
Data Management Explained: From Definition to Practice

Data management (often shortened to data mgmt) is the coordinated process of collecting, organizing, validating, and maintaining data so that it stays accurate, consistent, and usable for analysis.
A reliable management layer ensures that downstream systems work with governed, high-quality data instead of conflicting or redundant records.
Effective data management starts long before anyone builds dashboards or reports. It starts when teams evaluate the data integration methods that connect operational sources to analytical storage. Every step from ingestion to modeling defines how fast and how confidently data can support decision-making.
Good data management isn’t just storage and access, it’s about predictable performance under load. The real challenge is keeping data consistent and queries fast when hundreds of users and processes run in parallel.
Florian Wenzel, VP of Product, Exasol
Without defined management rules, analytics workloads suffer from uncontrolled data growth, duplicated pipelines, and inconsistent KPIs. In contrast, structured management applies validation, versioning, and access control to keep data synchronized across environments. This discipline allows queries to scale, users to collaborate safely, and performance optimizations to persist across workloads.
In modern architectures, data management spans multiple layers: collection, metadata, transformation, and governance, each reinforcing the others. When these layers are aligned, analytics platforms deliver stable query performance under high concurrency and predictable cost. When they are not, no downstream optimization can recover data trust.
In short, data management spans multiple disciplines:
- Data integration: connecting operational systems, APIs, and external feeds.
- Data modeling: structuring data for query efficiency and analytical consistency.
- Data quality and cleansing: detecting and correcting anomalies.
- Data governance: defining policies, ownership, and auditability.
- Storage optimization: reducing duplication and ensuring scalability within a data warehouse.
A mature data management strategy treats these activities as one system, not isolated tools. When implemented correctly, analytics platforms can process terabytes of data without sacrificing concurrency or performance.

Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Core Concepts and Systems
A data management system provides the structure and control required to store and retrieve information reliably at scale. The system must handle every data type efficiently: from transactional records to time-series metrics.
Its purpose is straightforward: preserve data integrity while enabling fast access for analytics, reporting, and automation.
Every system follows the same lifecycle. Data is collected from source applications, validated against defined models, and transformed into a usable schema before loading into analytical storage. Without a management layer, ingestion becomes ad hoc, schemas diverge, and query performance decays over time.
Within an enterprise architecture, a management system typically includes:
- Ingestion layer: moves data from transactional systems, APIs, or event streams into a central repository.
- Transformation and modeling layer: standardizes formats and builds reusable entities for analytics.
- Storage layer: holds structured, semi-structured, or unstructured data under consistent policies.
- Governance and access layer: enforces permissions, retention rules, and data lineage.
- Monitoring layer: tracks quality, freshness, and system reliability.
Each layer must work predictably under concurrent load. A delay in ingestion or an untracked schema change can propagate downstream errors across hundreds of analytical jobs. Engineering teams prevent this through versioned pipelines, metadata registries, and dependency checks built into orchestration frameworks.
A data management system becomes fully effective when it is aligned with the overall data warehouse integration strategy. Modeling rules, table structures, and workload optimization must reflect how the data warehouse executes queries and distributes compute. When these layers operate in isolation, data governance fragments, and analytical performance degrades.
Examples of well-structured management systems include centralized data warehouses, federated lakehouse platforms, and hybrid architectures that separate compute and storage. The choice depends on data volume, concurrency requirements, and governance maturity, not on tooling alone.
Effective system design favors reproducibility over convenience. Tables, views, and models should be deployed through code and version control rather than manual configuration. This approach allows rollback after failed updates and consistent schema evolution across environments.
