
Data Warehouse Models: Star, Snowflake, Data Vault & More

Data warehouse models define how information is structured inside a data warehouse. They determine which tables exist, how they connect, and how queries are executed at scale, making them a core element of any data warehouse architecture.
The choice of model influences speed, cost, governance, and how easily teams can adapt the data warehouse as business needs evolve.
This guide explains the major approaches — dimensional schemas such as star and snowflake, the galaxy constellation, Data Vault, and normalized ER/3NF structures. Each model serves a different purpose. Some simplify reporting with predictable dimensions, while others prioritize flexibility, auditability, or integration across many sources.
You will also find a comparison matrix, worked examples, and industry-specific blueprints. These are designed to help architects and decision-makers evaluate which model best fits their environment.
Data Warehouse Model Comparison
Data warehouse models differ in how they balance query speed, storage efficiency, governance, and scalability. The table below highlights the main approaches side by side.
Functional Comparison:
| Model | Best For | Pros | Cons | Complexity | Tooling Fit |
|---|---|---|---|---|---|
| Star schema | Standard BI dashboards, KPIs | Simple, fast queries, widely supported | Can oversimplify hierarchies | Low | Power BI, Tableau, Looker |
| Snowflake schema | Complex hierarchies, normalized dims | Reduces redundancy, smaller storage | Slower joins, more complex queries | Medium | BI, Exasol |
| Galaxy (Constellation) | Multi-fact schemas, cross-domain BI | Supports shared dimensions, flexible | Complexity increases sharply | High | Often custom |
| Data Vault 2.0 | Regulated industries, audit trails | Strong lineage, historization, scalable | Needs marts for BI, verbose structure | High | dbt, Exasol |
| ER/3NF | Operational warehouses, staging | Strong normalization, low redundancy | Poor for BI, many joins required | Medium | RDBMS, limited BI |
| Anchor Modeling | Extreme agility, schema volatility | Temporal modeling, flexible, evolving | Niche skills, limited adoption | High | Niche support; few mainstream tools |
| Wide Tables | ML feature stores, prototyping | Simple access, flat structure | Redundant, poor for BI | Low | ML platforms, notebooks |
Each data warehouse model comes with trade-offs. Star and snowflake schemas remain the most common choices for BI because they balance speed and usability. Data Vault is preferred in regulated industries for its strong audit trails, while Galaxy models support complex cross-domain reporting at the cost of added complexity. Emerging approaches like Anchor Modeling and Wide Tables serve niche use cases such as agile schema changes or machine learning feature stores. The right model depends on your balance of governance, performance, and business needs.
Operational Trade-offs:
| Model | Change Handling | Team Skills Needed | Typical BI Latency | Auditability and Governance |
|---|---|---|---|---|
| Star schema | Type 1–3 SCD manageable | SQL / BI analysts | Low (fast) | Limited (basic lineage) |
| Snowflake schema | Handles deep SCDs well | Strong SQL, DBAs | Medium | Better lineage |
| Galaxy (Constellation) | Complex | Advanced SQL/modeling | Medium-High | Limited out of the box |
| Data Vault 2.0 | Built for churn + CDC | Data engineers | Higher (w/PIT views) | Excellent (audit, compliance) |
| ER/3NF | Schema changes hard | DBAs / engineers | High latency | Good lineage |
| Anchor Modeling | Best for schema churn | Specialist knowledge | Variable | Decent lineage, tool gaps |
| Wide Tables | Overwrites only | Data scientists | Very low (fast) | Minimal (no lineage) |
Operational trade-offs show that not all models handle change, latency, or governance equally. Star schemas deliver fast BI but limited lineage, while Snowflake schemas provide better normalization at the cost of query speed. Data Vault offers the strongest compliance and auditability but increases latency without PIT views. Wide tables enable rapid prototyping for data science but sacrifice governance. Choosing the right model means aligning technical strengths with your organization’s priorities in agility, control, and performance.
Dimensional Modeling in Data Warehousing
Dimensional modeling organizes data into facts and dimensions to support fast, predictable queries. It is the foundation of many business intelligence and reporting systems, and one of the core data warehouse concepts that inform model selection.
