What Is Denormalized Data? (Denormalization Explained)
Mathias Golombek
·
·
13 mins read
Denormalization is a database design technique that intentionally introduces controlled redundancy into a schema to reduce join operations and improve read performance in specific workloads. Engineers apply denormalization when query execution time is dominated by join cost or when read latency is more critical than storage efficiency.
Denormalization builds on a normalized design and selectively duplicates or aggregates data to optimize query execution. These structural decisions relate to core relational database concepts such as entity relationships, keys, and integrity constraints.
In analytical environments powered by systems such as the Exasol Analytics Engine, schema design directly affects how efficiently large joins and aggregations execute. Understanding when to normalize and when to selectively denormalize is central to database performance optimization.
In a normalized schema, related data is distributed across multiple tables to eliminate redundancy and enforce data integrity through well-defined relationships. Denormalization does not abandon normalization principles. Instead, it builds on a normalized design and selectively duplicates or aggregates data to optimize query execution.
The trade-off is structural. Denormalization reduces join overhead during reads but increases storage consumption and write complexity. When redundant data changes, multiple rows may require updates. Without proper constraints or maintenance logic, this can introduce update anomalies or inconsistencies.
Denormalization is commonly used in:
Data warehouses with star or snowflake schemas
Reporting systems with heavy aggregation workloads
High-read environments where query latency affects user experience
Precomputed materialized views or summary tables
It is a deliberate performance optimization strategy, not a shortcut around database theory. Teams use it when workload characteristics justify the cost of redundancy.
Denormalization should never be the first optimization step. Indexing and query tuning should precede structural redundancy.
Dirk Beerbohm, Global Partner Solution Architect
Test Real Analytical Workloads with Exasol Personal
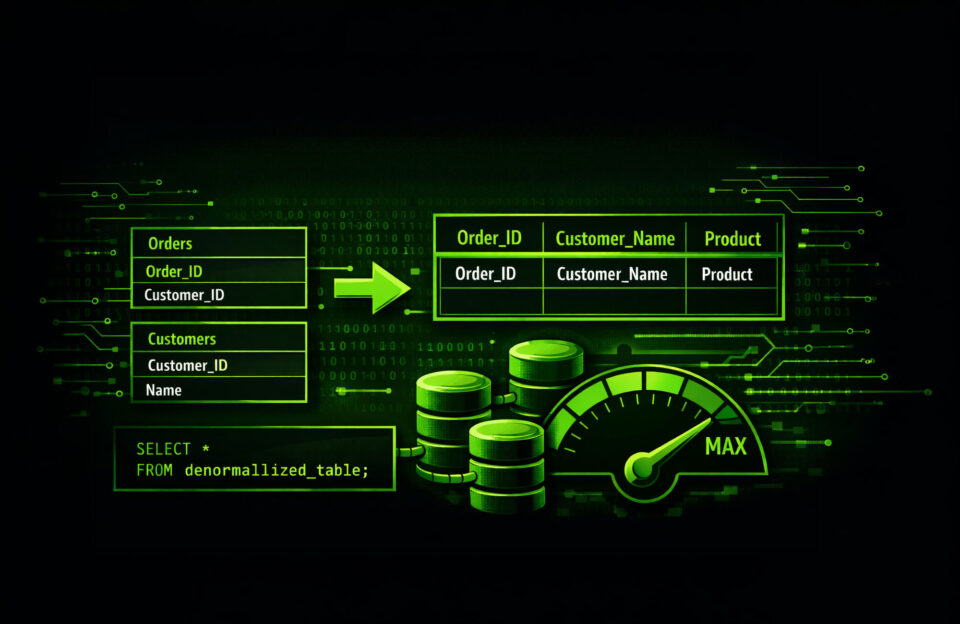
Denormalized data is data that has been intentionally duplicated or combined across relational tables to minimize runtime joins. Instead of retrieving related attributes through foreign key relationships at query time, the schema stores frequently accessed attributes together.
Consider a normalized design:
customers
orders
order_items
Retrieving full order details requires joins across these tables. A denormalized variant may embed selected customer attributes directly in the orders table:
This reduces join operations during read queries. Analytical scans that process large volumes of data often benefit from this structure because fewer relational lookups are required.
Denormalized data reflects a workload-driven design decision. The schema favors read efficiency and simplified queries over strict minimization of redundancy. The cost shifts to maintenance: updates must ensure that duplicated values remain consistent across the dataset.
