
Improve software quality with automatic testing
Automatic testing is absolutely essential for software quality, not only at Exasol but for any professional software project. Untested software is defect software and saying, ‘but we have manual tests’ is just a fancy way of saying, ‘our software is mostly untested.’ If you don’t believe that, just calculate in your head how long you think a hundred manual test cases would take you. Compare that to the time you have for regression testing. And a hundred tests are only a fraction of the tests a non-trivial software needs for decent code coverage.
Manual tests and no regression tests are synonymous. So with that in mind our goal must be to get as much tested automatically as possible in our projects.
Aim high with test coverage – and you’ll get peace of mind
If possible I like to achieve 100% test coverage for the code I write. The reason for doing this is simple – it means I can sleep better at night. After all, it’s quite possible to get up to 80% with your test coverage and not test a single line of the most critical parts of your software.
When 100% is your goal, you’ll sooner or later run into the limitations of your coverage tools. Today I ran coverage tests on a switch statement using EclEmma. And one particular switch statement simply refused to go completely green.
In the screenshot below you can see that the body of the switch case is completely green, but the head is yellow, indicating partial coverage.
 Loading...Java SWITCH" class="wp-image-11202"/>
Loading...Java SWITCH" class="wp-image-11202"/>My first instinct was to blame the toLowerCase(), so I wrote tests with uppercase strings, but that had no effect. That’s because it doesn’t create new paths. So the next test I did was to cover the invisible NULL pointer check that the switch statement does behind the scenes. The test proved that a NullPointerException was thrown, but it didn’t not improve the coverage.
Make sure you know what you’re measuring
What we see in the above example is an implementation detail of the coverage measuring toolchain, which users “nrainer” and “owasim” nicely point out for us on Stackoverflow. To sum up their explanation:
The situation is caused by the fact that Java uses the hash sums of the object serving as switch criteria. It then creates a lookup table under the hood that often has more branches than the original switch statement. The test code doesn’t reach all lookups because of the way the hash codes are distributed across the lookup table.
Hitting the invisible branches would be pure luck. EclEmma instruments the code the Java compiler generates and projects the measured coverage back onto the source code. What we have here are projection results, not the real coverage.
So how do you fix all of this?
As you’ll see there are no perfect solution. Let’s take a look at a couple of options here.
Variant A: using an Enum in the switch
If you replace the switch criteria in the code above by an enum, the EclEmma now sees the same number of decision paths as are visible in the source code. But you introduce a new problem – the default path isn’t reachable by regular tests.
This creates a dilemma, leaving you with the following options:
- remove the default path and risk hard to trace problems later if the enum ever gets extended
- keep the default path as good practice of defensive programming
- use tricks to reach the default path
Enums in Java can’t be extended, so simply deriving an enum with an illegal value for test purposes isn’t an option. Mock frameworks only work in this case if they can mock static language elements, and if it isn’t trivial.
Also, in the case of the method above the conversion from strings to enum would simply move to the enum. So if you don’t use a method where the enums are used as a parameter, it adds unnecessary complexity.
Variant B: Using an If-cascade
If your replace the code above with an if-cascade, the problem is solved.
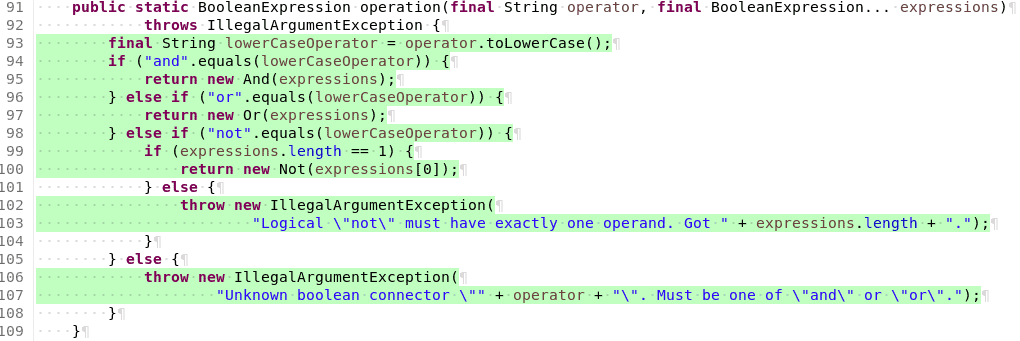
But it comes at an obvious cost. First of all this code loses a lot of its readability. Second it’s not as run time-efficient as the switch case because the compiler doesn’t create a lookup table in this case. Instead, it creates a series of ifs and comparisons. The code is also a lot more complex, meaning that it has more potential parts that can be wrong.
Conclusion
Aiming for 100% test coverage saves you the nagging doubt whether you forgot to test something important. On the other hand actually achieving this is incredibly hard to do as it introduces limitations in the way code coverage metrics work and it’ll have you reaching for defensive code that should be unreachable under normal circumstances. So what’s the answer? Personally, despite my endless quest for perfection, I prefer lower code complexity and better readability over maximum test coverage.