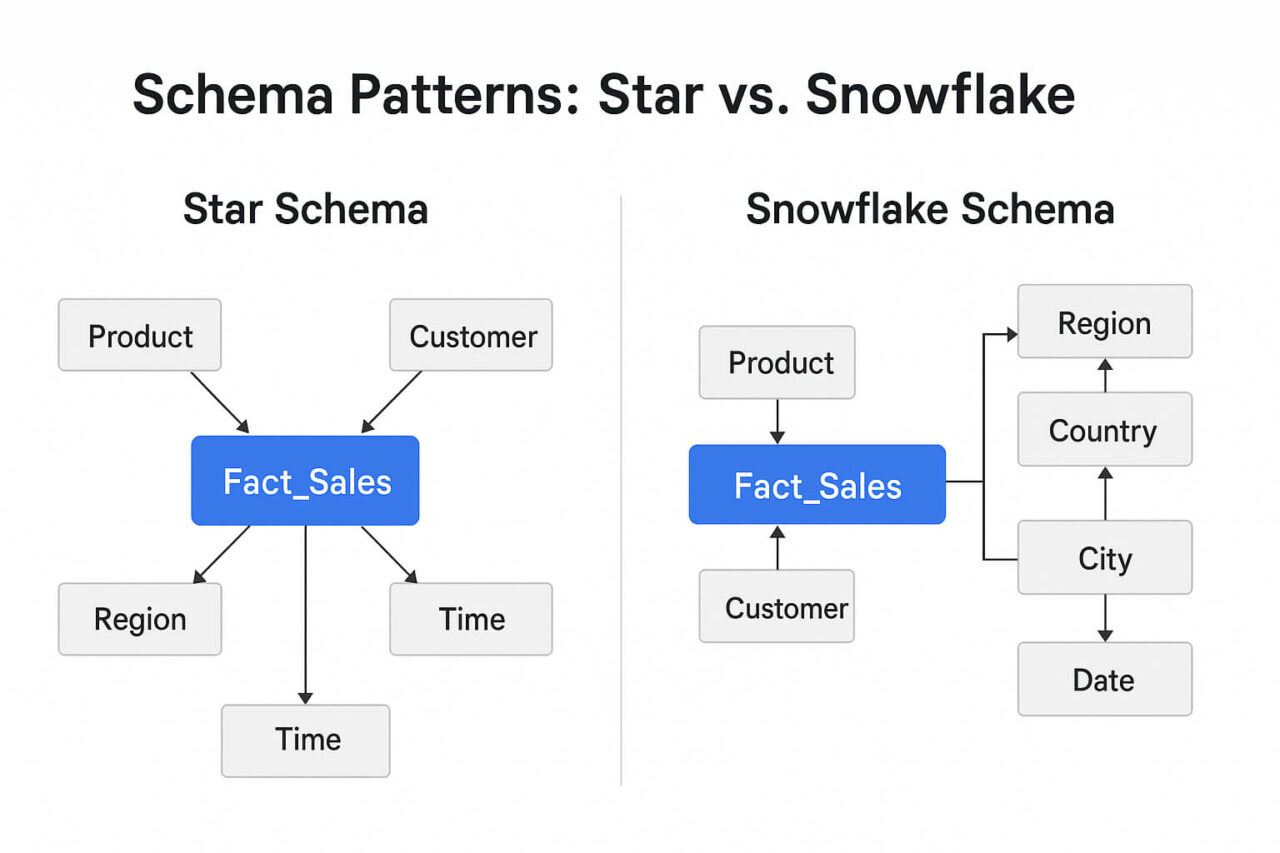
Star Schema
A star schema places a single fact table at the center, surrounded by dimension tables.
- Use case: Dashboards and BI queries with large volumes of fact data and repeatable analysis.
- Advantages: Simple to understand, fast joins, widely supported by BI tools.
- Limitations: Redundant data in dimensions, limited flexibility for complex hierarchies.
Example:
A retail data warehouse may store sales in a fact table with foreign keys to dimensions such as Date, Product, Store, and Customer.

Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Snowflake Schema
A snowflake schema normalizes dimensions into multiple related tables. The snowflake schema normalizes dimensions into multiple related tables. In a modern data warehouse, this trade-off can reduce storage but adds complexity through extra joins.
- Use case: Environments with complex hierarchies, such as geography (Country → Region → City).
- Advantages: Reduces data duplication, enforces consistency across attributes.
- Limitations: Joins become more complex; queries may run slower than in a star schema.
Example:
A Product dimension may split into Product, Category, and Supplier tables, linked by keys instead of a single flat table.
Galaxy (Constellation) Schema
A galaxy schema, also called a constellation, contains multiple fact tables that share dimension tables.