Data consistency is managed through application logic, triggers, or batch updates
It is a performance optimization technique grounded in trade-off analysis, not a replacement for normalization theory.
Normalization vs Denormalization
Normalization and denormalization address different performance priorities in relational database design. Normalization minimizes redundancy and enforces structural integrity. Denormalization introduces controlled redundancy to reduce join cost and improve read performance.
Both approaches are valid. The correct choice depends on workload characteristics, update frequency, and performance constraints.
Factor
Normalization
Denormalization
Data Redundancy
Minimized
Intentionally introduced
Table Structure
Split across related tables
Combined or partially flattened
Join Usage
Required for related data
Reduced or eliminated for common queries
Storage Usage
Lower
Higher
Write Complexity
Lower per entity change
Higher due to multi-row updates
Read Performance
May degrade with complex joins
Often improves for read-heavy workloads
Data Integrity
Enforced through normalization forms
Requires careful update logic
Normalization organizes data into logical entities and relationships within the relational database model.
The relational model, introduced by Edgar F. Codd in 1970, established the theoretical foundation for modern relational database systems and normalization theory. Each fact is stored once. Foreign keys connect related records. This design reduces update anomalies and enforces consistency.
Denormalization changes that balance. It merges or duplicates selected attributes so queries can retrieve required data with fewer joins. The schema becomes optimized for retrieval patterns rather than structural purity.
Performance Implications
In normalized schemas, queries that combine multiple entities rely on joins. For large datasets, joins can increase:
CPU usage
Memory consumption
Disk I/O
Query planning complexity
Denormalization reduces join overhead by storing frequently accessed attributes together. For read-heavy workloads, especially analytics, this can reduce execution time.
However, write operations become more complex. When a duplicated attribute changes, multiple records may require updates. Without transaction control or application safeguards, inconsistencies can occur.
The structural trade-off remains constant: denormalization simplifies reads while increasing write complexity and redundancy management.
Denormalization in SQL
Denormalization in SQL typically involves restructuring tables or precomputing data to reduce runtime joins. In relational systems built on standard SQL syntax and operations, the goal is not to eliminate relational structure entirely, but to shift complexity away from query execution and toward data preparation.
There are several common implementation patterns.
1. Embedding Redundant Columns
The simplest form of denormalization adds frequently accessed attributes directly into another table.
Example: storing customer_nameinside the orderstable.
This removes the need for a join when retrieving order summaries. The schema trades storage efficiency for query simplicity.
However, when a customer changes their name, every affected order row must also be updated. Without transactional safeguards, inconsistencies can occur.
2. Precomputed Summary Tables
Another pattern creates aggregate tables designed specifically for reporting.
Example:
CREATE TABLE monthly_sales_summary AS
SELECT DATE_TRUNC('month', order_date) AS month,
SUM(total_amount) AS total_revenue
FROM orders
GROUP BY DATE_TRUNC('month', order_date);
Instead of recalculating aggregates during every query, the system queries the precomputed table.
This approach improves performance for recurring analytical queries. The trade-off is maintenance overhead. The summary table must be refreshed periodically to remain accurate.
3. Materialized Views
Many relational database systems support materialized views. A materialized view stores the result of a query physically, rather than computing it dynamically each time.
Conceptually:
CREATE MATERIALIZED VIEW order_customer_view AS
SELECT o.order_id,
o.order_date,
c.customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;
The database can refresh the view automatically or on demand, depending on the engine.
Materialized views represent a structured and controlled form of denormalization. They preserve the logical normalization of base tables while optimizing read performance.
4. Join Elimination via Table Flattening
In some cases, teams create flattened reporting tables that combine multiple dimensions into a single wide table.
For example:
CREATE TABLE order_report AS
SELECT o.order_id,
o.order_date,
c.customer_name,
p.product_name,
oi.quantity,
oi.price
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id;
This structure supports fast reporting queries because all relevant attributes exist in one place. The downside is data duplication and increased storage.
Maintenance Considerations in SQL
When implementing denormalization in SQL:
Use transactions to maintain consistency during updates
Consider triggers to synchronize redundant attributes
Schedule refresh jobs for summary tables
Evaluate indexing strategy carefully
Denormalization improves read performance only when it reduces meaningful execution cost. Poor indexing or inefficient refresh strategies can offset any gains.