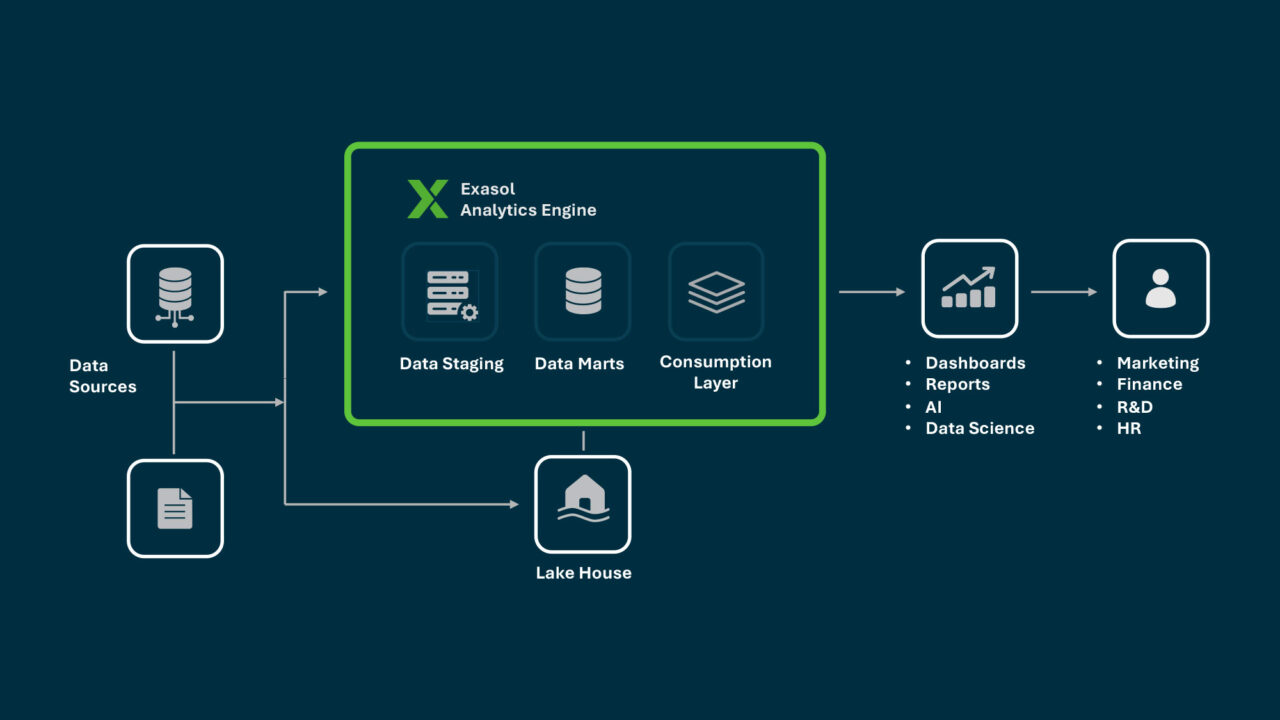
Understanding the data management basics, collection, transformation, validation, and access, helps teams design predictable pipelines.
The value of data management becomes clear when analytics pipelines scale. A stable system keeps compute costs predictable, ensures query consistency, and provides auditable data lineage. Without it, performance optimization becomes guesswork and business metrics drift over time.
Common Challenges in Data Management
Even mature data management frameworks encounter recurring operational barriers. As systems scale and more users depend on shared data assets, small inconsistencies in ingestion or governance multiply quickly. Recognizing these issues early prevents systemic failures later in the analytics pipeline.
- Schema drift: Source applications evolve faster than downstream pipelines. Without strict versioning and validation, mismatched fields break transformations or cause silent truncation.
- Data latency: Delayed ingestion or long batch windows make analytics stale. High-frequency workloads need near-real-time streaming or incremental updates.
- Inconsistent governance: Ownership gaps between teams lead to duplicate datasets and unclear accountability for data quality.
- Performance degradation: Query response times increase as datasets grow, especially when storage and compute layers are not optimized for concurrency.
- Audit complexity: Manual reconciliation of lineage and access logs slows compliance reviews and raises the risk of untraceable data changes.
These challenges are not unique to any one toolset, they stem from fragmented processes. Without coordination between ingestion, transformation, and access layers, even advanced data warehouses lose transparency and trust over time.
Best Practices
A structured data management approach transforms these weaknesses into measurable strengths. The goal is not to eliminate complexity, but to contain it through automation, documentation, and controlled environments.
- Version everything: Treat data models, transformation logic, and configuration as code under version control.
- Automate validation: Run schema, completeness, and freshness tests on every load. Automation removes guesswork and shortens recovery times.
- Centralize metadata: Maintain a single catalog linking datasets to owners, quality scores, and access rights.
