
An Exasol database will automatically create, maintain and drop indexes, following the core idea to deliver great performance without requiring much administrative efforts. Like Exasol’s tables, the indexes are always compressed and users don’t need to configure anything.
Exasol processes joins between two or more tables like this – one table is scanned in full, this is called the root table. All other tables are joined using an index on their join columns.
If these indexes on the join columns don’t already exist, they’re automatically created during the join operation. For example, taking two tables t1 and t2, and a statement like:
select count(*) from t1 join t2 on t1.joincol = t2.joincol;
The Exasol optimizer will compute an execution plan based on automatically gathered statistics that inform it about the table sizes among others. The smaller table will often become the root table and the other table will be joined using an index on the join column.
Lets look at an example:
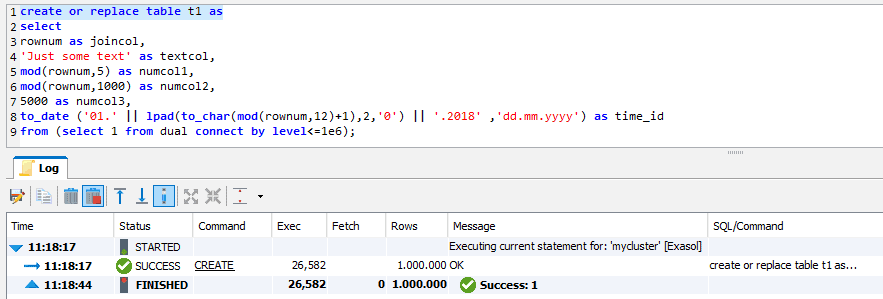
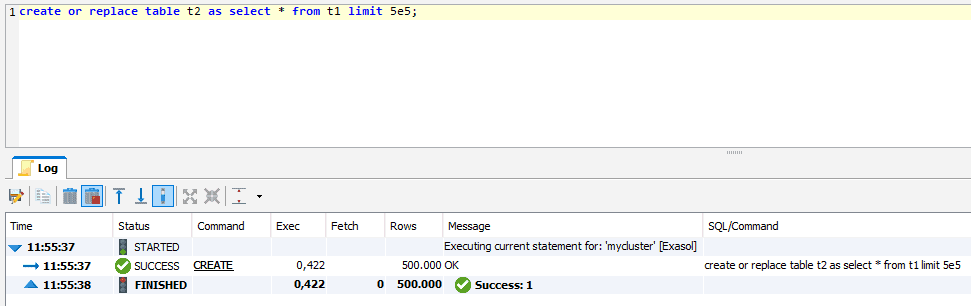
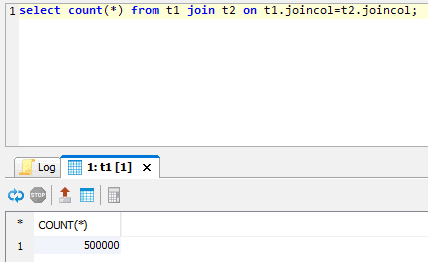
This index was created during the query execution on the first join between t1 and t2. It subsequently supports further joins with t1 on joincol.
If Data Manipulation Language (DML) is done on t1, the index is maintained by the system:
- INSERT into t1 will add new index entries.
- DELETE from t1 will mark rows as deleted until more than 25% of rows have been deleted. t1 is then reorganized automatically and the index is automatically rebuilt.
- UPDATE statements that affect less than 15% of rows will update index key entries. If more than 15% of rows are updated, the index is automatically rebuilt.
If an index isn’t used to support queries for more than five weeks, it’ll be dropped automatically. That way, an idle index won’t slow down DML and take up space for no reason.
Nothing needs to be done operationally about indexes in Exasol and that’s what most of our customers do. They just let the system take care of indexes. In earlier versions, EXA_DBA_INDICES didn’t even exist to avoid providing superfluous information.
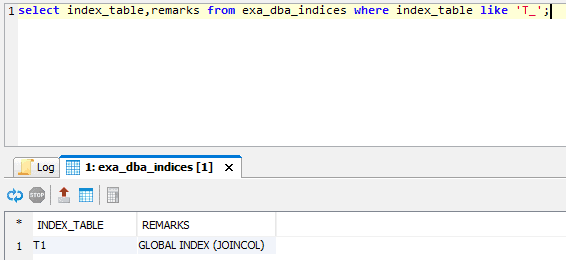
So what is a global index and why was it created that way on t1?
