
Data Warehouse Migration: Complete Strategy and Project Plan

Modern data teams face a common challenge: their existing data warehouse can’t keep up with the volume, velocity, and complexity of modern analytics. A well-planned data warehouse migration provides the foundation for scalable performance, cost control, and integration with new data platforms.
This guide outlines a complete data warehouse migration strategy, from assessment and planning to validation and optimization, based on proven enterprise practices. You’ll learn how to define your roadmap, avoid common pitfalls, and structure an actionable project plan that minimizes downtime and risk.
Whether you’re modernizing a legacy system or preparing an EDW migration to a hybrid or lakehouse architecture, this framework offers a clear path forward.
What Is a Data Warehouse Migration?
A data warehouse migration is the structured process of moving data, schemas, and workloads from one data warehouse environment to another. It can involve transferring on-premises systems to the cloud, consolidating multiple databases, or modernizing legacy EDW platforms to hybrid or lakehouse architectures.
Unlike a simple upgrade or storage expansion, migration affects how data is stored, queried, and governed. It requires careful mapping of data warehouse models, re-platforming ETL pipelines, and testing performance under new workloads.
Common types of data warehouse migration include:
- Lift-and-shift: replicating existing systems in a new environment.
- Re-platforming: optimizing data structures and queries during migration.
- Re-architecting: redesigning for new analytics patterns or technologies.
A successful migration reduces latency, improves scalability, and enables seamless integration with modern analytics tools. To understand how data warehouses fit within broader analytics architectures, see our data warehouse architecture guide.
Why Companies Modernize Their EDW
Enterprises modernize their enterprise data warehouse (EDW) when traditional systems no longer meet performance, cost, or scalability demands. Legacy platforms were built for structured, batch-oriented data, while modern businesses need real-time analytics, flexible scaling, and faster insight delivery.
Recent research shows the global data warehouse migration market was USD 6.1 billion in 2024 and is projected to reach USD 19.3 billion by 2033.
According to a BARC survey, 44 % of organizations cite a lack of agility in their data warehouse development process as a key driver of modernization.
Key drivers for EDW migration include:
- Performance: queries and dashboards slow under growing workloads.
- Cost efficiency: infrastructure becomes expensive to maintain and scale.
- Integration: data spread across multiple systems limits unified reporting.
- Innovation: new AI, ML, and BI tools require lakehouse connectivity.
- Data governance: regulatory and compliance needs demand improved data lineage and control.
Modern platforms enable concurrency, elasticity, and lower total cost of ownership (TCO), allowing teams to move from maintenance to innovation.
Scaling vertically on legacy hardware gets exponentially more expensive. Modern EDWs use distributed memory and parallel execution, giving predictable performance at a fraction of the cost.
Benjamin Klante, Senior Solution Engineer, Exasol
Before migrating, companies must define their objectives, assess data complexity, and build a structured plan. The next section outlines the five phases of a successful data warehouse migration.
5 Phases of a Data Warehouse Migration
A structured data warehouse migration reduces risk, downtime, and unexpected costs. Based on best practices from leading engineering teams, every migration can be divided into five clear phases, from assessment to validation.
Phase 1: Assessment
The first step is understanding your current data landscape. Identify data sources, schemas, workloads, and dependencies.
Document data volumes, transformation logic, and reporting requirements. This phase defines what must move and what can be retired.
Deliverables: system inventory, data-flow map, and migration feasibility report.
Phase 2: Planning
Define the migration scope, success metrics, and governance model.
Create a communication plan between data engineering, BI, and operations teams. Establish KPIs such as query-time targets or acceptable downtime.
Deliverables: migration roadmap, timeline, and stakeholder matrix.
Phase 3: Design
Translate the plan into a technical blueprint.
Choose the target architecture (cloud, hybrid, or lakehouse) and design schema mappings, staging areas, and validation frameworks.
Consider network bandwidth, data-type alignment, and security policies early to prevent rework.
Deliverables: solution architecture diagram and detailed design document.
Phase 4: Execution
Run pilot migrations before full rollout. Automate extraction and load using scripts or ETL pipelines.
Monitor throughput, log errors, and verify data integrity.
Once validated, execute the production migration in controlled waves to minimize disruption.
Deliverables: migration scripts, pilot reports, and production execution plan.
Phase 5: Testing and Optimization
After migration, run validation and performance tests as part of a broader data warehouse testing framework.
Compare row counts, query times, and dashboard outputs between old and new systems.
Tune indexes, caching, and concurrency parameters for the new environment.
Deliverables: test results, optimization checklist, and final sign-off.
Following these five phases ensures predictable results, reduces rework, and builds confidence in the new analytics engine environment.
Next, we consolidate these steps into a unified migration strategy framework.

Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
Data Warehouse Migration Strategy Framework
A well-defined data warehouse migration strategy provides structure, accountability, and predictability across all project stages. Rather than treating migration as a one-time technical event, this framework organizes the process into clear responsibilities, deliverables, and checkpoints that keep both IT and business stakeholders aligned.
A strong strategy answers five core questions:
- Why are we migrating? (Business goals and drivers)
- What is being migrated? (Data scope and systems)
- Who owns each phase? (Roles and accountability)
- How will we validate success? (Testing and KPIs)
- When will it be completed? (Timeline and dependencies)
The table below summarizes a practical migration governance model used by data teams to manage these steps efficiently.
| Phase | Objective | Key Tasks | Owner / Deliverables |
|---|---|---|---|
| Assessment | Understand current environment | Inventory data sources, ETL jobs, reports, SLAs | Data architect → System inventory report |
| Planning | Define roadmap and governance | Scope definition, risk assessment, timeline approval | Project manager → Migration roadmap |
| Design | Build target architecture | Schema mapping, performance modeling, security design | Solution architect → Architecture document |
| Execution | Transfer and validate data | Run pilot, migrate workloads, monitor integrity | Data engineer → Migration scripts and logs |
| Testing & Optimization | Ensure accuracy and performance | Validate data, tune queries, document results | QA & BI team → Sign-off report |
Each phase builds on the previous one, creating a controlled path from assessment to production. The framework’s purpose is to reduce uncertainty: every task has a defined owner, output, and validation checkpoint.
In practice, this model works best when combined with incremental delivery: start small with a pilot, gather performance metrics, and scale the process to full workloads. It also integrates easily with agile or DevOps methodologies, letting data teams iterate without disrupting business operations.
This structured framework ensures that both technical and non-technical stakeholders share the same view of progress and risk. By standardizing the process, organizations can cut migration time by 20–30 %, reduce rework, and maintain data quality from start to finish.
Project Plan and Timeline
A clear and realistic project plan transforms migration strategy into measurable progress. It helps stakeholders align on milestones, dependencies, and accountability, ensuring that every phase of the data warehouse migration runs on time and within scope.
The plan should account not only for technical steps but also for business continuity; for example, when to freeze ETL jobs, how to validate reports post-migration, and how to communicate changes to end-users. Assigning ownership to each task early reduces risk and prevents bottlenecks.
Typical migration timelines range from 8 to 50 weeks, depending on the data volume, the complexity of integrations, and the number of downstream systems connected to the data warehouse. Smaller proof-of-concept migrations may complete within a month, while enterprise-scale EDW migrations with multiple source systems can take a full year.
Here is a timeline example for shorter projects. Expand and adjust based on your own data warehouse structure:
| Week | Phase | Core Activities | Owner / Deliverables |
|---|---|---|---|
| 1–2 | Assessment | Identify sources, catalog data assets, set KPIs | Data Architect → Inventory report |
| 3–4 | Planning | Define migration scope, assign roles, finalize roadmap | Project Manager → Migration plan |
| 5–7 | Design | Create schema mappings, validate workloads, plan testing | Solution Architect → Design document |
| 8–10 | Execution | Pilot migration, monitor load times, run validation scripts | Data Engineer → Migration logs |
| 11–12 | Optimization | Benchmark, tune queries, document lessons learned | BI & QA → Optimization checklist |
When developing your internal plan, factor in data validation windows, rollback procedures, and post-migration QA. These steps are often underestimated but can consume up to 25 % of total project time. Use your first migration wave to uncover process gaps and refine for subsequent workloads.
Tools and Platforms Compared
Choosing the right data warehouse migration tools and platforms determines how smoothly the process runs and how much manual work is required. Each migration approach: cloud-native, lakehouse, or legacy modernization, comes with trade-offs in scalability, control, and complexity.
The most effective strategy combines automation for ETL and validation with a scalable target platform that supports modern analytics workloads. Below is a comparison of common approaches used in enterprise migration projects:
| Platform Type | Description | Example Tools / Technologies | Migration Complexity |
|---|---|---|---|
| Legacy EDW Modernization (Performance-Driven) | Modernizes existing high-performance or on-premises systems for better concurrency, cost control, and governance. Ideal for regulated or latency-sensitive workloads. | Exasol, Teradata, Oracle Exadata, IBM Netezza | Medium – Requires planning but delivers predictable performance, full control, and long-term cost stability. |
| Lakehouse Architecture & Optimization | Merges data warehouse reliability with data lake flexibility for unified analytics and AI workloads. Suitable for teams moving toward hybrid data architectures. | Databricks, Apache Iceberg, Delta Lake, Exasol | Medium – Scalable and future-proof but may demand new skill sets and governance models. |
| Cloud-Native Data Warehouse | Fully managed infrastructure with quick deployment but recurring usage costs and limited control over performance tuning. | Google BigQuery, Snowflake, AWS Redshift | High – Simplifies setup yet introduces unpredictable costs, data egress fees, and platform lock-in. |
When evaluating tools, focus on:
- Data volume and concurrency – how many users will query simultaneously.
