From Data Federation to Continuous Intelligence: How Virtual Schemas Power AI‑Ready Analytics
As organizations grow, the temptation is to centralize everything: “Let’s just load it all into the data warehouse.” But this approach is increasingly impractical. Data now lives everywhere (across Data Lakes, SaaS platforms, operational databases, cloud storage, APIs, and more). Moving all of it is expensive, slow, and often unnecessary. Sometimes you only need a small subset, or you want the freshest data without waiting for nightly ETL jobs. Sometimes, regulatory or sovereignty reasons mean you can’t move it all. And sometimes, the cost of duplicating rarely used data just doesn’t make sense.
The reality is: not all data needs to live in your warehouse. What you need is flexible, up-to-date access—without the baggage of endless ETL and ballooning storage bills. Enter the virtual schema; the mechanism that lets you access and analyze distributed data without duplication. In a world where data sprawls across dozens of systems, platforms, and clouds, it’s the invisible glue that lets organizations query, analyze, and govern information as if it lived in one place.
What Is Virtual Schema Management?
At its core, a schema is a blueprint: it describes how data is structured (tables, columns, types, relationships). It is the practice of defining, integrating, and maintaining data structures (schemas) across a distributed landscape. A virtual schema takes this concept further. Instead of requiring all data to be physically loaded into a single warehouse, a virtual schema creates an abstraction layer. This is crucial in today’s world of cloud data warehouses, data lakes, SaaS integrations, and hybrid environments. Unlike traditional schema management, which is tied to a single database or warehouse. It lets you connect to third-party databases (think MySQL, Oracle, Databricks), data files (Parquet, JSON, CSV), and even APIs, and query them as if they were part of your local environment. Modern platforms like Exasol make this process seamless and extensible; users can even develop their own adapters for custom sources like DuckDB. This approach means you can unify, analyze, and govern data, regardless of location or format, without the heavy lifting of ETL and data migration.
Virtual Schemas act as a logical data warehouse, providing live, compliant access to federated data sources while minimizing storage cost and enabling instant analytics. This is especially powerful with:
- Unified access and data federation: Virtual Schemas act as a logical data warehouse, allowing you to query live data from databases, files, or APIs as if the data were native to Exasol.
- Up-to-Date Access: Query the freshest data at source, no dependency on outdated snapshots.
- Cost Efficiency: Reduce storage by avoiding duplication, and eliminate complex ETL overhead.
- Compliance & Sovereignty: Keep sensitive or regulated data in its original system while still joining it securely through the Exasol engine.
- Rapid prototyping and experimentation: Analysts and data scientists can plug new sources into Exasol within minutes, enabling immediate exploration, dashboarding, or model testing without a full integration project.
- Extensible architecture: Through the Exasol Java SDK, developers can build custom adapters to connect niche or proprietary systems, broadening the reach of the Virtual Schema framework. Supported connectors include JDBC sources, Parquet, JSON, CSV files, and REST APIs, plus the flexibility to integrate with engines such as DuckDB or Athena.
Take, for instance, a common scenario faced by data‑driven enterprises operating at scale: massive volumes of historical and streaming data distributed across multiple systems, continuously growing in size and complexity. Traditional data warehousing models (based on replication and heavy ETL) struggle to meet modern analytics and AI needs, where models must learn, adapt, and redeploy faster than ever. To address this, organizations are increasingly turning to Virtual Schemas as a strategic connective layer across their data ecosystem. Instead of centralizing everything, they create a unified analytical perspective across databases, APIs, and cloud sources. This logical data fabric keeps all information where it originates while allowing data scientists and analysts to query, join, and experiment in real time. As more organizations adopt Virtual Schemas, the next logical question is: how can AI make them smarter?
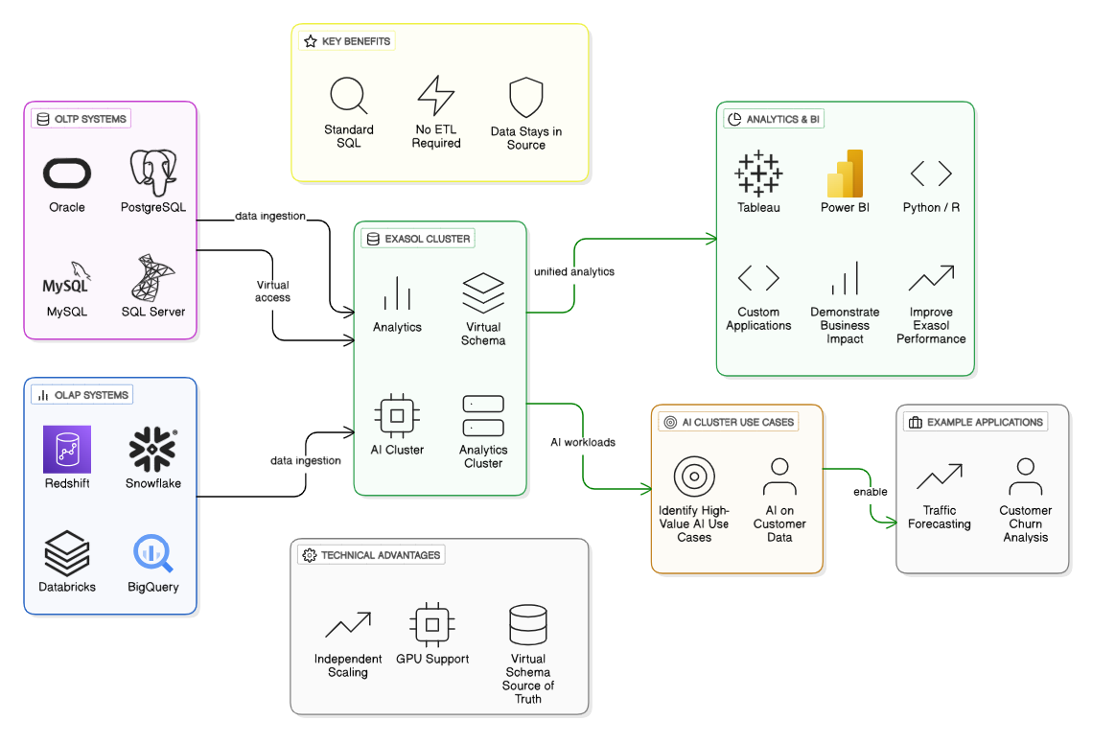