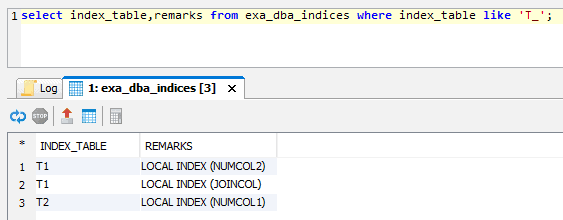
Like tables, indexes are also distributed across the Exasol cluster nodes. A local index is when the index part on a node points only to table rows on the same node.
For a global index, it’s the index part on a node points to – at least some – table rows on another node. This means a global join leads to global indexes while local joins lead to local indexes. Profiling a join between t1 and t2 confirms that:
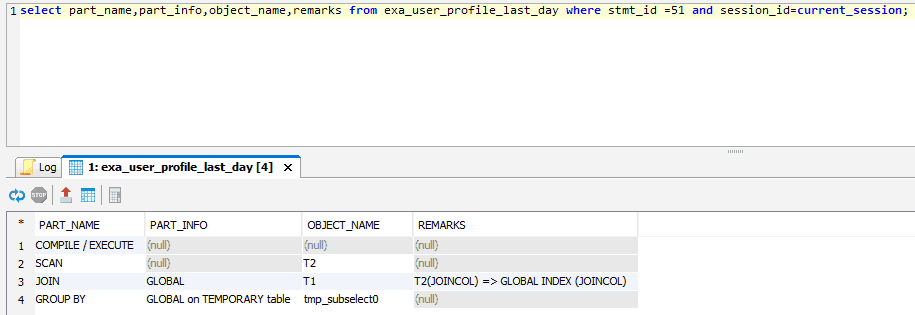
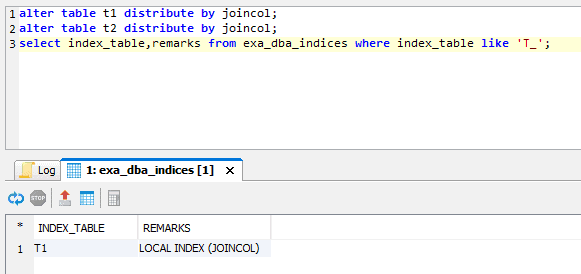
This example is of a global join using a global index. If the two tables were distributed on joincol, this leads to local joins with local indexes. Putting the distribution key on joincol for t1 will automatically convert the existing index into a local index:
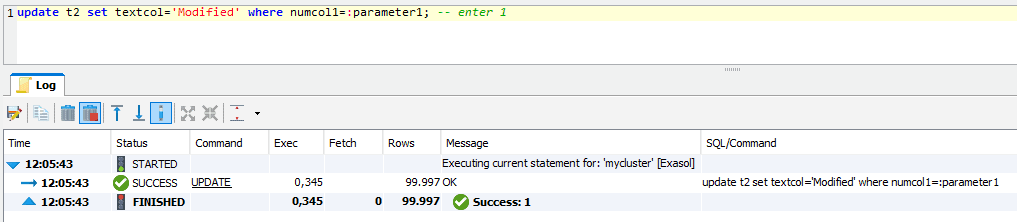
When using prepared statements to UPDATE or DELETE, this may automatically create an index in the filter column:
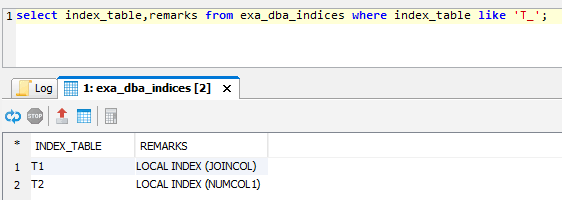
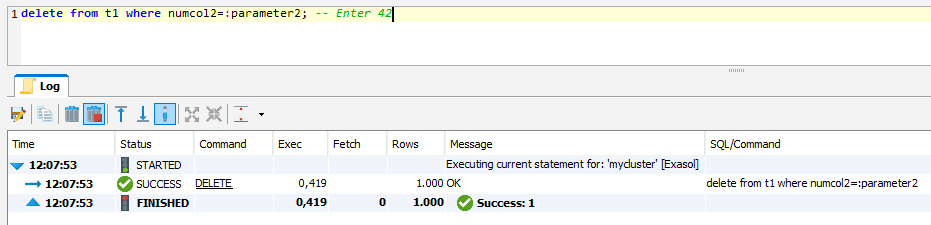
This results in local indexes because there’s no need to refer to rows on other nodes while each node updates or deletes on their locally stored part of the tables.
Using DbVisualizer as a SQL Client for these demos prompts for inputs of :parameter1 and :parameter2 when the statements are executed.
