
Is DuckDB Ready for Primetime? A Friendly Reality Check from the Enterprise Trenches

TL;DR
DuckDB is the most delightful thing to happen to analytical SQL since SELECT 1. It’s fast, tiny, and absurdly easy to use. But when you stack it against an industrial-strength analytics database like Exasol, especially under real workloads with concurrency and scale in mind, the gap is still meaningful. In our TPC-H-style tests (PDS benchmark) on a beefy single machine, Exasol ran more than 4× faster than DuckDB across 10/30/100 GB. And beyond speed, Exasol reliably handles multi-user concurrency and scales horizontally across nodes, where DuckDB’s design today is single-node and mostly single-user.
You can love DuckDB (we do!) and still admit: it’s not a cluster database, and even for single node workloads, it still has room for improvements.
Why DuckDB Won the Hearts (and Benchmarks) of Devs
Let’s start with praise where it’s due, because DuckDB earned it:
- Zero friction. pip install duckdb and you’re querying Parquet in seconds. No cluster to babysit, no daemon to appease.
- Ergonomics > ceremony. Jupyter + Python + DuckDB feels like cheating. It’s the SQLite of OLAP, in the best possible way.
- Great defaults. You get vectorized execution, parallelism on a single box, and a storage story that makes local data feel like a “database” without the database.
- Dev velocity. The project’s pace is… brisk. Features show up, docs improve, and the community is vibrant.
If Hacker News had a macro for “just use DuckDB,” it would trigger on any thread that mentions Parquet, ad-hoc analytics, or notebooks. That enthusiasm is deserved.
But here’s the spicy bit: being a fast single-node, single-user engine in a notebook is not the same thing as being a database for large, shared, mission-critical workloads.
The Setup: Community-Style TPC-H, Same Rules for Everyone
TPC is the industry standard for database benchmarking. We would have liked to use the TPC-H benchmark for this test, which is a classic decision-support benchmark that runs 22 parameterized SQL queries intended to stress large scans, multi-way joins, heavy aggregation, and sorting, but it is sadly not available for DuckDB in its full form at this time.
So instead we used the Polars Decision Support (PDS). PDS is an open, community harness inspired by TPC-H that keeps the same 22 query templates but simplifies everything around them. Crucially, PDS is not TPC-H compliant. It doesn’t run the official Power/Throughput mix with randomized query streams, it doesn’t execute refresh functions (RF1/RF2 inserts/deletes), and it doesn’t do audits or price/perf. Treat it as a TPC-H-style microbenchmark that’s easy to reproduce across engines and great for apples-to-apples query runtime comparisons on a single machine. The maintainers explicitly state that PDS results are not comparable to published TPC-H numbers.
We used PDS here because we wanted something open, scriptable, and reproducible that the community already recognizes, so we added native Exasol support to PDS and ran DuckDB and Exasol with the exact same data, SQL, and orchestration. This isolates the question “how fast does each engine execute these 22 decision-support queries on one box?” while acknowledging that official TPC-H covers more (notably multi-user concurrency and refresh), which we discuss separately because those are precisely the areas where MPP databases differentiate.
- Hardware: Single AWS c7a.24xlarge (96 vCPU, 192 GiB RAM).
- Scale factors: 10 GB, 30 GB, 100 GB.
- Engines highlighted here: DuckDB 1.3.1 vs Exasol 8.29.10.
(We also tried Polars and Dask; they were either slower or failed specific queries. Interesting in its own right, but a tangent here.)
Yes, benchmarks are messy. Yes, your mileage may vary. Yes, we all have that one query that wins on our favorite engine. We’re not claiming “universal truth,” just reporting what we saw with a setup you can re-run.