Denormalization in DBMS Architecture
Denormalization affects more than table structure. It changes how the database engine allocates resources, executes queries, and manages storage. The impact depends on the storage model and execution engine characteristics across different database types, including row-based transactional systems and columnar analytical engines.
Impact on Query Execution
In a normalized schema, the optimizer must evaluate join strategies:
Nested loop joins
Hash joins
Merge joins
Each join introduces CPU cost, memory allocation for intermediate results, and potential disk I/O. For large datasets, join execution can dominate total query time.
Denormalization reduces or removes some of these joins. The optimizer operates on fewer relations, which can simplify execution plans and reduce intermediate data structures.
However, modern cost-based optimizers are highly efficient. On well-indexed OLTP systems with small row counts, join overhead may be negligible. Denormalization provides the most benefit when:
Tables contain millions or billions of rows
Queries scan large portions of data
Aggregations occur frequently
Workloads are read-heavy
Test Real Analytical Workloads with Exasol Personal
Denormalization increases redundancy. In row-based storage engines, this directly increases disk usage.
In columnar engines, the effect can differ. Columnar compression often reduces the storage penalty of repeated values. For example, dictionary encoding can compress repeated attributes efficiently. In such systems, denormalization may increase logical redundancy without proportionally increasing physical storage.
This is one reason denormalization is common in analytical databases and data warehouses.
Write Path and Consistency
Denormalization shifts complexity to the write path.
When a duplicated attribute changes:
Multiple rows may require updates
Index maintenance increases
Transaction size may grow
Lock contention risk may increase
In high-write transactional systems, this can degrade performance. Update anomalies become a real operational risk if synchronization logic fails.
For OLTP workloads with frequent updates, strict normalization usually remains preferable.
Hybrid Architectures
Most production environments do not choose exclusively between normalization and denormalization. Instead, they separate workloads.
Common pattern:
Core transactional database → normalized schema
Analytics layer or warehouse → denormalized schema
Reporting tables → pre-aggregated or flattened
This separation allows each layer to optimize for its dominant workload characteristics.
Workload-Driven Decision Model
Choosing denormalization should be driven by measurable factors:
Ratio of reads to writes
Average query latency
Join cost observed in execution plans
Storage constraints
Consistency requirements
Denormalization is justified when performance bottlenecks are demonstrably linked to join overhead or repeated aggregations.
It is not a substitute for indexing, query tuning, or proper schema design. It is a structural optimization applied when other techniques are insufficient.
Pros and Cons of Denormalization
Denormalization introduces measurable benefits and measurable risks. The decision should be based on workload characteristics rather than preference.
Advantages of Denormalization
1. Faster Read Queries
Reducing joins can lower CPU usage and memory allocation during query execution. Analytical queries that scan large datasets often benefit from simplified execution plans.
2. Lower Join Overhead
Fewer joins reduce intermediate result sets and hash table construction in large-scale queries.
3. Simplified Query Logic
Applications can retrieve required attributes from a single table without complex join clauses. This can reduce query planning complexity and improve readability.
4. Improved Reporting Performance
Pre-aggregated or flattened tables reduce the need to compute expensive aggregations repeatedly.
5. Better Fit for Analytical Workloads
In data warehouse environments, denormalized schemas (such as star schemas) align well with read-heavy, aggregation-driven queries.
Disadvantages of Denormalization
1. Increased Storage Usage
Redundant attributes consume additional disk space. In row-based engines, this can grow quickly with large datasets.
2. Higher Write Complexity
When duplicated values change, multiple rows must be updated. This increases transaction size and maintenance overhead.
3. Risk of Update Anomalies
If synchronization logic fails, redundant attributes can diverge. This creates data inconsistency.
4. More Complex Maintenance
Triggers, batch refresh jobs, or application-level logic may be required to maintain data accuracy.
5. Potential Lock Contention
Large multi-row updates in denormalized tables can increase locking and impact concurrency in high-write systems.
Test Real Analytical Workloads with Exasol Personal
From runtime computation → to storage and synchronization
From relational joins → to redundancy management
It is most effective when:
Reads significantly outnumber writes
Join cost is a proven bottleneck
Reporting latency is critical
Controlled redundancy is acceptable
It is less appropriate when:
Write frequency is high
Data consistency requirements are strict
Storage constraints are tight
Transactional integrity dominates system design
Denormalization should follow empirical analysis. Execution plans, workload metrics, and performance profiling should guide the decision.
