
Data Warehouse Testing: Strategy, Tools & Real-World Examples

Data warehouse testing validates that data moving from source systems into the warehouse is complete, consistent, and usable. The scope extends beyond ETL jobs: it checks transformations, loading processes, metadata, and business reports. DWH testing is often used as shorthand for this process, but in practice it covers multiple layers, from raw ingestion to reporting.
A solid testing strategy depends on the underlying data warehouse architecture, since schema design, storage models, and integration points define what must be validated.
Why testing matters in the bigger analytics lifecycle, you might ask. As data warehouses become core to analytics and compliance, testing ensures they deliver reliable outputs rather than hidden risks.
What is Data Warehouse Testing?
Data warehouse testing is the process of validating that the data in a data warehouse is consistent, reliable, and aligned with business rules. These checks form a continuation of the work done when building a data warehouse, ensuring that design decisions translate into reliable outcomes.
It typically covers:
- Source validation – checking that all required data from operational systems is captured.
- Transformation verification – confirming that business rules, aggregations, and joins are applied correctly.
- Load validation – ensuring data is loaded without loss or duplication.
- Reporting validation – confirming BI dashboards and reports display accurate results.
Example SQL check for completeness:
-- Compare row counts between source and warehouse
SELECT COUNT(*) FROM source_table;
SELECT COUNT(*) FROM warehouse_table;This returns the total row count in each table. It’s a valid first-level data completeness check when testing a data warehouse load. If the counts don’t match, you likely have missing or extra rows.
Important note: Row counts alone don’t confirm correctness of the data. Two tables can have the same number of rows but still contain mismatched values. That’s why this check is usually combined with aggregate comparisons (SUM, MIN, MAX) or row-level sampling.
Why Data Warehouse Testing Matters
Data warehouses underpin pricing, forecasting, compliance, and executive reporting. If the data warehouse holds incomplete or incorrect data, decisions and regulatory filings inherit those errors.
Testing matters because it reduces risk at several points:
- Data accuracy — verifies that transformations preserve business logic.
- Completeness — ensures no records are lost during extraction, staging, or loading.
- Consistency — detects discrepancies across multiple data sources.
- Performance — validates that queries run within acceptable response times under production workloads.
- Compliance — provides audit trails to demonstrate that reported values align with governed business rules.
Without these checks, errors often surface late (in BI dashboards or financial reports, e.g.) when remediation is costly and reputational damage is already done.
Testing reduces risk not only by preventing data loss or duplication but also by safeguarding performance. At scale, validation must confirm that workloads run efficiently, which directly ties to analytics acceleration.
In regulated industries, testing also supports audit readiness across an enterprise data warehouse environment.

Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Common Data Warehouse Testing Types
Each test type targets a specific failure mode. Covering them ensures the data warehouse is both correct and usable at scale.
Metadata testing
It validates schema structure, column data types, and constraints. A common check is verifying that a target column allows the same precision as the source, especially when working with different data warehouse models such as Data Vault or anchor modeling, where schema flexibility can introduce errors if not validated.
Data completeness testing
It confirms that all rows and columns are transferred. If numbers differ, rows are missing or duplicated in the data warehouse.
-- Check completeness by comparing row counts
SELECT COUNT(*) FROM source_table;
SELECT COUNT(*) FROM warehouse_table;Note: It does not prove values match, just that counts are equal. Needs to be combined with checksum or aggregate tests.
Data quality testing
It detects nulls, duplicates, or out-of-range values. Groups by the key column and returns only those with more than one record, i.e. duplicates.
-- Identify duplicate primary keys
SELECT key_column, COUNT(*)
FROM warehouse_table
GROUP BY key_column
HAVING COUNT(*) > 1;Note: Only works if you know the intended unique key (e.g., customer_id). If no PK is defined, you must choose the natural key(s).
Transformation testing
It ensures business rules and joins produce correct outputs. Example: verifying that calculated revenue equals quantity × price. If values differ, transformation logic is wrong or loading introduced errors.
-- Validate revenue calculation
SELECT SUM(quantity * price) AS expected, SUM(revenue) AS stored
FROM warehouse_table;Note: Works only if the stored column is supposed to equal quantity * price. If business logic differs (discounts, tax), the query must adapt.
Incremental load testing
It checks that only new or changed records are loaded during delta loads. Indicates duplicates or bad delta logic.
-- Check for records in the warehouse that are not in the source since last load
SELECT w.id
FROM warehouse_table w
LEFT JOIN source_table s
ON w.id = s.id
WHERE s.id IS NULL
AND w.load_date >= CURRENT_DATE;Note: Requires a reliable load_date or last_updated column. If source deletes are not tracked, missing records could be flagged incorrectly.
Regression testing
It verifies that new changes do not break existing queries or reports (runs the same aggregate query used in production and compares results against a baseline snapshot stored from earlier runs).
