
Text-to-SQL is Dead – Long Live Text-to-SQL

For the third time, within less than a year, we are discussing Text-to-SQL. First, it was just a test with a publicly available service on the HuggingFace website (https://www.huggingface.co). This raised our interest in exploring the possibilities further. In our second attempt, we implemented a one-shot transformer that converts natural language questions into SQL statements, running this process entirely on premises. However, major parts of the rendering are performed by a publicly available LLM service. Our final attempt was to bring the entire process in-house to our own premises and to explore ways to circumvent obstacles – a surprisingly easy process.
The Problem
Using a Large Language Model (LLM) to transform a natural language question into a database-compliant SQL statement is not entirely new; it appeared when LLMs were trained for coding tasks. The results of the transformations are pretty impressive, and they open the world of data analysis to a new user group. While Data Scientists or Data Analysts usually know the SQL query language very well, for the occasional user, SQL can become a major hurdle, especially when mastering SQL is not included in their job profile or is not their prime concern. Saying this, Text-to-SQL can expand the audience to a much larger scale, enabling many more users to query the Exasol analytics engine and retrieve valuable information quickly and easily. It is to be seen complementary to existing BI tools and addresses a different user group.
So, why is Text-to-SQL dead then?
Typical AI Desktop applications, such as Anthropic’s Claude, utilize their own LLM within their infrastructure. In other words, you lose control over your data. Transforming a natural language question into SQL requires at least metadata information, which already contains valuable information that may be confidential. If you let the LLM execute the generated SQL on your database by a tool of a so-called MCP server, and render it afterward for a visual representation, even real data will leave your premises. Certain companies or industry segments may be fine with this fact, while others cannot tolerate it, either due to their own interests or regulatory requirements. This leads to our statement „Text-to-SQL“ is dead, obviously not for everyone, but for a group of substantial size.
The Solution
How can we revive Text-to-SQL? First, we need to determine what is truly required for a pure on-premises solution:
- An LLM server that is capable of serving one or more Large Language Models and is able to serve the company’s needs with regard to interaction or usability; GPU acceleration is a big plus if not mandatory.
- A Text-to-SQL Processor
- An MCP Server that acts as the gateway between the LLM and the database.
- An AI Desktop application that allows for operating against local LLM servers.
If we can fulfill these requirements, we can clearly state „Long Live Text-to-SQL“.
Governed SQL
Also, when describing the entire process and referring to Text-to-SQL, we have a process in mind, which we call „Governed SQL“. We entirely control the translation into SQL, disallow any non-READ-ONLY queries, learn from previous similar questions, and can re-formulate a question if needed to ensure the quality of the translation process. While controlling the entire process, from the natural language question to the rendered result, we can ensure the principles of integrity, security, and safety of your data. Consequently, we will use both terms synonymously.
The LLM Server
For the first requirement, we utilize Ollama (https://ollama.com/). It supports GPUs from NVIDIA, AMD, or Apple’s Metal framework. You interact with Ollama via OpenAI’s API in the same way as you would interact with, for example, ChatGPT. As an alternative to Ollama, you can use LM-Studio (https://lmstudio.ai/). Please refer to Ollama’s or LM-Studio’s websites for instructions on setting up the LLM servers on your infrastructure.
The MCP Server
The missing link between an LLM and, in our case, the Exasol database is the so-called MCP Server, which plays a vital role. Here, MCP stands for „Model Context Protocol“ and allows interaction with the database. Other MCP Servers can interact with Mailers, Chat applications, or other kinds of applications. This Protocol has evolved to the de facto standard for integrating LLMs into an IT environment and has a similar importance as the well-known REST API.
Exasol has recently published an MCP Server on its GitHub repository (https://github.com/exasol/mcp-server), and our colleague Madeleine Corneli has published a very interesting blog article about it (https://www.exasol.com/blog/integrating-exasol-mcp/). However, the nature of this server primarily addresses technical users. It can retrieve metadata from the database and execute Read-Only SQL statements. The Text-to-SQL option is not included in this version. However, a version of the MCP server is available that includes Text-to-SQL functionality (https://github.com/exasol/exasol-labs-text2sql-mcp-server). It augments the official Exasol MCP Server with the Text-to-SQL functionality, which is discussed below.
The Text-to-SQL Processor
We now reach a point where we must issue an explicit warning to all interested users. Large Language Models can make mistakes, and eventually, they will. Depending on the level of training, they may misinterpret the semantics of the natural language question and, consequently, transform it into an incorrect SQL statement, which can result in incorrect or misleading results. It is the sole responsibility of the user to verify the result for validity.
