
Exasol Virtual Schemas are an abstraction layer that makes external data sources accessible in our data analytics platform through regular SQL commands.
Regardless of whether that source is a Loading...relational database like ours, or it’s like the structure of GitHub repositories, the interface that users see is always the same.
Querying an external source through an Exasol Virtual schema looks exactly like accessing regular tables and columns. And that’s the beauty of it.
What we’ll look at in this Virtual Schema blog series
In the next few weeks we’ll regularly release technical articles that form part of a series about Exasol Virtual Schemas. Today we start with a general introduction and the high-level structure.
At the end of the article you’ll find a sneak-peek into our latest development efforts and what they will change in the architecture of Virtual Schemas.
Why use a Virtual Schema?
It’s a valid question as you could always have an external process copy the data into our data analytics platform and query it afterwards.
But the Virtual Schema has many advantages over that method:
- You don’t need to copy the data if you only need it temporarily. That saves space and time.
- Querying external sources provides you with a uniform SQL interface independently of the sources’ original interface.
- Database users are usually good at writing SQL code. What would be more convenient than reusing those skills?
- You don’t have to deal with data type conversion. The Virtual Schema does it for you.
- Since you have a uniform query interface, you can exchange the source for a different product if you like. The code on top of a Virtual Schema still works.
- Our data analytics platform is a massively parallel software. The Virtual Schemas are designed to use parallel access to sources which support this.
- Querying remote data instead of copying it makes housekeeping easier. You don’t have to implement code to delete data. The source can decide when it is time for that data to not be available anymore.
The Architecture of a Virtual Schema
As I am writing this article in March 2019, the current structure of the Virtual Schema from a birds-eye perspective looks like this:
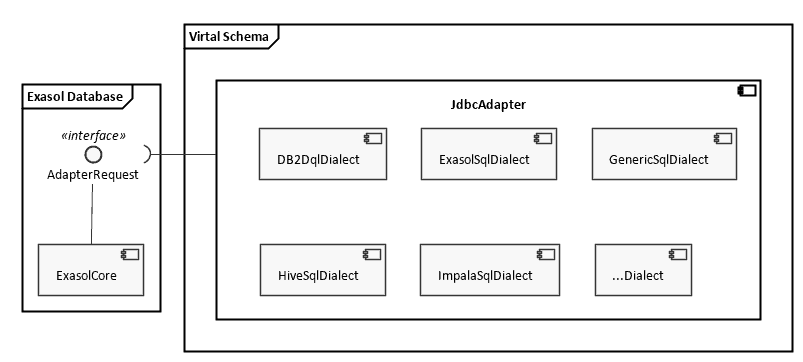
You can see that our data analytics platform is pre-packaged with an interface that enables interaction between the core of the database and a Virtual Schema. This interface is called “AdapterRequest” and constitutes a JSON-based protocol.
The frames around the components and interface show you, which parts are delivered with the platform’s distribution, and which belong to the Open Source project where the Virtual Schemas are developed.
Inside the Virtual Schema project you’ll find a component that bundles all common parts of all adapters. E.g. the implementation of the protocol that talks with the database. You’ll also see a large component called “JdbcAdapter“.
This component is responsible for connecting to the external data sources and communicating with them via JDBC.
Basically, it is the one-stop solution for attaching any Relational Database Management System (RDBMS) that offers a JDBC driver.
The bulk of the Virtual Schema code runs inside a User Defined Function (UDF). If you’re looking for the entry point, check the “Loading...java/com/exasol/adapter/jdbc/JdbcAdapter.java#L34" target="_blank" rel="noopener noreferrer">adapterCall(...)” method:
public static String adapterCall(final ExaMetadata meta, final String input)
I recognize that dialect you’re speaking
Unfortunately while JDBC is standardized, there are always subtle differences in the data types and features an RDBMS supports. To even out those differences, we introduced the concept of dialects in the Virtual Schemas.
As you saw above, our Virtual Schema supports multiple dialects. In fact, I am counting twelve dialects at the time I am writing this. From Open Source RDBMS like PostgreSQL to commercial products like Oracle.
A dialect…
… defines the capabilities of a Virtual Schema that’s used with a certain data source
… makes use of source-specific SQL extensions
… converts source-specific data types into those used in our data analytics platform
… provides users with additional configuration options needed for that particular source
To each its own
While the concept of supporting dialects from the JdbcAdapter allowed us to quickly support an impressive number of 3rd-party RDBMS, we’re now reaching a point, where a more modular approach is required.
We already started to turn the source adapters into plug-ins. If you’re familiar with the adapter design pattern [Gamma et al. ,”Design Patterns: Elements of Reusable Object-Oriented Software“], you know that an adapters job is to translate between two components that were not originally designed to be compatible.
As a consequence, this means that each source will get a separate adapter.
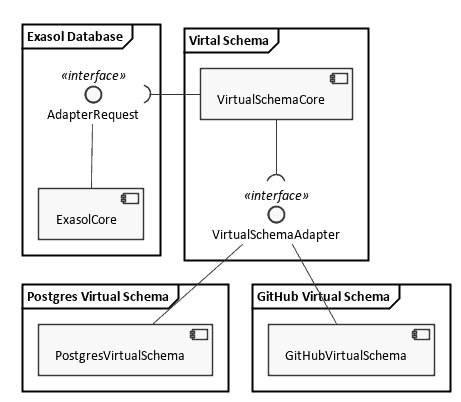
Note how the core of the Virtual Schemas now defines and uses a standardized interface that all plug-ins must implement.
While that makes the software project structure more complicated, it has some obvious benefits.
Lets for the sake of the example assume you want to attach a MySQL database as source of a Virtual Schema. At the moment you install the JdbcAdapter with support for all other dialects — even those that you do not need. From a user’s perspective that means unnecessary complexity and resource usage. More deployed code also means a higher risk for security vulnerabilities.
In contrast, if each source has a separate plug-in, you can install the common part of all Virtual Schemas plus just the plug-in you need.
As you can see in the diagram above the new structure has another benefit: it doesn’t matter whether or not the external data source is an RDBMS anymore. At least from the perspective of the Virtual Schemas core implementation. This is a level of detail intentionally hidden in the implementation of the individual adapter.
Last but not least, each adapter will be its own Open Source project. And that allows us to release new features in one adapter independently of the others.
Conclusion
Virtual Schemas are a convenient way to extend the our data analytics platform with access to external data sources. In March 2019 we already support twelve 3rd-party products and we’re currently working on future-proofing the architecture to support even more. Stay tuned for our next blog where we plunge into the technical detail, giving you a practical guide to using our Virtual Schemas.