Use case: Enterprises that need reporting across business processes (e.g., sales and finance).
Advantages: Integrates multiple subject areas; allows comparisons across domains.
Limitations: Design and maintenance are more complex; requires careful governance of shared dimensions.
Example:
A Customer dimension could link to both a Sales fact table and a Support fact table, enabling analysis across revenue and service.
Slowly Changing Dimensions (SCD Types)
Dimensional models must handle how attributes change over time. SCDs define strategies for updating dimension data. Done well, they deliver clear data warehouse advantages in accuracy, compliance, and long-term usability.
| Type | Description | Use Case |
|---|---|---|
| Type 0 | Retain original value, no changes. | Static attributes (e.g., Date of Birth). |
| Type 1 | Overwrite old value with new. | Non-critical changes (e.g., correcting a spelling error). |
| Type 2 | Add a new row with start/end dates to preserve history. | Tracking history of Customer Address or Job Title. |
| Type 3 | Keep previous value in additional column(s). | Storing “current” and “previous” values for limited history. |
| Type 4 | Store history in a separate history table. | When historical data is rarely queried. |
| Type 5/6 | Hybrids combining Types 1–3. | Complex history needs in regulated industries. |
Example SQL — SCD Type 2 (simplified):
MERGE INTO dim_customer t
USING staging_customer s
ON (t.customer_id = s.customer_id AND t.current_flag = 1)
WHEN MATCHED AND t.attribute <> s.attribute THEN
UPDATE SET t.current_flag = 0, t.end_date = CURRENT_DATE
WHEN NOT MATCHED THEN
INSERT (customer_id, attribute, start_date, end_date, current_flag)
VALUES (s.customer_id, s.attribute, CURRENT_DATE, NULL, 1);Data Vault Modeling
Data Vault 2.0 is a modeling method designed for scalability, auditability, and long-term adaptability. Instead of storing all data in a single star or snowflake schema, Data Vault separates the business keys, relationships, and context into three distinct structures.
Unlike a traditional enterprise data warehouse, which often locks design choices early, Data Vault is built for incremental change and auditability.
Core Components
Hubs
Contain the unique business keys of core entities (e.g., Customer ID, Product ID).
- Attributes: surrogate key, business key, load date, record source.
- Purpose: provide a consistent anchor for all related data.
Links
Represent relationships between hubs (e.g., Customer ↔ Order).
- Attributes: surrogate key, foreign keys to hubs, load date, record source.
- Purpose: enable many-to-many relationships without redesign.
Satellites
Store descriptive attributes and changes over time (e.g., Customer Name, Address).
- Attributes: surrogate key, foreign key to hub/link, effective start/end dates, record source.
- Purpose: capture history with full lineage and auditability.
Example Hub Definition
CREATE TABLE hub_customer (
hub_customer_id BIGINT GENERATED ALWAYS AS IDENTITY,
customer_key VARCHAR(100) NOT NULL, -- business key
load_date TIMESTAMP NOT NULL,
record_source VARCHAR(50) NOT NULL,
PRIMARY KEY (hub_customer_id)
);Example Satellite with History
CREATE TABLE sat_customer (
sat_customer_id BIGINT GENERATED ALWAYS AS IDENTITY,
hub_customer_id BIGINT NOT NULL,
customer_name VARCHAR(200),
customer_address VARCHAR(200),
effective_start TIMESTAMP NOT NULL,
effective_end TIMESTAMP,
record_source VARCHAR(50) NOT NULL,
PRIMARY KEY (sat_customer_id),
FOREIGN KEY (hub_customer_id) REFERENCES hub_customer(hub_customer_id)
);This design allows multiple versions of the same customer attributes to exist, preserving a full timeline.
PIT and Bridge Views
Point-in-Time (PIT) Views
Join hubs, links, and satellites to provide a snapshot of data at a specific time. Useful for simplifying reporting queries without losing historical context.
Bridge Views
Pre-join multiple satellites or complex relationships to improve query performance. Especially helpful when BI tools need flattened structures.
Example PIT View (simplified):
CREATE VIEW pit_customer AS
SELECT
h.customer_key,
s.customer_name,
s.customer_address,
s.effective_start,
s.effective_end
FROM hub_customer h
JOIN sat_customer s
ON h.hub_customer_id = s.hub_customer_id
WHERE s.effective_end IS NULL; -- current recordWhen to Use Data Vault
Best suited for:
- Large, evolving data environments.