The above statement varies for different LLMs, and there is no general rule possible when or how an LLM produces faulty or misleading results. Besides the selected LLMs, the database design is a crucial contributor to the overall quality of the transformation process. Well-thought-out and descriptive column names or column comments provide significant support for the transformation process. The next step would be to utilize a semantic layer, such as the Exasol Semantic Layer, formerly known as Exalerator, where we previously reached the best results in translating human questions into SQL statements. For this work, we intentionally excluded the Exasol Semantic Layer, as we wanted to assess how well the transformation process performs on a raw database design.
For a Text-to-SQL process, we have to implement various steps on our own, which come for free with the big LLM Services. First, we check whether a natural language question can be successfully converted into an SQL statement for a given database schema. Depending on the LLM you want to use for the translation process, you may find yourself in a position where you need a second LLM for rendering your results. The MCP server supports separate LLMs for translating to SQL and result rendering. If a SQL statement is created, we need to check if the type of SQL is allowed for execution. Currently, we want to allow only read-only statements. Then, the SQL is executed against the database and checked for validity; the database can execute the SQL without any errors. If the SQL statement is invalid, we want to retry up to three times with a corrected version of the natural language question. Finally, we need to render either informational messages or the result set.
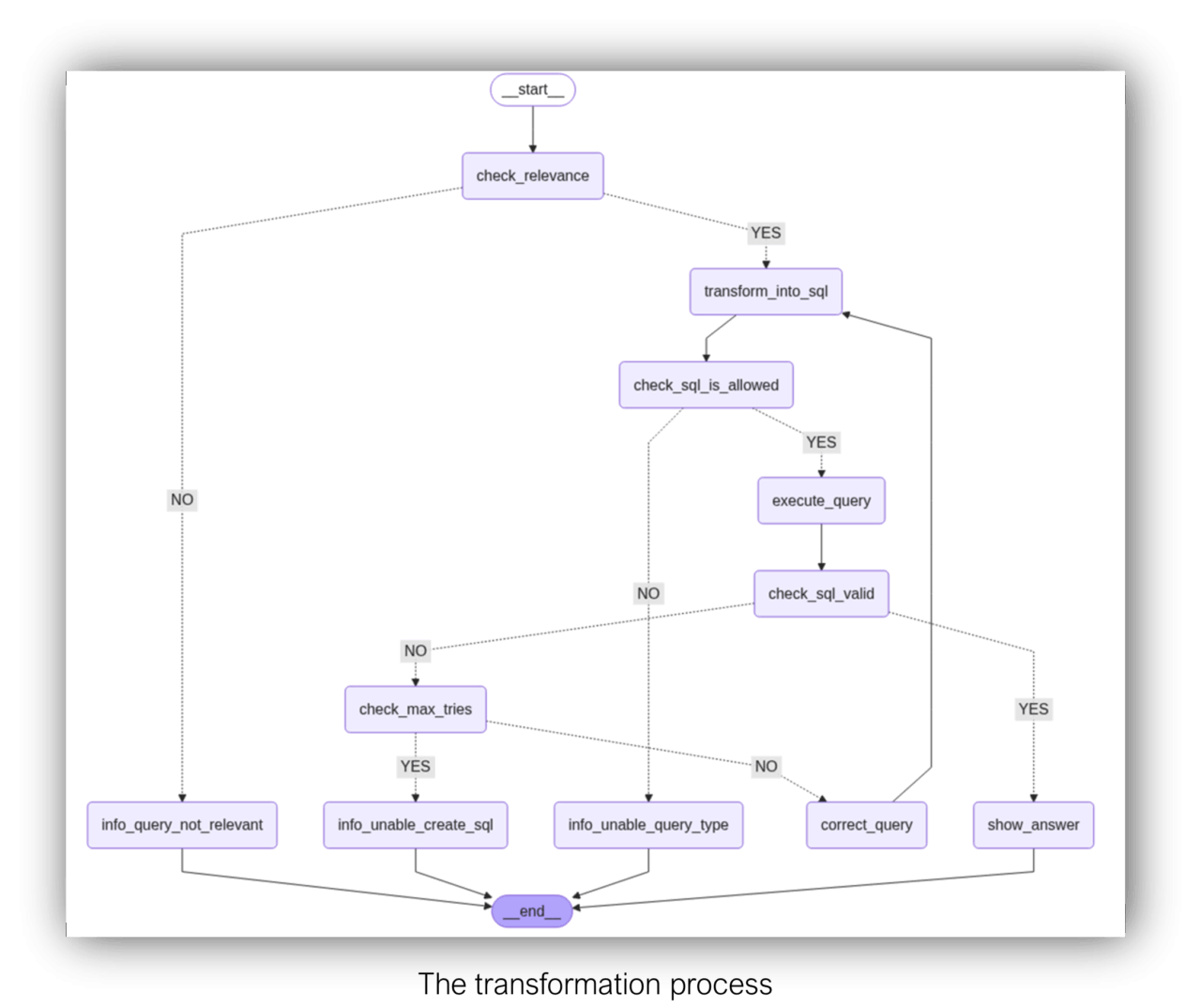