- Governance and security – built-in lineage, access control, and auditing features.
- Integration support – native connectors for ETL, BI, and AI pipelines.
- Performance optimization – ability to run queries in memory or parallel threads.
Many organizations adopt a hybrid approach, combining a cloud data warehouse for scalability with on-premises or lakehouse systems for sensitive workloads. This allows gradual migration without operational disruption.
Selecting the right platform isn’t just a technical choice; it defines the future cost, agility, and analytics capabilities of your organization. Next, we’ll address the most common pitfalls and how to validate your migration for long-term success.
Common Pitfalls and Validation Steps
Even well-planned data warehouse migrations can fail without disciplined validation and governance. The following issues are the most frequent sources of project delays and data integrity problems. Each should be identified early and addressed systematically during testing.
- Incomplete source assessment
Skipping detailed source-system analysis leads to missing tables, broken joins, and schema mismatches.
Prevention: catalog every source, confirm data owners, and maintain a change-log during migration. - Uncontrolled scope expansion
Teams often add new requirements mid-project (new data marts, pipelines, or dashboards) which break timelines.
Prevention: freeze scope after planning; schedule separate modernization waves for extra components. - Data quality issues
Transformation errors, encoding differences, or null handling cause inaccurate reports post-migration.
Prevention: implement automated row-count and checksum validation between old and new systems. - Lack of rollback or recovery plan
Without rollback scripts, failed cut-overs force manual fixes and downtime.
Prevention: script reversible migrations, maintain backups, and test failback before production go-live. - Hidden performance regressions
Query times can increase when workloads shift to a new environment with different indexing or caching logic.
Prevention: benchmark key workloads and compare query latency before sign-off.
Validation should occur in three layers:
- Structural validation: schema, datatype, and constraint checks.
- Content validation: record counts, data sampling, and KPI comparisons.
- Performance validation: load, concurrency, and response-time tests under typical user scenarios.
Document each result and sign off before retiring the legacy environment. Consistent validation not only prevents rework but also builds trust with analytics users who rely on the data daily.
Next, we focus on how organizations execute EDW migrations from legacy to lakehouse architectures and where performance gains are realized.
Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
EDW Migration: From Legacy to Modernization
An EDW migration marks a shift from rigid, hardware-bound systems to flexible, high-performance environments that integrate structured and semi-structured data. Traditional enterprise data warehouses were optimized for fixed schemas and batch loads, but modern analytics requires fast iteration, mixed workloads, and near-real-time access.
A growing number of organizations are moving from legacy EDWs such as Netezza, Teradata, or Oracle to modern platforms that combine in-memory performance, high concurrency, and flexible deployment models. This transformation (often called EDW modernization) reduces maintenance effort and transforms capabilities like integrated AI/ML processing or vectorized queries.
According to independent performance benchmarks, Exasol fits this category: it delivers predictable, sub-second performance even under multi-user workloads while allowing customers to run analytics on-premises, in the cloud, or in hybrid mode. Unlike cloud-native data warehouses that meter compute usage, Exasol’s model gives teams cost predictability and sovereignty over sensitive data.
A phased EDW migration strategy usually includes:
- Assessment of legacy workloads – identify bottlenecks and redesign only what limits scalability.
- Hybrid transition – move selected schemas or departments first to validate performance.
- Parallel operation – run legacy and modern systems side-by-side until full data validation is complete.
- Cut-over and optimization – retire legacy infrastructure after all dashboards and reports match expected results.
By taking this incremental route, enterprises gain modern analytics performance without disrupting existing operations or losing historical data integrity. The next section illustrates how such a migration looks in practice.
Example Migration Scenario
A relevant example of a structured data warehouse migration comes from Helsana, one of Switzerland’s largest health insurance providers. The company modernized its data warehouse and analytics landscape to handle rapidly growing data volumes and enable faster, more reliable insights.