Imagine this structure powering a predictive forecasting workflow. A data science team wants to forecast weekly demand volatility, resource utilization, or energy consumption using multiple historical streams that live in different systems. Through Virtual Schemas, they can federate those datasets immediately (eliminating the cost and delay of physical movement) then orchestrate model development directly on top of live data connections. Once federated, the data can flow into a dedicated Exasol AI Cluster environment for predictive modeling and simulation as shown in the figure. Within this framework, compute for analytics and AI scales independently. The analytics cluster aggregates and curates the data, while the AI cluster (which can also be accelerated by GPUs) handles model training, retraining, and inference. Continuous access to complete and current datasets enables models to adjust dynamically to new patterns (seasonal shifts, operational fluctuations, or market variability) without the typical latency or risk introduced by manual data movement. This architecture doesn’t just improve performance, it introduces resilience and adaptability that align with broader industry trends.”
This design also reflects what Gartner calls a composable data‑fabric approach, one capable of unifying real‑time data access, AI readiness, and governance at scale. By merging Virtual Schema federation with flexible AI architectures, organizations create a foundation for continuous intelligence: systems that don’t just analyze what has happened but autonomously prepare for what’s next.
The Road Ahead
While AI-powered schema management is still in early exploration, its potential impact on virtual schema management is clear. Emerging concepts include:
- Automated Schema Discovery: Using ML to infer table relationships or mappings across disparate sources.
- Drift Detection: AI models can identify when a connected schema changes and flag inconsistencies automatically.
- Query Optimization: Predictive indexing or AI-guided pushdown recommendations that refine where queries execute for maximum speed and efficiency.
Some of these ideas are still in experimentation, but the foundations are being laid. Exasol’s lightweight Virtual Schema framework already makes it possible to test AI-assisted logic without touching physical data or architecture. The next phase focuses on smarter orchestration: schema evolution monitoring, automated optimization recommendations, and tighter integration between analytics and AI clusters. But as always, each step will be pragmatic, tested, and customer‑driven. The Exasol AI Cluster is a great example of this evolution. It already separates analytics from AI compute while maintaining a single source of truth via Virtual Schemas. For Exasol, the opportunity lies in evolving Virtual Schemas, the proven backbone of our logical data federation, toward intelligent automation. Virtual Schemas already unlock cost savings, real‑time access, and seamless federation.
To keep experimentation safe and practical, any AI assist should follow a validation checklist:
- Maintain human-in-the-loop oversight for mapping approvals.
- Run lineage impact analyses to track dependencies before applying schema updates.
- Keep a rollback plan ready for automatic reversion.
Evaluate precision and recall metrics to measure real-world accuracy of AI inferences.
What’s Happening in the Industry
In 2024, Gartner predicted that “by 2027, 70% of enterprise data integration will be augmented by AI‑driven tools, up from less than 20% in 2023.” That momentum is already visible. The industry is moving from manual complexity toward adaptive orchestration, ensuring that data pipelines, schemas, and governance processes continuously learn and improve. The wider data ecosystem is moving in the same direction, embedding AI within core data‑management workflows:
- Databricks Unity Catalog now applies AI for data lineage visualization, impact analysis, and schema governance, making complex multi‑cloud data easier to audit and trust.
- Google BigQuery integrates AI for automated schema inference and natural‑language querying, helping users explore data intuitively.
- Snowflake is deepening partnerships with AI vendors to deliver intelligent data cataloging and automated schema mapping.
- Open‑source platforms such as dbt are experimenting with AI plug‑ins for dynamic documentation and version‑aware schema change analysis.
Exasol, meanwhile, focuses on performance and practicality, enabling enterprises to scale Virtual Schemas across databases, data lakes, and APIs today, while exploring AI to add intelligence and automation tomorrow.
In Closing
Virtual Schemas have redefined how organizations federate, analyze, and govern data across silos. The evolution toward AI‑assisted management isn’t about replacing human expertise, it’s about amplifying it through automation, learning, and smarter insights. At Exasol, the mission remains clear: deliver high‑performance analytics with an intelligent foundation. Today, that’s real‑time Virtual Schemas; tomorrow, it’s a more autonomous, AI‑aware data fabric: built responsibly, tested in practice, and always centered on value for the user.
Happy Exasoling!