- Separate environments: Keep development, testing, and production isolated but synchronized through automated deployment pipelines.
- Monitor performance at query level: Track concurrency, cache efficiency, and execution time to detect bottlenecks early.
- Align with integration standards: Use consistent ingestion and export formats defined in your integration processes to prevent fragmentation across systems.
Following these principles turns data management into a repeatable engineering function instead of an ad-hoc maintenance task. Over time, teams see faster recovery from failures, more predictable analytics performance, and lower compliance overhead: tangible proof that structured management outperforms reactive patchwork.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Data Management Software, Programs & Tools
Data management software coordinates how data is ingested, validated, and accessed across an organization. Its goal is not to create a single source of truth by decree, but to enforce technical consistency, schemas, transformations, and lineage, so that truth can be reproduced at any scale.
A data management program combines this tooling with defined roles, policies, and automation. It is less about the platform itself and more about how engineers, analysts, and compliance teams interact through it. A program formalizes ownership: who designs schemas, who approves data changes, and who tracks consumption across business units.
Modern data management solutions and software stacks typically include:
- Integration tools that capture and load data from APIs, message queues, or batch exports.
- Transformation frameworks that standardize structure and manage dependencies between models.
- Metadata and catalog systems that document tables, relationships, and lineage.
- Governance modules that handle permissions, anonymization, and audit trails.
- Orchestration and monitoring tools that manage pipeline scheduling and alerting.
Leading data management platforms provide elasticity, API-level control, and strong lineage visibility.
In advanced environments, these systems expose APIs for programmatic control. Code-based deployments replace manual configuration, reducing drift between environments and enabling version-controlled data pipelines. This shift (from GUI-driven tools to infrastructure-as-code) defines how modern data management achieves reliability at scale.
Performance-sensitive organizations evaluate management software not by features but by how efficiently it handles concurrent access and large-scale transformations. Execution models, indexing strategies, and caching mechanisms determine whether analytics queries return in seconds or minutes. Systems built without concurrency awareness often require redundant hardware or manual load balancing to stay responsive under production workloads.
Measured outcomes show how well-engineered management tools translate into real performance.
bank99 cut data load times from six hours to under ten minutes, enabling near real-time reporting. Helsana accelerated complex queries by a factor of ten and reduced data load durations from 26 to 4 hours.
Modernizing the data management layer often involves replacing legacy systems that cannot scale with analytical demand. When a platform combines high concurrency with predictable performance, migration becomes a strategic upgrade, not a risk. Replacement in this context means moving toward architectures designed for multi-user workloads and real-time analysis.
Evaluation Criteria for Data Management Software
Choosing data management software requires more than a feature checklist. The goal is to identify systems that can maintain governance, performance, and scalability under real production conditions.
The following criteria help teams evaluate options objectively:
- Concurrency model:
Assess how the platform handles multiple simultaneous queries or data loads. True multi-user architectures distribute processing efficiently without queueing or blocking. - Performance predictability:
Measure latency under increasing data volumes and concurrent users. Systems with in-memory or parallel execution architectures provide consistent response times as workloads scale. - Metadata depth and lineage tracking:
Check how fully the software captures relationships between datasets, transformations, and users. Deep lineage visibility shortens audit time and prevents accidental data loss. - Infrastructure-as-code support:
Look for APIs or declarative configuration that allow deployments and schema updates through CI/CD pipelines. Manual administration doesn’t scale. - Cost growth pattern:
Evaluate how compute and storage costs increase with volume and concurrency. Transparent pricing models make optimization predictable and prevent budget shocks. - Integration flexibility:
Verify whether the system connects easily to existing data warehouse, data lake, and BI tools. Closed ecosystems create operational silos and limit future adaptability. - Observability and diagnostics:
Ensure that query-level logs, metrics, and alerts are available to diagnose performance degradation or data inconsistencies quickly.
The strongest platforms meet these criteria consistently rather than excelling in only one area. In modern analytics environments, resilience and transparency matter as much as raw speed.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Processes, Methodology & Techniques
Data management processes define how raw data becomes reliable information. They are not theoretical frameworks but operational routines that determine how often data updates, how errors are corrected, and how new sources are integrated without disrupting existing pipelines. Integrating data from multiple sources requires consistent schema mapping and automated validation.