Results: The Fast-and-Fun Upstart vs the Battle-Hardened Workhorse
Per-Query Runtimes
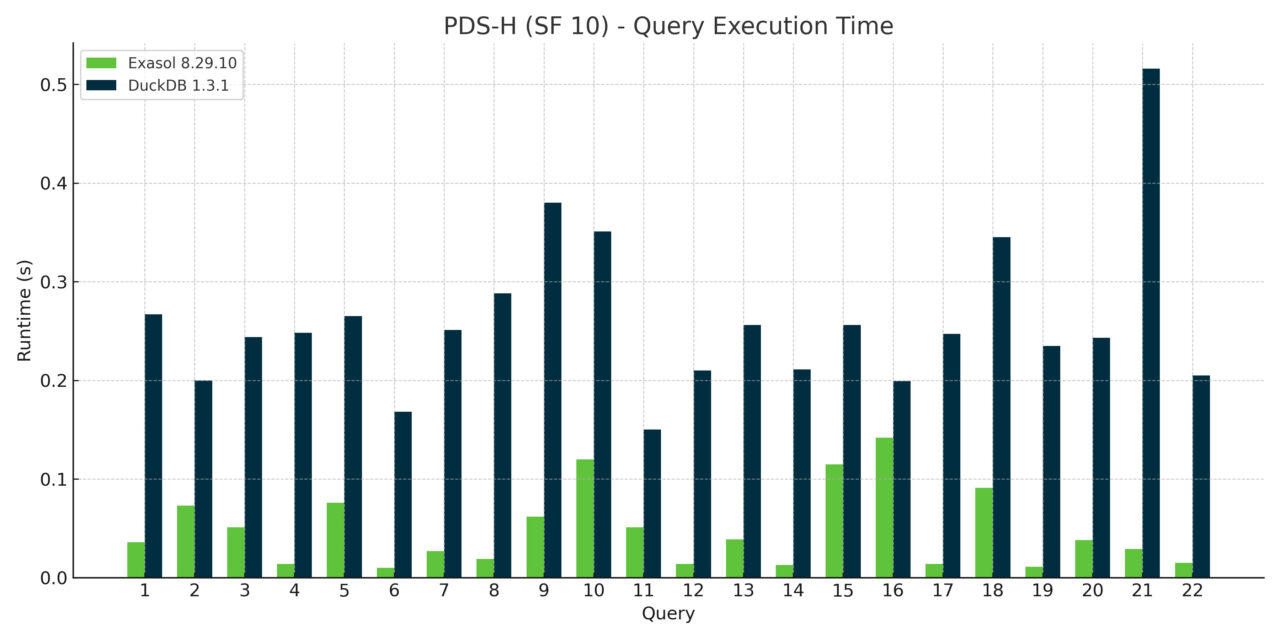
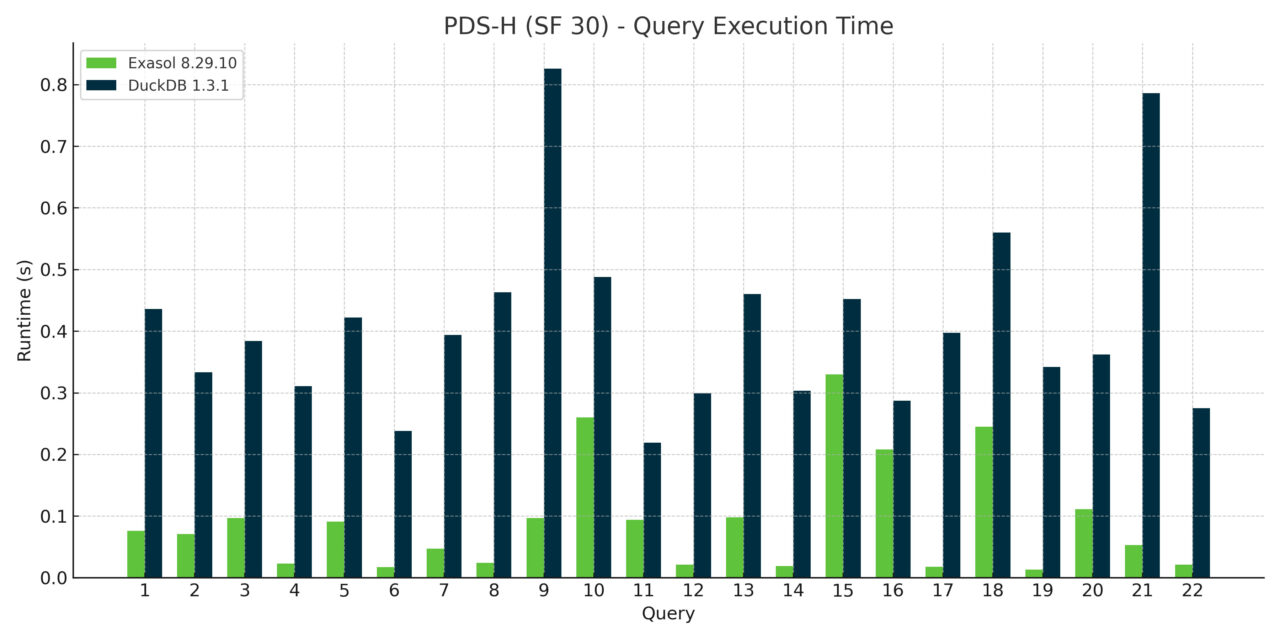
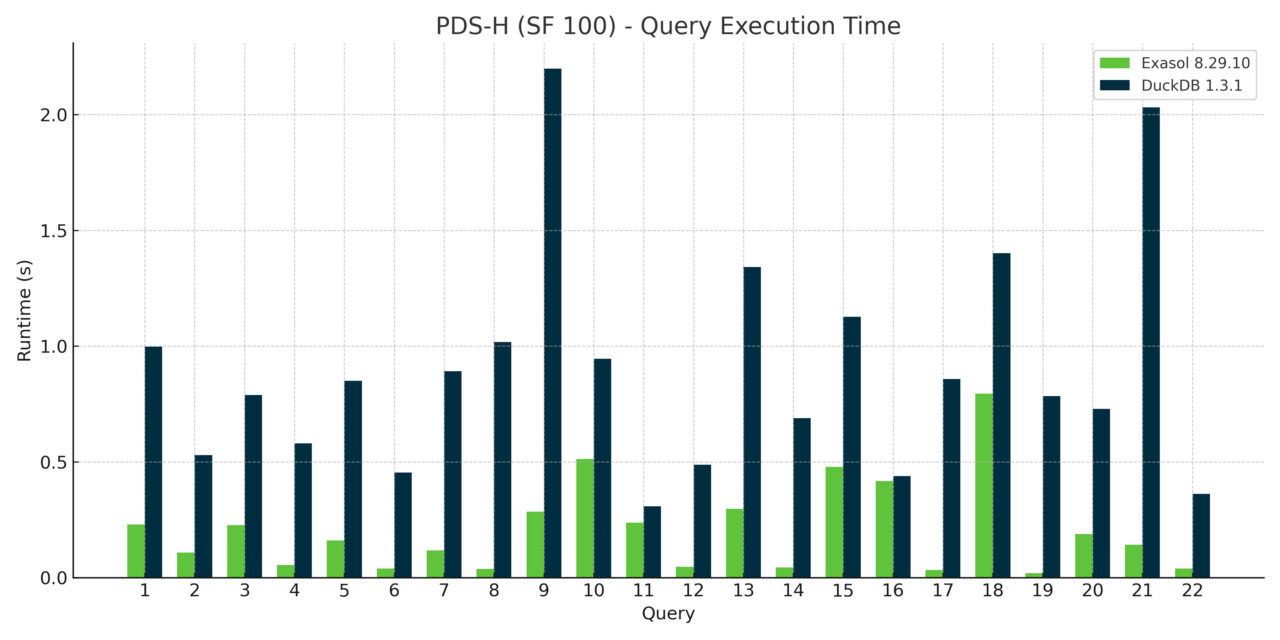
Across the 22 TPCH queries, Exasol consistently beat DuckDB at every scale factor. While some queries were comparable, most