When Should You Use Denormalization?
Denormalization is justified only when measurable performance constraints outweigh the cost of redundancy. The decision should follow workload analysis, not theoretical preference.
Below is a practical decision framework.
1. Read-Heavy Workloads
Denormalization is appropriate when read operations significantly outnumber write operations.
Indicators:
Analytical dashboards refresh frequently
Reporting queries scan large datasets
API endpoints serve aggregated data repeatedly
Query latency directly affects user experience
If write frequency is low relative to read frequency, the maintenance cost of redundancy may be acceptable.
2. Join Cost Is a Proven Bottleneck
Before denormalizing, examine execution plans.
Look for:
Large hash joins
High memory usage during joins
Significant CPU time spent on join operations
Repeated joins across the same dimensions
If performance profiling shows join overhead dominates execution time, selective denormalization may reduce latency.
Denormalization should follow evidence, not assumption.
3. Analytical or Reporting Systems
For example, data warehouses commonly apply denormalization because:
Queries aggregate across large datasets
Dimensions are frequently reused
Star schemas reduce join complexity
In these systems, storage is usually cheaper than repeated runtime computation.
Denormalization aligns with read-optimized architectures.
4. Precomputed or Cached Results
If the same aggregations or joins are executed repeatedly, creating summary tables or materialized views may improve performance.
Examples:
Monthly revenue summaries
Pre-flattened reporting tables
Cached dimension attributes
This shifts computation from query time to batch processing.
5. Latency-Sensitive Applications
When user-facing systems require consistent sub-second response times, denormalization can reduce execution path complexity.
Typical scenarios:
Real-time dashboards
Search result views
High-frequency read APIs
Reducing joins can simplify execution plans and lower response variability.
Test Real Analytical Workloads with Exasol Personal
Denormalization is not appropriate in the following situations:
High-frequency transactional updates
Strict data integrity requirements
Limited storage capacity
Systems where indexing and query tuning have not yet been optimized
If indexing, partitioning, or query optimization can solve performance issues, structural redundancy may be unnecessary.
Practical Rule of Thumb
Start with normalization.
Measure workload behavior.
Optimize queries and indexing first.
Denormalize only when joins remain the dominant performance constraint.
Denormalization is a targeted optimization technique. It should be applied incrementally and validated through benchmarking.
FAQs
A denormalized database is a relational database in which selected data is intentionally duplicated or combined across tables to reduce join operations. This design improves read performance in specific workloads, especially reporting or analytical queries, but increases storage usage and write complexity.
Normalization reduces redundancy by splitting data into related tables and enforcing relationships through keys. Denormalization introduces controlled redundancy by combining or duplicating data to reduce join cost and improve read performance. Normalization prioritizes data integrity; denormalization prioritizes query efficiency.
Normalized data is stored once in logically separated tables to eliminate redundancy and maintain consistency. Denormalized data stores selected attributes together, even if that means duplication. Normalized structures favor update simplicity, while denormalized structures favor faster read queries.
You would denormalize data when read performance becomes a bottleneck due to complex joins or repeated aggregations. Denormalization reduces runtime computation by pre-storing related attributes together. It is most effective in read-heavy workloads where write frequency is low relative to query volume.
Yes, denormalization is a good idea when performance analysis shows that join overhead significantly impacts query latency. It is appropriate in analytical systems, reporting environments, or dashboards where read speed is critical and controlled redundancy is manageable.
An example of denormalization is storing customer_name directly in an orders table instead of retrieving it through a join with the customers table. This reduces join operations during queries but requires updating multiple rows if customer information changes.
Data warehouses often use selectively denormalized schemas to optimize analytical queries. While they are built on the relational model, they frequently flatten or partially combine dimension attributes to reduce join complexity during aggregation workloads.
Denormalized data refers to data that has been intentionally duplicated or consolidated across tables to reduce relational complexity. It is a performance-driven design choice that trades strict redundancy minimization for faster read execution.
Mathias Golombek
Mathias Golombek is the Chief Technology Officer (CTO) of Exasol. He joined the company as a software developer in 2004 after studying computer science with a heavy focus on databases, distributed systems, software development processes, and genetic algorithms. By 2005, he was responsible for the Database Optimizer team and in 2007 he became Head of Research & Development. In 2014, Mathias was appointed CTO. In this role, he is responsible for product development, product management, operations, support, and technical consulting.