Another reason why indexes are automatically created is when primary or unique constraints are added to a table:
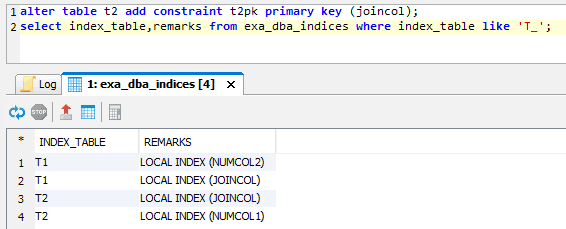
This creates a local index because t2 is distributed on joincol.
Please don’t take this as a recommendation to add primary or unique constraints to tables in Exasol. I just mentioned it because it also leads to the creation of indexes. MERGE statements also create indexes because they’re processed as joins, by the way.
Although customers aren’t required to do anything about indexes, there are a couple of good practices that help your Exasol database perform even better.
Small numeric formats are optimal for join columns and lead to small efficient indexes. It’s often beneficial to replace multi-column joins or joins on large formatted columns by joins on numeric surrogate keys. Identity columns help to generate these surrogate keys.
Avoid using expressions on the join columns because the resulting indexes aren’t sustained and have to be built again during every join:
select count(*) from t1 join t2 on t1.joincol+1=t2.joincol+1; — don’t do that
Avoid having mixed data types on join columns because that can also lead to expression indexes:
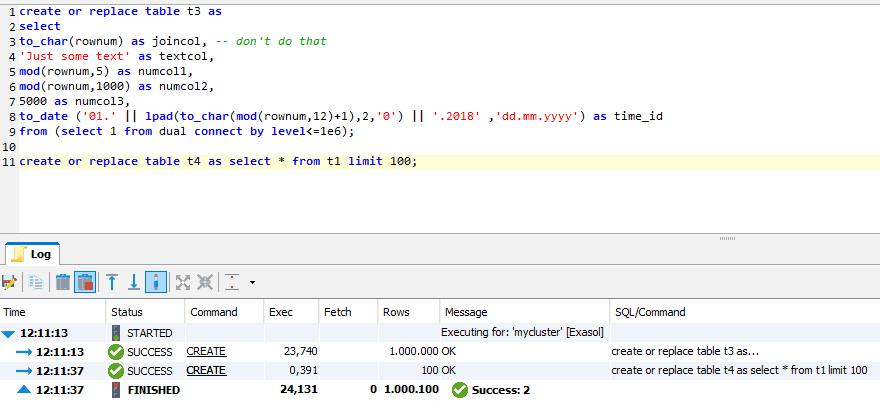
The previous example created t3, a large table using a string type for joincol, and t4, a small table using a numeric type for joincol. By joining the two, it’s likely t4 becomes the root table and t3 is expression indexed:
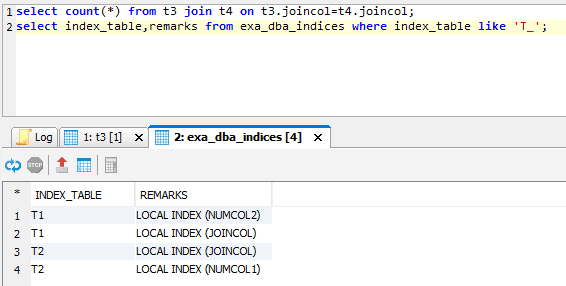
No index listed for t3 as you see. The profile of the join between t3 and t4 shows:
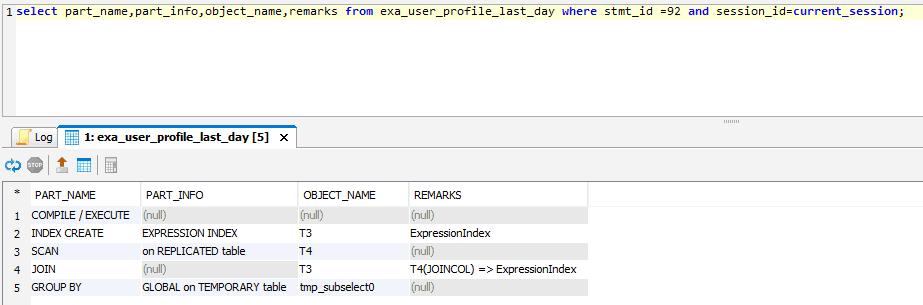
An index was created for the join, but expression indexes aren’t sustained. This was a local join (no GLOBAL indicator in the PART_INFO column for the JOIN step) because t4 was replicated across all nodes due to its small size.
Apart from following the good practices mentioned, there’s simply not much for customers to take care of related to indexes in Exasol – it just works.
Executive Summary
- Exasol creates all indexes it needs automatically.
- Tables and indexes are automatically compressed.
- Tables and indexes are automatically reorganized if required.
- Idle indexes are automatically dropped.
- The administrative effort related to indexes is close to zero in Exasol.
- Initially investing some time in proper table design might still be a good idea.