-- Compare current warehouse aggregates with a known baseline
SELECT SUM(order_total)
FROM warehouse_table
WHERE order_date BETWEEN '2024-01-01' AND '2024-12-31';Note: SQL by itself doesn’t store historical baselines; you must persist results in a separate table or file. Any intentional changes to business logic (e.g., new rules) can cause false positives if baseline isn’t updated.
Performance testing
Correct data is not enough if queries take minutes or fail under load. Performance and scalability testing measure whether the data warehouse can sustain production volumes and concurrency.
Common checks include:
- Query execution time — measure how long key workloads run.
-- Example in PostgreSQL: analyze query performance
EXPLAIN ANALYZE
SELECT customer_id, SUM(order_total)
FROM warehouse_table
GROUP BY customer_id;EXPLAIN ANALYZE returns both the query plan and actual runtime. Useful for spotting slow joins or missing indexes.
- Load benchmarks — test how long it takes to ingest millions or billions of rows. Track throughput in rows per second and compare against targets.
- Concurrency tests — run multiple queries at once to simulate real usage. Tools like JMeter or Locust generate simultaneous sessions.
- Resource monitoring — capture CPU, memory, and I/O usage during tests. A query that runs fast in isolation but saturates memory under concurrency will fail in production.
Limitations:
- SQL-level checks show single-query performance only; concurrency and system load require external tools.
- Benchmarks are system-specific. Results in PostgreSQL, Snowflake, or Exasol differ by architecture.
BI and Report Validation
A data warehouse may store correct data but still produce incorrect dashboards if report logic drifts from the data warehouse layer. BI and report validation ensures alignment between source queries and what end users see.
Typical checks:
- Aggregate comparison — verify totals in BI dashboards match data warehouse aggregates.
-- Compare revenue totals
SELECT SUM(revenue) FROM warehouse_table;Then compare the output to the BI report’s displayed value.
- Filter validation — test that report filters apply the same conditions as the SQL layer (e.g., date ranges, customer segments).
- Drill-down checks — confirm that detail views in BI match row-level data in the data warehouse.
Limitations:
- Requires access to both BI queries and data warehouse SQL.
- Automated validation is tool-dependent (Power BI, Tableau, Looker use different query engines).
Data Warehouse Testing Strategy (Step-by-Step)
A testing strategy defines how teams validate data quality from source to report. Without structure, testing becomes inconsistent and results are hard to audit. A repeatable process keeps quality under control. The process typically follows seven steps:
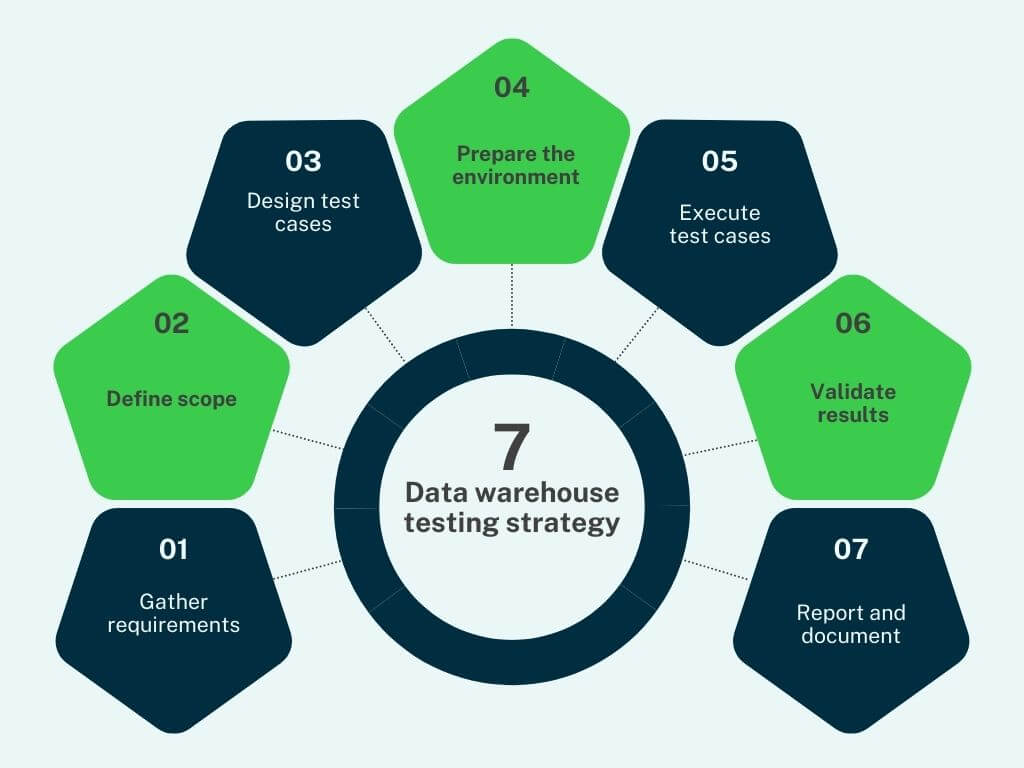
Gather requirements
- Identify business rules, reporting needs, and compliance obligations.