We implemented the transformation process based on the Langgraph framework (https://www.langchain.com/langgraph). The communication to the LLM Servers utilizes the OpenAI API, implemented with the langchain framework https://www.langchain.com). In addition to the functional blocks outlined above, we read the database schema and add it to the system prompt; this is a crucial step, as the LLM requires a solid understanding of the underlying database schema. The better the quality of the included metadata, the better the transformation result. Successfully executed SQL statements are stored in a Vector database, in our case ChromaDB, along with the natural language question and some other metadata. With every new natural language question, a similarity search is performed. Similar questions and their respective SQL statements will be added to the prompt as hints to the LLM.
The entire code for the Exasol MCP Server, including the Text-to-SQL option, is available on GitHub for free (see above).
Now, we have two important pieces of our solution in place: an on-premises LLM server with locally hosted LLMs, and we have an MCP Server with the capability of generating SQL statements from natural language. The last part is an AI desktop application that fully supports our local strategy. At the beginning of our search, we encountered some difficulties. Antrophic’s Claude AI Desktop runs perfectly with the MCP server, but when it comes to displaying the rendered result set, we were unsure if the data is not being sent to the Cloud as well. And sometimes when the transformation process encountered problems, Claude jumped in and helped to get the process running. Let’s be honest, this is a nice move, and for many use cases, a desired handling of problems. However, when you require the full confidentiality of your data, we recommend a different solution. And Claude can not be configured to use local LLMs, which, by the way, is understandable.
