Data Lake vs Data Warehouse: Full Comparison Guide

A data lake stores raw, unstructured data at scale, ideal for machine learning and real-time ingestion. A data warehouse, in contrast, stores cleaned, structured data optimized for fast querying and business intelligence.
In recent years, with rising demands for AI-ready pipelines, cost-efficient storage, and real-time analytics, understanding the difference between these architectures is more important than ever.
This guide compares the two head-to-head, covering everything from architecture and schema design to performance, scalability, and real-world use cases.
By the end, you’ll understand:
- What each solution is designed for
- How they differ in structure, cost, and speed
- When to use one over the other—or both together
What Is a Data Lake?
A data lake is a centralized storage system designed to hold vast amounts of raw, unstructured, or semi-structured data—from logs and sensor streams to images and text. Unlike traditional databases, data lakes use a schema-on-read approach, meaning the structure is applied only when the data is queried, not when it’s stored. This makes them flexible and ideal for storing diverse data types at scale.
Data lakes are commonly used for machine learning, real-time analytics, and big data pipelines where speed of ingestion and storage cost efficiency are top priorities. Popular tools that support data lakes include Amazon S3, Azure Data Lake Storage (ADLS), and Hadoop Distributed File System (HDFS). Data stored in lakes is typically accessed through processing engines like Apache Spark, Presto, or Flink.
What Is a Data Warehouse?
A data warehouse is a centralized repository designed to store structured and curated data for business intelligence, reporting, and analytics. Unlike data lakes, it uses a schema-on-write model—meaning the data must be cleaned, transformed, and modeled before it enters the system. This makes querying fast and reliable, especially for standard SQL-based analytics. In enterprise environments, the conversation often becomes data lake vs EDW (Enterprise Data Warehouse), where the EDW emphasizes governed, SQL-ready analytics while data lakes offer flexibility at scale, or towards a modern data warehouse if governance, performance, and hybrid flexibility are priorities.
Data warehouses are optimized for complex queries, dashboarding, and historical trend analysis. They’re commonly used by analysts, finance teams, and business users who need consistent, high-quality data.
Not familiar with the basics? Here’s a quick primer on data warehouse concepts to get you started.
While cloud-native options like Snowflake, Amazon Redshift, Google BigQuery, and Azure Synapse are widely adopted today, many organizations also operate on-premises data warehouses using platforms like Exasol, often for compliance, security, or legacy integration reasons. For example, SQL Data Warehouse in SQL Server
remains a choice for those heavily invested in Microsoft technologies.”
