or aggregate data across time and sources.
A transactional database processes continuous operational updates: orders, payments, or sensor data. A data warehouse consolidates that information from multiple systems to enable complex queries, historical reporting, and predictive analytics without affecting operational performance.
An operational database manages current business data used by applications. A data warehouse stores aggregated, cleaned, and historical data for analytics. The operational system runs the business; the data warehouse helps analyze and improve it.
A relational database stores structured data in normalized tables for consistent, transactional access. A data warehouse denormalizes and aggregates data to speed up analytical queries across large datasets, often integrating information from multiple relational systems.
A data warehouse is built for analytics. It can query and join massive datasets from multiple sources efficiently, without slowing down production systems. This makes it ideal for business intelligence, reporting, and advanced analytics.
“Better” depends on purpose. A data warehouse outperforms a standard database for analytical workloads (aggregating, comparing, and visualizing large data volumes). However, a database is better for real-time transactional processing. Most enterprises use both together.