The AI Desktop application
Finally, we came across Open-WebUI (https://github.com/open-webui/open-webui), a web-based AI application that can interact with locally hosted LLMs via OpenAI’s API, supporting, in our case, both Ollama and LM-Studio. While it cannot address an MCP Server directly, the MCP Server can be used via a proxy server, which converts so-called OpenAPI calls from Open-WebUI to MCP calls. The proxy server is a small Python application that can be installed with a Python package manager. You can find the details at the GitHub page (https://github.com/open-webui/mcpo).
Below you see a simple test query for the RETAIL database schema, one of Exasol’s exemplary datasets. It requires multiple „JOIN“operations over three tables.
Show the top 3 articles based on units_sold for the area of Bayern and Hessen, show area, article name, product group, units sold, and revenue; use the RETAIL database schema.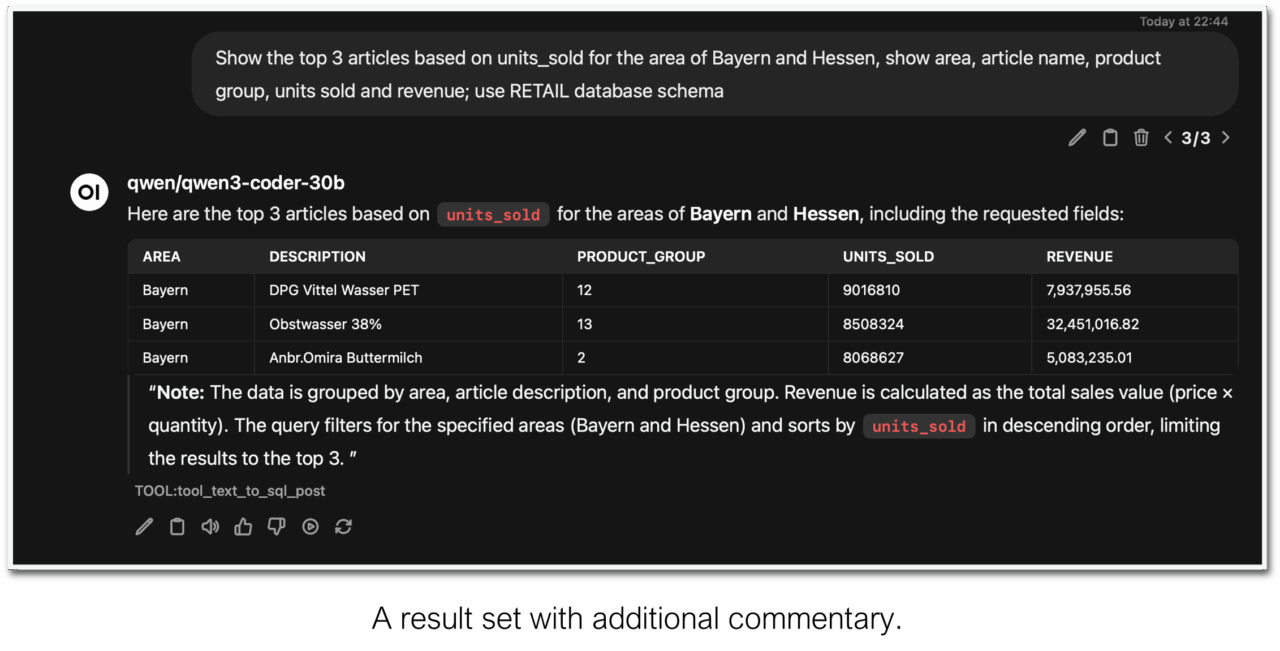
The table is the result of the rendering process during the transformation. We instructed the LLM to create a table in Markdown syntax from the result set, thereby controlling the output’s form. Interestingly, with Open-WebUI, we received some commentary about the result set, driven by the same LLM we deployed locally. If you want to get a result without the additional commentary, you need to instruct the LLM accordingly, as shown below:
We simply added
Do not comment to the end of our natural language question to instruct the LLM not to add additional comments.
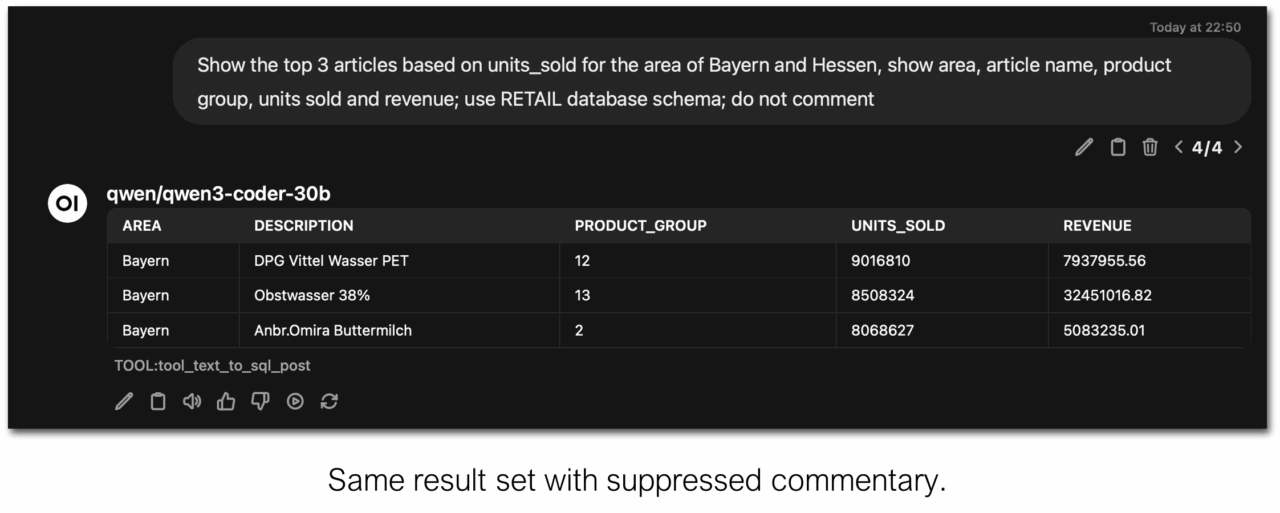
For our tests, the Qwen3-coder-30B LLM yields reasonably good results for both transforming natural language into SQL and rendering the result set into a table. However, you can configure different LLMs for each process step.