- Document expected record volumes and key metrics that must reconcile.
Define scope
- Specify which systems, transformations, and reports are in scope for testing.
- Distinguish between one-time migration tests and ongoing regression checks.
Design test cases
- Map each requirement to SQL checks or automated test scripts.
- Examples: row counts, referential integrity checks, transformation validations.
Prepare the environment
- Set up a test schema or staging area that mirrors production structure.
- Ensure controlled test data sets exist for repeatable runs.
Execute test cases
- Run SQL scripts or automated workflows against the data warehouse.
- Capture actual results in a log table for traceability.
Validate results
- Compare outcomes to expected values and investigate discrepancies.
- Prioritize defects by business impact, not only by volume.
Report and document
- Summarize results in audit logs and dashboards.
- Maintain historical test evidence for compliance or future regression.
Tools for Data Warehouse Testing
Testing at enterprise scale requires more than manual SQL scripts. Frameworks and platforms provide automation, scheduling, and reporting features that accelerate validation, but each has trade-offs. The table below shows a neutral comparison of commonly used options.
| Tool | Automation | Performance & Load | BI/Report Validation | Cost Model | Notes |
|---|---|---|---|---|---|
| Talend | Built-in test automation within ETL workflows | ⚠️ Limited load testing | ⚠️ Limited BI validation | Subscription | Primarily an ETL tool; testing is a secondary function. |
| QuerySurge | ✅ Strong test automation | ✅ Supports performance benchmarking | ✅ BI query validation (Tableau, Qlik, Power BI) | License | Purpose-built for data testing with vendor support. |
| iCEDQ | ✅ Automated regression testing | ⚠️ Limited | ⚠️ Limited BI validation | Subscription | Focused on ETL and pipeline testing. |
| Datagaps | ✅ ETL and migration test automation | ⚠️ Limited | ⚠️ Limited BI validation | Subscription | Vendor positions around “end-to-end validation.” |
| Open source (dtb tests, Great Expectations) | ✅ Customizable with Python/SQL | ⚠️ Limited built-in load testing | ⚠️ BI validation requires custom code | Free | Flexible but requires engineering investment. |
| Exasol | ⚠️ No standalone framework; testing is SQL-driven | ✅ Optimized for high-performance query benchmarking | ⚠️ BI validation must be scripted manually | License | Not a testing tool, but in-memory design supports large-scale validation efficiently. |
Important notes:
- No single tool covers all testing needs.
- BI/report validation is rarely supported out of the box.
- Open-source options reduce license cost but shift effort to engineering teams.
- Exasol belongs here not as a framework, but as a system under test that can execute validation queries at scale.
Takeaway: Tool selection depends on team skill set, data volume, and compliance needs. Purpose-built frameworks reduce manual effort, while in-database platforms like Exasol make large-scale validation feasible.
Case Studies & Real-World Examples
Customer stories illustrate how testing, validation, and performance optimization play out in live environments. Each case comes from an Exasol deployment and shows measurable impact on reporting speed, data reliability, or cost efficiency.
Monsoon Accessorize
Why it matters: Long runtimes prevent timely retail decisions.
A global fashion retailer needed faster insights for merchandising and supply chain decisions. Legacy reporting processes took 18 hours, making daily stock management impractical. After moving workloads onto Exasol and validating completeness and transformation logic during migration, reporting runtimes dropped to minutes or seconds. This enabled near real-time inventory tracking and gave non-technical staff access to self-service BI dashboards.
Helsana
Why it matters: Large-scale data loads require predictable performance and lower costs.
As one of Switzerland’s largest health insurers, Helsana faced long data load cycles and high infrastructure costs. Testing uncovered inefficiencies in transformation and loading logic. By optimizing workloads in Exasol, query speeds improved by 5–10×, and data load time decreased from 26 hours to 4 hours. The company also reported a 65% reduction in license and maintenance costs within the first year.
Uno-X
Why it matters: Query delays limit BI adoption across teams.
This Nordic fuel company required timely dashboards for operational decisions. Prior to optimization, critical queries ran for 20+ minutes, limiting adoption of BI across teams. Validation of incremental loads and performance checks revealed bottlenecks in query design. After migrating to Exasol, dashboards ran in under 10 seconds, leading to higher adoption and broader use of analytics in daily operations.
Otto
Why it matters: Cost efficiency is a driver for e-commerce scale.