Cloud or on-prem, the goal is the same: fast, governed access to high-quality data for decision-making.
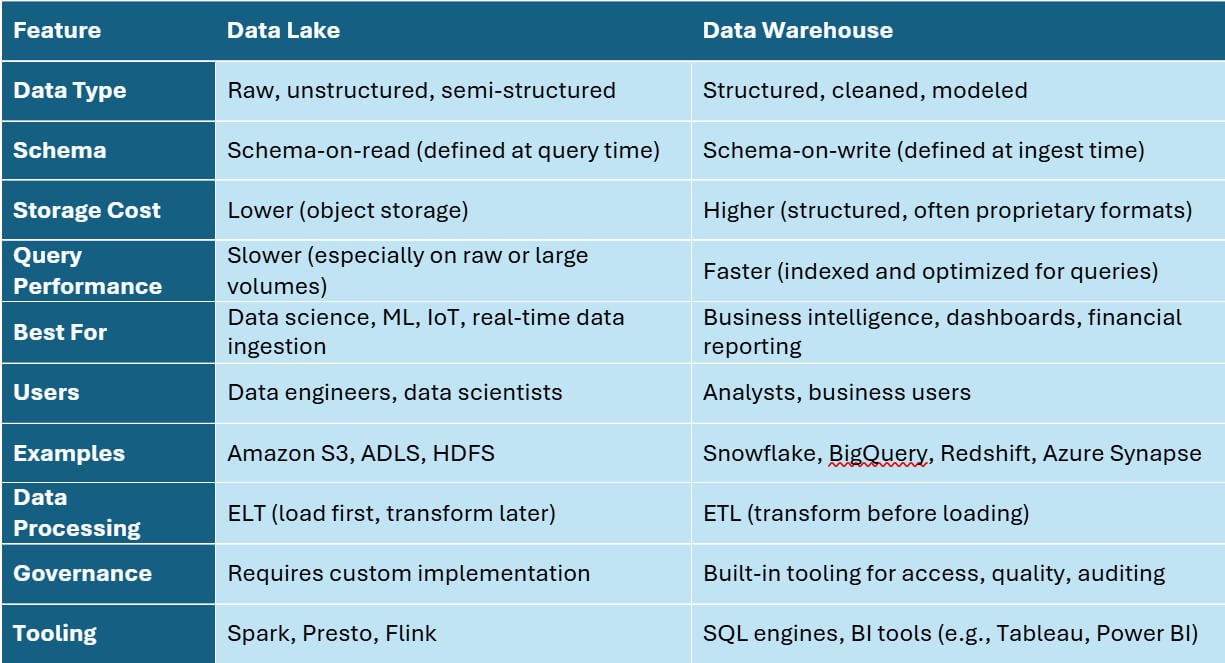
Key Differences Between Data Lakes and Data Warehouses
Whether you’re evaluating data lake vs warehouse from a cost, performance, or scalability standpoint, this comparison table outlines the key differences. The table below highlights the most important distinctions across structure, performance, cost, and use cases:
Architecture Breakdown
The architectural differences between data lakes and data warehouses go far beyond how they store data. Each system is built for a distinct purpose—one for flexible storage at scale, the other for fast, structured analytics. Here’s a simplified view of how each system is typically structured from ingestion to access:
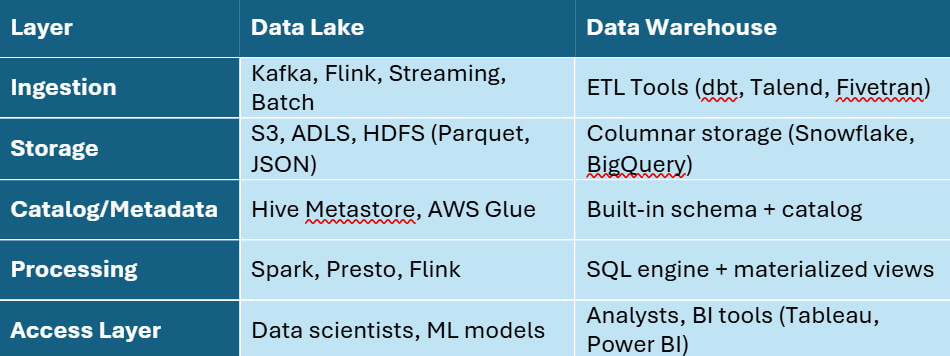
Below is a breakdown of how both architectures typically work.
Data Lake Architecture
A data lake ingests data in its raw form—structured, semi-structured, or unstructured—into low-cost object storage. There’s no need to define a schema before loading, making it ideal for collecting large volumes of diverse data.
Typical layers in a data lake:
- Ingestion: Streams or batches of data enter via Kafka, Flink, or direct pipelines.
- Storage: Data is saved in formats like JSON, columnar file structures, or Avro using tools like Amazon S3 or ADLS.
- Catalog & Metadata: Tools like Apache Hive, AWS Glue, or Unity Catalog index the data.
- Processing: Query engines like Spark or Presto transform or analyze data on demand.
This architecture supports schema-on-read, allowing analysts or ML models to interpret the structure during query time.
Data Warehouse Architecture
In contrast, a data warehouse requires data to be cleaned and structured before it enters the system. This is known as schema-on-write. The architecture is optimized for performance, consistency, and fast SQL analytics. For a deeper look at how modern data warehouses are structured, explore our guide to data warehouse architecture.
Typical layers in a data warehouse:
- ETL Pipeline: Data is extracted from source systems, transformed (normalized, cleansed), and loaded.
- Storage Engine: Uses columnar storage (e.g., BigQuery, Snowflake) to optimize query execution.
- Query Layer: SQL interface optimized for joins, aggregations, and filters.
- BI Tools: Connectors to tools like Tableau, Looker, or Power BI for visualization.
Data warehouses enforce governance, access control, and performance tuning—making them reliable for decision-critical workloads.
Too many companies build data infrastructure before they’ve mapped the lifecycle of their data. A lake, warehouse, or lakehouse only works when it aligns with how your team ingests, transforms, and activates data.
Alexander Stigsen, Chief Product Officer, Exasol
When to Use Each: Data Lake vs Data Warehouse
Choosing between a data lake and a data warehouse depends on your goals, data types, processing needs, and end users. Here’s how to decide which fits best—or when to use both together.