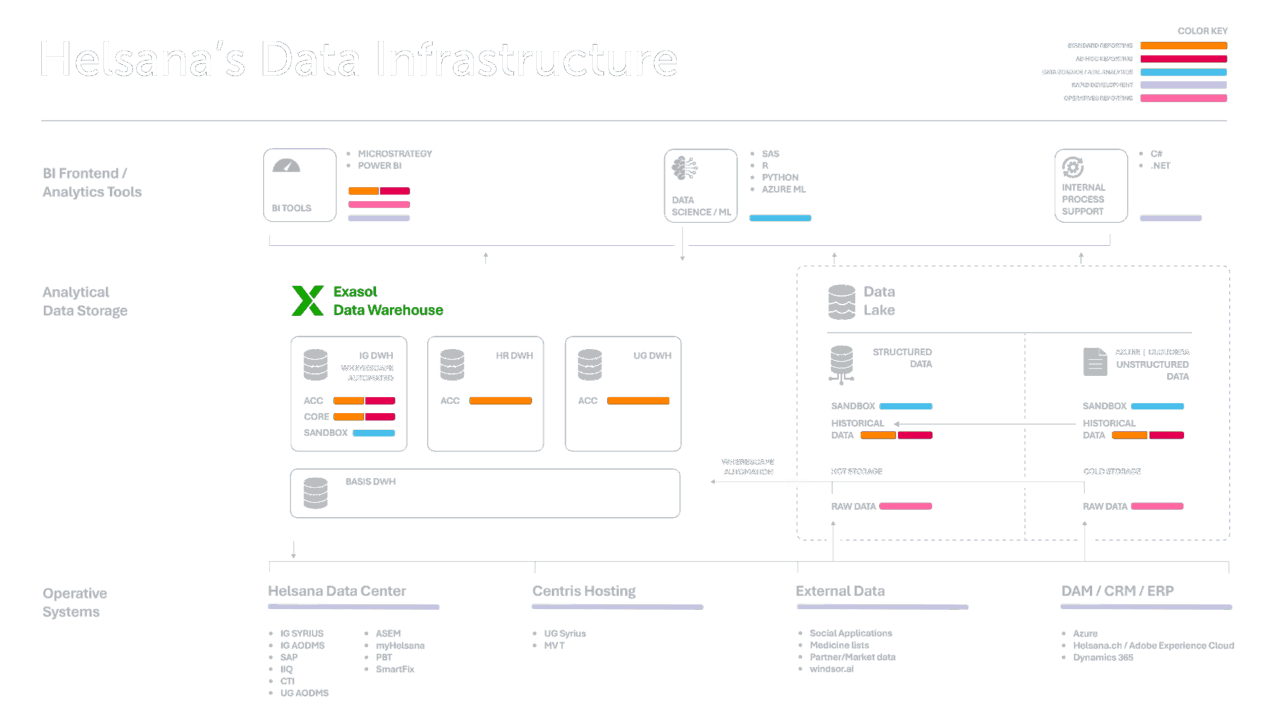
Assessment and Planning:
Helsana’s data engineering team began by analyzing its legacy data warehouse environment, identifying bottlenecks in ETL performance and reporting latency. The goal was to shorten long data-loading windows and improve access to up-to-date information across departments.
Design and Execution:
The team implemented a migration to a high-performance analytics platform capable of handling complex workloads and concurrent queries. They restructured data pipelines to optimize for parallel processing, ensuring consistency and governance through automated validation.
Testing and Optimization:
After go-live, Helsana’s data load times dropped from 26 hours to 4 hours, while analytics queries ran up to 10× faster. Maintenance and licensing costs were reduced by 65 percent, enabling the team to shift focus from system upkeep to business innovation.
This migration illustrates how a well-executed EDW modernization strategy improves performance, scalability, and cost efficiency without compromising data quality.
Next Steps
Modernizing or migrating a data warehouse is not a one-time event, it’s an ongoing process of optimization, validation, and governance.
Before executing any migration, ensure your organization has defined ownership, validation criteria, and rollback plans. This foundation prevents rework and ensures consistent analytics performance across teams.
Frequently Asked Questions
A data warehouse migration is the process of moving data, schema, and workloads from one data warehouse environment to another. It can involve transferring on-premises systems to the cloud, consolidating multiple data warehouses, or modernizing a legacy EDW for better scalability and performance.
The four classic stages of data warehousing are:
Data collection – extracting and cleaning data from source systems.
Data storage – organizing information in a structured data warehouse.
Data analysis – querying and processing data for insights.
Data presentation – delivering results through dashboards and reports.
These stages also apply during a data warehouse migration, ensuring integrity and usability throughout the process.
The three primary DB migration strategies are:
Lift and shift – moving existing systems with minimal changes.
Re-platforming – optimizing structures or queries during migration.
Re-architecting – redesigning for new analytics or cloud models.
Each strategy balances cost, speed, and risk differently, depending on data complexity and business goals.
The four main types of data migration are:
Storage migration – moving data between storage systems.
Database migration – transferring data between databases or data warehouse platforms.
Application migration – moving application data to a new environment.
Business process migration – restructuring data to support new workflows or systems.
A full data warehouse migration often combines several of these types into a coordinated program.