As one of Europe’s largest e-commerce platforms, Otto needed scalable analytics to serve a wide user base. Exasol was validated for both performance and integration with Hadoop and Tableau. The result was a 50% reduction in overall costs and faster reporting for thousands of concurrent users. Testing efforts ensured accuracy during integration while allowing large-volume workloads to run without delay.
Flaconi
Why it matters: Fast migrations demand reliable validation of data at scale.
Flaconi, a European beauty retailer, migrated its data warehouse to Exasol in six months. The system now manages ~3 TB of data and supports ~120 active report users. Testing during migration focused on completeness and transformation accuracy, ensuring reports were delivered each morning without error. This combination of data scale, reliability, and speed enabled timely decision-making in a competitive retail market.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Data Warehouse Testing Checklist
Testing can miss critical errors if steps are skipped. A checklist provides teams with a repeatable framework to confirm that all core areas are validated before a data warehouse goes live or a new load cycle is deployed.
10 essential checks before sign-off:
- Source-to-target counts match — verify row counts and key aggregates.
- No unexpected nulls — confirm mandatory fields are always populated.
- Duplicates controlled — run queries against unique keys to ensure no duplicates exist.
- Transformation rules verified — test business logic calculations (e.g., revenue, discounts).
- Incremental loads validated — check only new or changed rows are added.
- Regression tests executed — compare current results against baselines.
- Performance benchmarks met — confirm queries run within agreed response times.
- Concurrency tested — simulate multiple users accessing reports at the same time.
- BI dashboards reconciled — verify aggregates in reports match data warehouse SQL.
- Audit logs complete — ensure all test executions and results are documented.
Takeaway: A checklist does not replace detailed test planning, but it ensures that no critical area is overlooked. Making these checks part of every cycle builds confidence in both the data warehouse and the reports that depend on it.
Best Practices for Data Warehouse Testing
Data warehouses handle complex transformations, large volumes, and multiple reporting layers. Following consistent practices avoids wasted effort and ensures reliable outcomes.
Do’s:
- Validate simple checks first — row counts and aggregates catch many basic errors before deeper analysis.
- Automate regression tests — build repeatable queries or scripts to compare against baselines.
- Test incrementally — validate loads in small batches before scaling to full data volumes.
- Measure performance under load — include concurrency and stress tests, not just single-query benchmarks.
- Document everything — keep execution logs and expected outcomes for compliance and audit needs.
- Integrate testing into CI/CD pipelines — automate SQL checks and validation scripts so they run with each deployment. This reduces manual effort and ensures consistency across environments.
Don’ts:
- Don’t rely on counts alone — two tables can match in size but diverge in values.
- Don’t skip edge cases — dates, null handling, and slowly changing dimensions often hide defects.
- Don’t run tests only once — data warehouse logic evolves; ongoing regression prevents silent failures.
- Don’t separate BI validation — reports must be tested against the data warehouse to avoid drift.
- Don’t assume performance at scale — test with production-sized data, not subsets.
These practices align with QA principles but are adapted to data systems, and they are consistent with the DAMA Data Management Body of Knowledge (DMBOK), an industry-recognized framework for data governance and quality, and with the TDWI testing and quality guidelines, which many enterprises use as a benchmark.
By combining automation, documentation, and scale-aware checks, teams reduce both technical defects and downstream business risk.
Ready to Build Confidence in Your Data?
Testing ensures a data warehouse is more than storage — it becomes a reliable foundation for reporting and decision-making.
Take the next step: Discover how performance, scalability, and reliability can shape the way your teams work with data.
Frequently Asked Questions
Data warehouse (DWH) testing verifies that data loaded into the data warehouse is complete, accurate, and usable. It covers source-to-target checks, transformations, performance, and BI report validation.
ETL testing focuses on the data pipelines — extraction, transformation, and loading steps. DWH testing is broader, covering ETL plus schema validation, performance, regression, and BI report checks.
The process usually includes data extraction from sources, transformation according to business rules, loading into the data warehouse, validation through testing, and delivery of results to BI or analytics tools.
A data warehouse integrates data from multiple systems into a single repository. It stores historical and current data optimized for querying and reporting, supporting analytics and decision-making.
Source systems – operational databases, CRM, ERP, or external feeds.
ETL/ELT layer – moves and transforms data into the data warehouse.
Data warehouse storage – structured schemas optimized for analytics.
BI/Analytics tools – dashboards, reports, and data exploration.
Data warehouse testing checks the full, integrated environment across all domains. Data mart testing focuses on a subset of the data warehouse, usually department-specific, with limited scope.
Common methods include row counts, aggregate checks, duplicate checks, transformation validation, incremental load checks, regression testing, performance testing, and BI validation.
Data extraction from source systems.
Data transformation and cleansing.
Loading into staging and data warehouse schemas.
Delivery to BI and analytics tools.
The strategy usually includes requirement analysis, test case design (row counts, transformations, duplicates), environment setup, execution, and defect reporting.