When to Use a Data Lake
Data lakes are ideal when:
- You need to store large volumes of raw data at low cost.
- You work with unstructured or semi-structured data (e.g., logs, video, sensor streams).
- You’re building machine learning pipelines, data science notebooks, or AI workloads.
- Your team prefers flexible schema or real-time ingestion from streaming sources.
Example: A retail company streams clickstream and app events into a data lake for ML-driven customer behavior modeling.
When to Use a Data Warehouse
Data warehouses are the right fit when:
- You need clean, structured data for business intelligence and dashboards.
- You rely on standardized SQL queries, reporting tools, and compliance.
- You need fast query performance for historical trend analysis or KPI tracking.
- Your audience includes business analysts and non-technical users.
- You benefit from clear data warehouse models that help maintain schema consistency and support fast analytical queries
Example: A finance team loads monthly transactional data into a warehouse to generate P&L reports and executive dashboards.
To explore more, see our write‑up on the advantages of a data warehouse for cost, governance, and performance trade‑offs.”
When to Use Both Together
Many modern architectures combine both:
- Ingest raw data into a lake for flexibility.
- Clean and transform data into a warehouse for fast, governed access.
- Tools like dbt, Fivetran, or Apache Spark can bridge the two systems.
Example: A SaaS company stores product telemetry in a lake, then transforms it into a warehouse for churn analysis and cohort reporting. A classic data lake vs data warehouse example is a retail analytics stack: clickstream data is stored raw in a lake, while monthly sales reports are generated from structured warehouse tables.
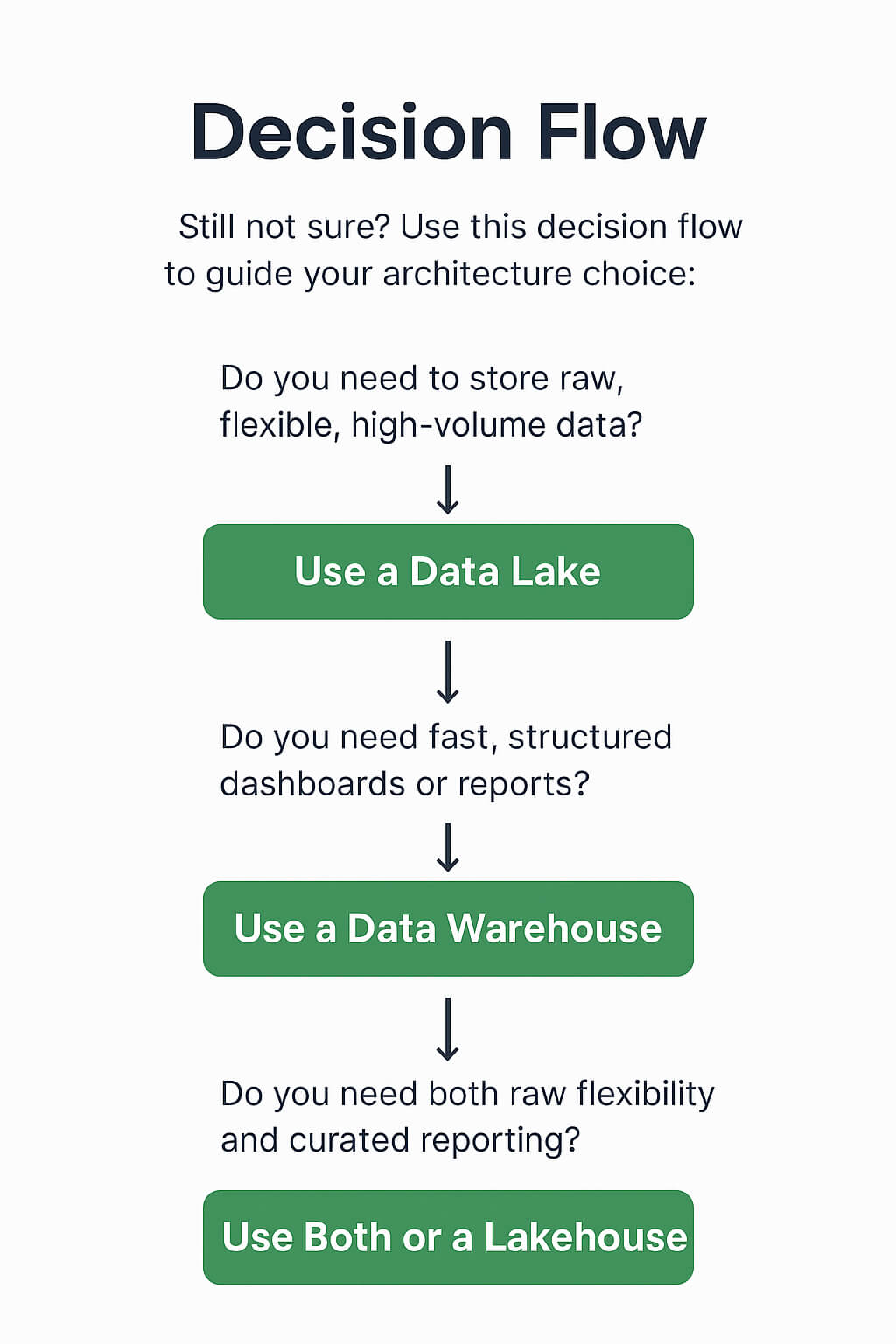
Use this decision flow to guide your architecture choice:
What About Data Lakehouse?