Below are a few examples of how a natural language question was translated into an SQL statement. For the first test, we asked a very simple question:
Show me the number of transactions in the RETAIL database schema?with the result SQL statement
SELECT
COUNT(*) AS TRANSACTION_COUNT
FROM
RETAIL.SALES_POSITIONSFor the next query, we examined the LLM’s ability to handle date extractions, as instructed in the system prompt. Also, several table joins are required for the correct result, and we can see that a correct GROUP BY clause is created
SELECT
a.DESCRIPTION AS PRODUCT_DESCRIPTION,
SUM(sp.AMOUNT) AS UNITS_SOLD,
SUM(sp.PRICE) AS REVENUE
FROM
RETAIL.SALES s
JOIN RETAIL.SALES_POSITIONS sp ON s.SALES_ID = sp.SALES_ID
JOIN RETAIL.ARTICLE a ON sp.ARTICLE_ID = a.ARTICLE_ID
JOIN RETAIL.MARKETS m ON s.MARKET_ID = m.MARKET_ID
WHERE
m.AREA = 'Hessen' AND
YEAR(s.SALES_DATE) = 2023 AND
to_char(s.SALES_DATE, 'uW') = '22'
GROUP BY
a.DESCRIPTION
ORDER BY
REVENUE DESC
LIMIT 3And finally, we checked with another database schema to see if our system prompt works across different database schemas by asking:
Show the top 5 routes with the most delayed flights between
departure city and destination city, include accrued minutes of
delay in the list; use the FLIGHTS database schemaSELECT
F.ORIGIN_CITY_NAME AS ORIGIN_CITY_NAME,
F.DEST_CITY_NAME AS DEST_CITY_NAME,
COUNT(F.DEP_DELAY) AS DELAY_COUNT,
SUM(F.DEP_DELAY) AS TOTAL_DELAY_MINUTES
FROM
FLIGHTS.FLIGHTS F
WHERE
F.DEP_DELAY > 0
GROUP BY
F.ORIGIN_CITY_NAME,
F.DEST_CITY_NAME
ORDER BY
DELAY_COUNT DESC
LIMIT 5resulting in the following table:

Of course, we cannot make any general statements based on the translation of three questions into SQL statements. We have made numerous translations, including presentations with prospects, customers, and partners. The hit rate of good SQL Statements is extremely high, close enough, but not 100%. The reasons are manifold, for example, the selection of the LLM or a non-ideal database design. If necessary, you can attempt to further enhance the quality of the translation process by adjusting the system prompt. It is a raw text file outside of the Python code. Alternatively, when the AI Desktop application allows, you can create workspaces for each use case and its underlying database schema, and augment the system prompt here with additional instructions. The user is no longer required to specify the database schema or other information that the translation process might need.
During a preparation meeting for a public market presentation, there was interest in natural language questions in German, with results presented in the same language. The model we used was able to understand the question, transform it correctly into SQL, and answer in the question’s language. We have asked again the FLIGHTS dataset to show the top five routes starting in Los Angeles with the most delayed flights:
Zeige mir die 5 Strecken mit den meisten verspäteten Flügen, die in
Los Angeles anfangen. Antworte in deutscher Sprache.This resulted in the following SQL Statement:
SELECT
ORIGIN,
DEST, COUNT(*) AS DELAYED_FLIGHTS
FROM
FLIGHTS.FLIGHTS
WHERE
ORIGIN = 'LAX' AND DEP_DELAY > 0
GROUP BY
ORIGIN, DEST
ORDER BY
DELAYED_FLIGHTS DESC
LIMIT 5and returned the following table and commentary:

There is one wrong word in the commentary – planes fly and do not drive. However, the meaning is still correct, and this can be considered a minor glitch.
Finally, the response time, from sending the question to receiving the result, can take a moment. First, the AI Desktop must identify the need to include an external tool. Then, the LLM, in conjunction with the translation process, must create the SQL and render the result. This is a computationally intensive task that benefits significantly from the use of GPUs. Do not expect sub-second response times, compared to a BI tool with pre-defined SQL statements, e.g., when using Dashboards. Without any exception, the queries created during our tests returned a result within a sub-second response time. In the event of a missing search index for a particular SQL statement, returning a result set took a bit longer, as a new index had to be created on the fly without any user interaction—a testament to flexibility at its best. The database schema sizes we used for tests range from a few million records to several billion records.
Auditing
You have two very different options for auditing your questions and the resulting SQL statements. The first option is to search in the log file you specified in the „.env“ file with the logging mode set to „DEBUG“. The second and preferred option would be to use the AI Desktop application and use the „SQL History“ tool of the MCP-Server. As we store every single successful combination of a question and its corresponding SQL statement in a vector database, we can easily search for a list or search for SQL statements. Here you can list a number of SQL queries, or search for text phrases in your questions.