weren’t even close. The pattern was clear: as data sizes grew and query plans got gnarly, Exasol’s cost-based optimizer and execution engine pulled away.
Total Runtime
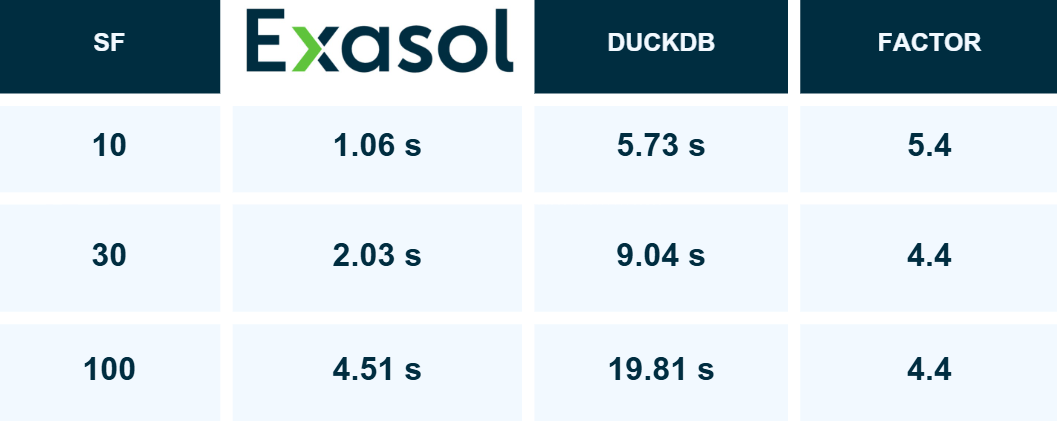
Add it up and the story is blunt:
Exasol was more than 4× faster than DuckDB at 10 GB, 30 GB, and 100 GB total runtime.