Principles similar to those outlined in the “Open Data Toolkit’s Supply & Quality of Data” guidance highlight the same goals of completeness, coherence, and traceable metadata across distributed environments.
A data management methodology provides the governance model for these routines. It defines ownership, escalation, and accountability for every step in the data lifecycle. Mature organizations document this as a living system, policies tied directly to technical implementation, not static manuals.
Typical methodologies combine six recurring stages:
- Acquisition: Extracting data from internal systems, APIs, and external partners.
- Validation: Applying schema checks, completeness tests, and anomaly detection.
- Transformation: Converting structures, unifying units, and joining datasets.
- Storage: Writing validated data to a governed target such as a data warehouse or data lake.
- Delivery: Making curated data accessible to applications, dashboards, or models.
- Monitoring: Measuring latency, freshness, and data quality metrics in real time.
Data management techniques translate these stages into repeatable engineering practices. For ingestion, teams use dependency graphs and version-controlled pipelines to guarantee consistent execution. For transformation, they rely on modular SQL or code frameworks to prevent duplication. For governance, they link technical metadata to ownership metadata, allowing traceability from source to report.
Automation extends these techniques beyond manual monitoring. Modern pipelines include automated tests for data drift, schema mismatches, and performance regressions. These checks detect silent failures, cases where data loads succeed but produce incomplete or stale results. When combined with metadata versioning, automation reduces recovery time and prevents data consumers from using outdated results.
Transformation methods depend on the underlying data warehouse architecture and how compute resources handle large-scale joins or materialized views. Engineering choices here directly affect query latency and the frequency at which data can be refreshed without bottlenecks.
Analysis plays a central role in assessing process efficiency. Engineers track pipeline execution time, query concurrency, and error recovery rates. Analysts measure how often reports rely on data updated within defined SLAs.
These metrics expose weak points: bottlenecks in integration, unoptimized transformations, or misconfigured access rules. Continuous monitoring ensures that improvements are validated against measurable outcomes, not anecdotal feedback.
Data Management Technology in Practice
Data management technology defines how each process (ingestion, transformation, governance, and delivery) actually runs in production. It is the execution layer that converts policy into behavior and architecture into measurable performance.
In a modern environment, tech data management forms a distributed system of storage, compute, and orchestration components. Databases execute queries in memory or across clusters; integration services manage parallel data movement; catalog services maintain metadata consistency; and automation frameworks ensure that every run produces identical results. The system’s efficiency depends on how tightly these components coordinate. Adopting open standards for data helps ensure systems interpret schemas and metadata uniformly across domains.
A common failure point occurs when storage and compute are treated as independent domains. Query optimization becomes unpredictable, and pipelines slow down as concurrency rises. Scalable architectures connect the two, either through shared-nothing designs or tightly coupled in-memory systems, to maintain predictable latency under variable load.
In practice, the technology stack must handle three competing goals:
- High concurrency for multiple users and workloads.
- Predictable query performance under heavy data volumes.
- Governed access to prevent cross-domain interference or data leakage.
Achieving all three requires infrastructure that can process large queries while enforcing strict read and write isolation. These characteristics are fundamental to analytical databases and platforms optimized for mixed workloads.
Data management technology also determines how analytical teams implement lifecycle control: testing schema migrations, scaling storage elastically, and deploying pipelines safely. Systems that expose this control through APIs or infrastructure-as-code frameworks allow engineers to integrate automation directly into CI/CD pipelines.
When pipelines connect many systems, they need to operate in an organizational context. The interoperability development phases model helps teams align data definitions, access, and quality across domains.
This reduces deployment time and removes manual handoffs between operations and analytics.
For teams designing or optimizing modern data warehouse environments, data management technology must align with the broader implementation strategy. Schema evolution, workload management, and caching policies should be tested against the same architecture used in production. Misalignment between management tools and data warehouse execution layers is the most common cause of unexplained query delays and inconsistent metrics.