For the following question:
Show me all SQL statements where I use the term “busiest” we got back the following list:
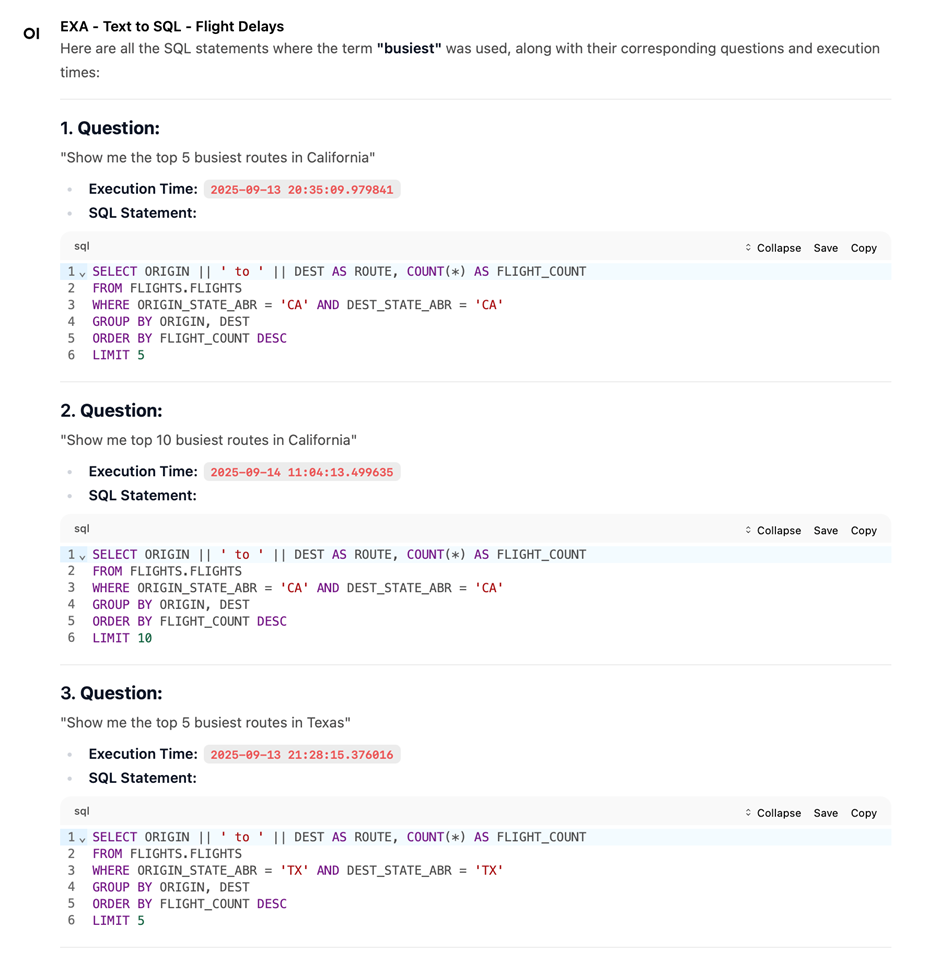
The tool expects the search text (defaulting to „*“), the name of the database schema, and the number of SQL statements to return. In our case, we limited it to 10 SQL statements by default. By using an individual workspace for the FLIGHT DELAYS use case, we have already preset the database schema.
Conclusion
Our statement, „Text-to-SQL is dead” is a valid statement for certain user groups where confidentiality is a strict requirement. No data may leave the premises, and we have shown how to circumvent the situation. However, the quality of the translation into SQL statements depends not only on the transformation process, but also on the design of the desired database schema(s) used for queries/questions. The better the design, the better the quality of Text-to-SQL. You have to do your homework before thinking about Text-to-SQL, or you have a high chance of failing. To further enhance the quality of the translation process, consider utilizing a Semantic Layer.
In our interest again, you can achieve quite remarkable results if you do it right. Nevertheless, you will encounter SQL statements that do not correspond to the question asked. Cross-check the results and be cautious.
Interestingly, there is a second noteworthy point. With the Text-to-SQL option, you are losing control of the queries. While queries for Reports or Dashboards are static or semi-static, queries from natural language are highly dynamic. There is no guarantee that an appropriate search index exists for a newly created SQL statement. Exasol and its Automatic Index Management feature mitigate this problem out of the box. In other words, automatic index management is a must-have requirement for every Text-to-SQL transformation, particularly in terms of usability and user acceptance. For us, it is safe to state that Exasol and Text-to-SQL are a natural fit -> „Long live Text-to-SQL“ as „Governed SQL“
Happy Exasoling!