While this guide focuses on comparing data lakes and data warehouses, the lakehouse architecture has emerged as a powerful hybrid that addresses limitations in both.
A data lakehouse combines the flexibility and low-cost scalability of a data lake with the performance, structure, and governance of a data warehouse. It supports open table formats like Delta Lake, Apache Iceberg (query-friendly object tables), and Apache Hudi, and introduces features like catalogs, transactions, and observability that were missing in traditional lakes. When evaluating a data lakehouse vs data warehouse, the key differences lie in openness, flexibility, and the ability to serve both BI and AI use cases.
However, lakehouses also introduce complexity: integrating components across the stack, tuning performance, and achieving cost predictability remain challenges for many organizations.
That’s where Exasol’s Lakehouse Turbo comes in. It provides a zero-ETL, tuning-free, in-memory query engine that integrates seamlessly with data lakehouse stacks.
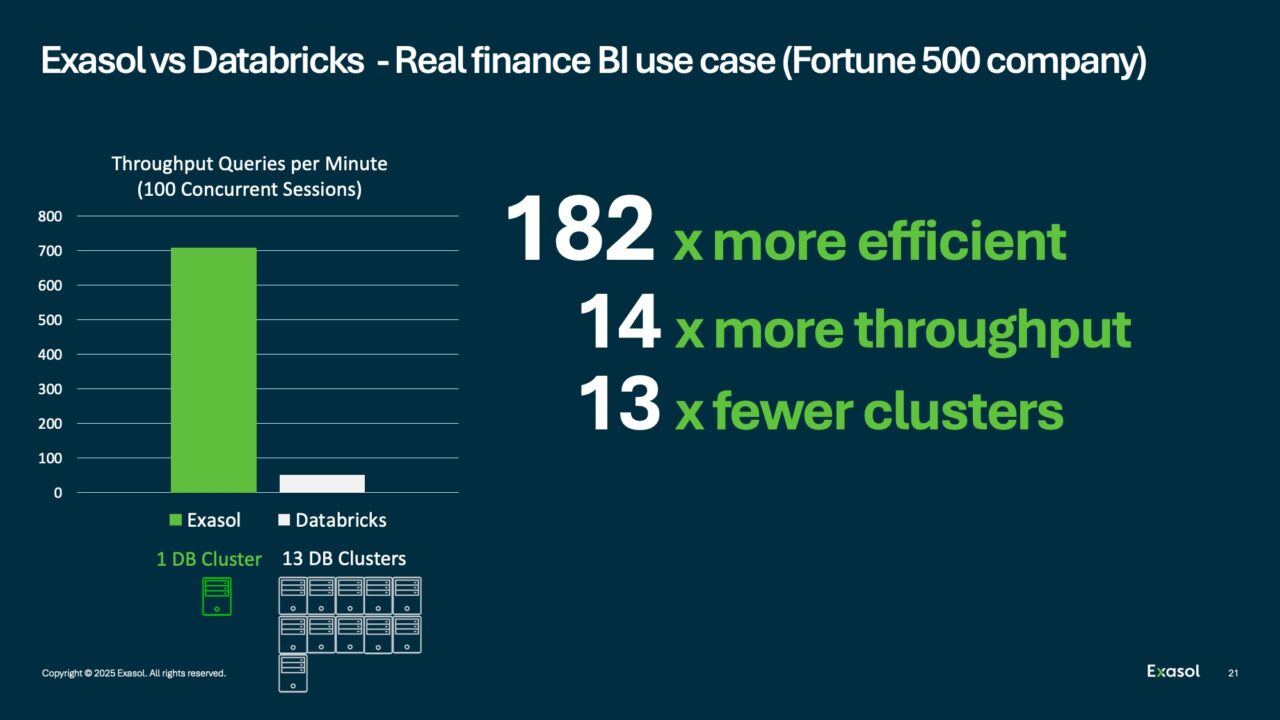
In real-world use cases, Exasol has shown up to 182x efficiency gains and 4x cost reduction compared to Databricks Photon — all with fewer clusters.