These are single-machine runs, and DuckDB is optimized for exactly that environment, so you would expect it to be a slam-dunk in that setup. The surprise (for some) is that Exasol’s distributed MPP DNA also translates to a single box and easily outdistances embedded databases like DuckDB. You don’t have to spin up a cluster to see Exasol go fast.
The Part Nobody Likes to Talk About: Concurrency and Scale
Everybody loves clean microbenchmarks. Production databases love chaos.
Concurrency: DuckDB can parallelize a query, sure. But it’s not built to juggle lots of independent users and workloads at once. Locking, workload management, admission control—these are the unsexy daggers that decide whether your BI team is happy or slacking on Slack. Exasol excels here.
Scale-up vs scale-out: DuckDB’s design today is single-machine. You can buy a bigger box, but there’s a ceiling. Exasol scales horizontally across any number of nodes with shared-nothing MPP. So when your CEO decides “all dashboards should refresh in 30 seconds,” over terabytes of data, you can add nodes instead of prayers.
Operational resilience: The PDS harness doesn’t probe ACID across failures, redo/logging, or mixed workloads with writes and schema changes. Enterprise databases live in that world daily. DuckDB wasn’t designed for it; Exasol was.
If your problem is “query a pile of Parquet files quickly from a notebook,” DuckDB is magic. If your problem is “thousands of users, hundreds of reports, and SLAs,” you’ll want an engine that treats concurrency, distribution, and fault tolerance as first-class citizens.
So… Is DuckDB “Ready for Primetime”?
Define “primetime.”
For individual analysts, data scientists, and embedded analytics inside apps: Absolutely. DuckDB has changed the default answer from “just load it into a warehouse” to “just run it right here.” That’s a massive usability innovation, and it’s reshaping developer workflows.
For multi-team, always-on, high-concurrency analytics at company scale: Not yet. It’s ~4× slower than Exasol in our tests, lacks serious multi-user concurrency controls, and doesn’t scale out.
That’s not a dunk; it’s just design intent. DuckDB wasn’t built to be your data warehouse. It was built to be your local OLAP scalpel. And it’s a very, very good scalpel.
Why Exasol Pulled Ahead (Even on One Box)
- Mature cost-based optimizer that’s been tuned on analytical workloads for years.
- Vectorized, in-memory execution with aggressive pipelining.
- Shared-nothing MPP architecture that doesn’t get confused when you ask it to handle 1 user or 1,000.
- Proven concurrency & workload management, the stuff you only miss when it’s 9:05 AM and every dashboard in the company just fired.
Exasol has topped official TPC results for nearly two decades (TPC is the only neutral, governed benchmark consortium). The community TPC-H-style tests don’t cover everything TPC does (multi-user randomness, DML under load, failure handling, etc.), but they still tell a meaningful performance story. Here, that story favored Exasol.
What This Means for You
If you live in notebooks: Start with DuckDB. You’ll move faster and ship more.
If you run shared analytics for teams: Reach for a true database, Exasol in our case, because concurrency and horizontal scale aren’t optional features; they’re the job.
If you’re somewhere in between: Use both. DuckDB for local exploration, Exasol for productionized analytics and large data sets. The handoff is painless if you keep your SQL honest.
Caveats, Because We’re Not Monsters
- Benchmarks are indicative, not definitive. Change hardware, schemas, data distributions, or query variants, and relative performance will shift.
- This write-up emphasizes read-heavy analytics. OLTP and mixed workloads are different animals.
- DuckDB’s roadmap moves fast. Some gaps may narrow. (We’ll happily re-run when they do.)
Reproduce It (Please Do)
- Benchmark harness: Polars Decision Support (PDS), with our Exasol integration (PR upstreamed).
- Data scales: 10/30/100 GB.
- Engines: DuckDB 1.3.1 vs Exasol 8.29.10.
- Hardware: c7a.24xlarge, 96 vCPU, 192 GiB RAM.
Grab the PDS repo, point it at both engines, and let it rip. You can download the Exasol Community Edition to try this on your own machine or cloud instance. If you want our exact scripts/configs, ping us. We’ll share.
Final Take
DuckDB is the friendliest on-ramp to analytical SQL in years. It’s pushed the whole industry to be more usable, more local, and more fun. That’s a gift.
Exasol is what you deploy when the fun has to scale. It’s faster in our tests, even on a single machine (4× overall), handles real concurrency, and grows horizontally to meet even the largest demands. Both can be “right”, just for different jobs.
It’s not pocketknife vs. power drill. It’s pocketknife and power drill. Use the right tool, get more done, and save the flamewars for those who are still sitting around waiting for their queries to return.