Adopting new data management technology is not only about performance gains. It is also a strategic step toward reducing operational complexity. When the same platform handles ingestion, modeling, and governed analytics, maintenance overhead decreases and compliance workflows become traceable. The result is less time spent reconciling data and more time analyzing it.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Business Impact and Benefits
Effective data-based management decisions deliver measurable outcomes across performance, cost, and governance. Its impact is easiest to see in environments where analytics drives operational decisions and every second of query time or every redundant data copy has a financial cost.
Reliable analytics improves business operations by connecting performance metrics directly to operational data.
A structured management layer improves query predictability. When data validation, indexing, and caching are coordinated, analytical workloads maintain stable response times even as concurrency increases. This predictability allows finance, marketing, and operations teams to rely on near real-time dashboards without scheduling around batch updates.
Cost control is a direct result of process efficiency. Systems that manage data lineage and eliminate duplicate transformations reduce compute cycles and storage consumption. A well-governed catalog also limits unnecessary data movement between environments—fewer exports, less duplication, and shorter synchronization windows. Over time, these savings exceed the cost of any management platform that enforces them.
Governance and compliance benefit from the same foundation. When ownership and metadata are clearly linked, audits become verifiable instead of manual. Access logs, schema versions, and retention policies can be reviewed programmatically. This structure shortens audit cycles and reduces the likelihood of compliance gaps caused by undocumented changes.
High-quality inputs enable faster, data driven decisions across finance and operations.
When data management is done right, it stops being invisible cost and becomes visible value. You can measure it in faster decisions, shorter audit cycles, and better use of your existing infrastructure.
Florian Wenzel, VP of Product, Exasol
Use Cases in Practice
Performance metrics from our customers illustrate these effects.
- bank99 cut data load times from six hours to ten minutes, which allowed the bank to deliver daily reports that were previously only available overnight.
- Helsana improved query performance by 10× and reduced load times from 26 to 4 hours, supporting faster risk analysis and policy simulations.
- Monsoon Accessorize reduced report generation time from 18 hours to minutes, enabling real-time stock visibility.
Each case study reflects the same pattern: optimizing how data is managed (validation, modeling, caching, and access control) improves analytics outcomes without requiring linear increases in compute resources.
For executive teams, the business case extends beyond performance metrics.
Strong data management reduces decision latency, accelerates model iteration cycles, and makes it possible to connect operational and analytical systems safely. When data pipelines are transparent and governed, organizations can scale innovation without scaling risk.
Final Thoughts
Data management is more than process control, it defines the speed, reliability, and trustworthiness of every analytical decision.
When validation, modeling, and governance operate as one system, analytics pipelines scale predictably and results stay verifiable under heavy load.
Remember, teams that invest in structured data management gain faster access to accurate metrics, lower operational overhead, and stronger compliance assurance.
Frequently Asked Questions
Data in data management refers to any structured or unstructured information collected, processed, and stored for operational or analytical use. The management layer ensures this data remains consistent, validated, and accessible throughout its lifecycle.
Most frameworks describe four primary types: data integration, data storage, data governance, and data security. Together, they cover how data is collected, maintained, protected, and made available for analysis.
Data management means organizing, controlling, and maintaining data assets so they can be used reliably and efficiently across analytical and operational systems.
Common categories include database management systems (DBMS), data warehouse systems, data lake systems, and metadata management systems. Each serves a distinct role depending on data volume, structure, and use case.
Examples include analytical databases, data warehouse platforms, and data integration frameworks. Each system provides a mechanism to collect, structure, and query large volumes of data under defined governance.
No. SQL (Structured Query Language) is a programming language used to query and manipulate data within a database management system. It supports data management but is not itself a management system.
There is no universal “best” tool. The right platform depends on concurrency requirements, data volume, and architectural goals. Systems designed for analytical workloads (those with in-memory execution and scalable parallel processing) tend to deliver the most consistent results.
Data management software provides the interfaces and services needed to control data flow, enforce quality rules, and maintain lineage across multiple environments. It acts as the operational backbone of an analytics ecosystem.
Typical examples include ETL or ELT frameworks, data catalogs, orchestration systems, and analytical databases. The combination used depends on how much automation, governance, and concurrency the organization requires.
The most common database management models are hierarchical, network, relational, and object-oriented. Relational databases remain the standard for most analytical workloads because of their structured query model and mature ecosystem.