For a more detailed look at data warehouse vs data lake vs data lakehouse, including when to use each in practice, check out this deep dive on modern architectures.
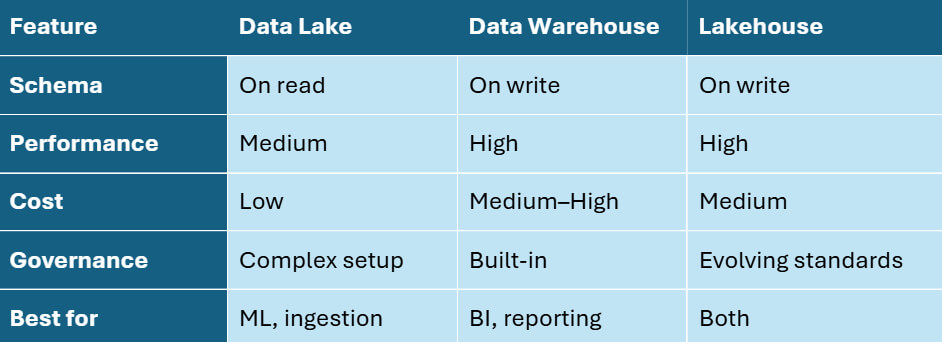
Decision Framework: Choosing the Right Architecture
If you’re comparing data warehouse vs data lake pros and cons, think beyond architecture—consider who will use the data, what format it comes in, and how fast it needs to be accessed. If you’re still unsure which approach to choose, the table below summarizes which architecture fits best depending on your priorities, data types, and analytics needs.
| If You Need… | Choose… |
|---|---|
| To store raw, diverse, large-scale data | Data Lake |
| To power dashboards, KPIs, financial reporting | Data Warehouse |
| Schema flexibility with semi/unstructured data | Data Lake |
| Fast SQL analytics and curated data | Data Warehouse |
| Cost-effective storage for logs, events, backups | Data Lake |
| Strict governance and access control | Data Warehouse |
| Machine learning and data science workflows | Data Lake |
| Out-of-the-box performance optimization | Data Warehouse |
| Real-time ingestion and streaming support | Data Lake (or Lakehouse) |
| Business user accessibility and BI integration | Data Warehouse |
Quick Tips:
- Start with a data lake if flexibility and scalability matter most.
- Start with a data warehouse if consistency, governance, and speed are top priorities.
- Use both when your stack needs to serve both data scientists and analysts—many modern data pipelines now combine the two.
Cost, Performance, and Governance
When comparing data lakes and data warehouses, it’s not just about architecture—it’s about how each system impacts budget, speed, and control.
Cost
Data lakes typically offer lower-cost storage by using object stores like S3 or ADLS. They’re ideal for storing large volumes of raw data—especially logs, telemetry, and historical backups—at a fraction of the price per gigabyte compared to structured systems.
Data warehouses charge more per GB due to performance-optimized formats, indexing, and compute integration. However, they often provide better cost-efficiency per query for structured, frequent analytics use cases—especially when paired with caching or clustering strategies.
The real cost difference lies in total ownership: data lakes are cheaper to store but often require more engineering effort.
Performance
Warehouses are optimized for fast SQL queries, aggregations, and dashboards. Columnar storage, query caching, and indexing deliver sub-second response times.
Lakes, using engines like Spark or Presto, can query large raw datasets, but performance can lag—especially with nested or uncleaned data.
Lakehouses try to bridge this gap by enabling faster querying on raw data through ACID-compliant table formats like Delta Lake or Apache Iceberg.
Governance & Access Control
Data warehouses typically come with built-in governance features: role-based access control (RBAC), audit logs, encryption, and compliance tooling.
Data lakes often require assembling custom governance layers (e.g., Glue Catalog, Apache Ranger) to enforce data quality, permissions, and lineage.
If regulatory compliance, auditability, or fine-grained data access is critical to your organization, a warehouse—or a well-integrated lakehouse—will likely be easier to manage securely.
Real-World Examples
Understanding when and how to use data lakes or data warehouses becomes clearer when you look at real customer scenarios. Here are a few real-world examples that illustrate different architecture decisions and their outcomes.
Piedmont Healthcare – Scaling Clinical Dashboards with a Warehouse
Piedmont Healthcare was processing 1.8 trillion data points, but their legacy system couldn’t keep up. Dashboards took 10+ minutes to load, slowing down decision-making across clinical, operational, and financial teams.
By switching to Exasol’s data warehouse engine, they achieved:
- Sub-second dashboard refreshes
- Reliable reporting across 11 hospitals
- Scalable analytics that now supports their full operational pipeline
Why warehouse? Curated, high-quality data, served fast to BI tools for executive and clinical users.
Monsoon Accessorize – Moving Retail Reports from Hours to Minutes
UK fashion brand Monsoon was running daily reports on Oracle that took 18 hours—blocking decision-making and slowing inventory and marketing workflows.
After adopting Exasol’s data warehouse:
- Reports now run in minutes, not hours
- Teams gained real-time visibility into stock, sales, and customer behavior
Why warehouse? Speed and consistency for business-critical reports used across departments.
Cineplexx – High-Speed Reporting Across 500+ Screens
Operating across multiple countries, Cineplexx needed real-time visibility into ticket sales, staffing, and show scheduling. Their legacy systems couldn’t keep up with modern reporting demands.
By adopting Exasol as their centralized data warehouse:
- Reports are refreshed every 15 minutes
- Stakeholders access up-to-date data for scheduling, staffing, and customer experience
Why warehouse? Reliable, high-speed reporting to support operational decisions across a distributed business.
These examples show how organizations across industries—healthcare, retail, insurance, entertainment—choose data warehouses when they need structured, governed, and high-performance analytics. In some cases, they evolve toward hybrid or lakehouse architectures as their data maturity grows. Whether the goal is real-time dashboards, cost-efficient reporting, or future-ready AI pipelines, the right architecture delivers measurable impact—faster insights, reduced costs, and scalable decision-making.
Summary: Data Lake or Data Warehouse — Which Is Right for You?
The choice between a data lake vs data warehouse setup depends on your data types, users, and business goals.
Choose a data lake when flexibility, cost-efficient storage, and support for diverse or unstructured data are essential.
Choose a data warehouse when you need fast, reliable access to curated data for business reporting, dashboards, and compliance.
Use both when you want the best of both worlds—raw data at scale and fast insights for decision-makers.
And if you’re exploring modern solutions that combine both approaches, consider the emerging role of the data lakehouse.
Frequently Asked Questions
A data warehouse stores cleaned, structured data optimized for fast querying and analytics. A data lake stores raw, unstructured or semi-structured data, allowing for flexible ingestion at scale. Warehouses are ideal for BI and dashboards, while lakes are used for data science and machine learning.
Databricks offers a lakehouse platform—a hybrid that combines the scalability of data lakes with the performance and governance of warehouses. It supports open formats like Delta Lake and provides a SQL interface.
In an ETL (Extract, Transform, Load) process, a data lake often serves as the landing zone for raw data before transformation. It’s commonly used in modern data ingestion pipelines like ETL, where data is first loaded into the lake and then transformed for downstream systems.
Hadoop is a foundational technology often used to build data lakes. It supports distributed storage and processing of large, unstructured datasets. Hadoop is not a data warehouse—it lacks the schema enforcement and performance tuning typical of warehouse systems.
EDW stands for Enterprise Data Warehouse—a centralized, structured data platform for analytics. A data lake, in contrast, is a more flexible repository designed for raw and diverse data formats. Many enterprises now use both together in modern architectures.
Google BigQuery is a cloud data warehouse. It’s designed for fast SQL-based analytics on structured data and supports high-performance reporting, not unstructured raw data storage like a data lake.
A database is typically used for transactional workloads (OLTP), with strict schemas and row-level operations. A data lake is optimized for analytical workloads, storing massive amounts of data in various formats with loose schema constraints.
Snowflake is primarily a cloud data warehouse, but it has added features that mimic lakehouse functionality—like external table access and support for semi-structured formats. However, it’s not a true data lake or open lakehouse platform.
“Data space” is a broader concept referring to distributed, interoperable data environments (often in data mesh or data sharing contexts). A data lake is a physical repository used to store large volumes of raw data.