- Enterprises needing full audit history and regulatory compliance.
- Scenarios with frequent schema changes or multiple source systems.
Trade-offs:
- More complex to implement than star or snowflake.
- Requires downstream marts or views for BI consumption.
Entity-Relationship (3NF / Inmon)
In the Inmon approach, data warehouses are built in 3rd Normal Form (3NF). This reduces redundancy and enforces integrity, but it requires many joins and makes BI queries slower compared to dimensional models.
Anchor Modeling
Anchor modeling is designed for highly volatile schemas. It uses temporal anchors to handle change efficiently. While flexible, it requires niche skills and has limited tool adoption.
Wide Tables
Wide tables flatten many attributes into a single denormalized structure. This is common in ML feature stores and prototyping, but it increases storage costs and reduces governance.
Data Models in a Lakehouse Architecture
Many teams first encounter the data lake vs data warehouse debate when weighing storage options. The medallion approach reframes that choice by layering raw, curated, and business-ready data.
In this setup, data is organized into Bronze, Silver, and Gold layers, each with a different role. Understanding where data warehouse models fit helps align design choices with performance and governance needs.
Bronze Layer – Raw Data
- Role: Ingested data in its original format (files, streams, CDC feeds).
- Modeling: Minimal structure. Typically landing zones or staging tables.
- Best practices: Keep lineage, source metadata, and apply only essential data quality checks here.
Silver Layer – Cleansed and Integrated
- Role: Curated data with standardized keys, deduplicated records, and business context applied.
- Modeling approaches here:
- 3NF / ER models for source integration.
- Data Vault hubs, links, and satellites for flexible, auditable history.
- Value: Provides a governed foundation without constraining how marts are built.
Gold Layer – Optimized for Analytics
- Role: Business-ready datasets, tuned for dashboards and analytics.
- Modeling approaches here:
- Star and Snowflake schemas for BI tools.
- Galaxy schemas when multiple subject areas share common dimensions.
- Value: Delivers fast queries, user-friendly structures, and predictable measures.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Worked Example
- Bronze: Capture customer change data from a CRM feed.
- Silver: Store changes in Data Vault Satellites linked to a Customer Hub. Maintain full history.
- Gold: Expose a Customer Dimension (Type 2 SCD) with attributes flattened for BI queries.
This path combines auditability at Silver with usability at Gold.
When to Map Models Across Layers
- Use Data Vault or 3NF in Silver when audit trails or flexible integration are required.
- Use Star/Snowflake in Gold to simplify analytics.
- For small projects or proofs of concept, you can move from Bronze directly to Gold, but this sacrifices lineage and scalability.
Best Practices for Data Warehouse Modeling
Modeling is not only about schemas. Governance, transformation patterns, and change handling all influence whether a data warehouse remains reliable and scalable over time.
ETL vs. ELT
In short, ETL runs transformations before loading; ELT pushes them into the data warehouse.
- ETL (Extract–Transform–Load):
Data is transformed before loading into the data warehouse. Suitable for traditional on-premises systems with limited compute inside the data warehouse. - ELT (Extract–Load–Transform):
Data is loaded first, then transformed using data warehouse compute. This is the standard for modern cloud warehouses.
Best practice:
- Use ELT where compute elasticity allows pushing heavy transformations inside the data warehouse.
- Retain ETL for cases requiring sensitive pre-processing or when source systems demand it.
Change Data Capture (CDC)
CDC captures and applies only changed records rather than reloading entire tables.
Methods:
- Log-based CDC (reads database logs).
- Timestamp or version-based CDC.
- Trigger-based CDC (less common).
Integration with models:
- Dimensional models: drive SCD Type 2 updates for dimension history.
- Data Vault: populate satellites with every change, preserving lineage.
Best practice:
- Prefer log-based CDC where available for efficiency and accuracy.
- Apply CDC patterns consistently across Bronze/Silver layers to ensure integrity.
Governance and Access Control
- Environment separation: keep development, staging, and production isolated.
- Role-based access control (RBAC): restrict access to raw vs. curated vs. business-ready layers, following the NIST RBAC standard.
- Data lineage and cataloging: document models and transformations for transparency.
- Testing: enforce schema checks, null constraints, and referential integrity at load time.
Best practice:
Align governance to model choice:
- Data Vault/3NF in Silver → strong audit, lineage, and compliance.
- Dimensional schemas in Gold → access tuned for analysts and BI tools.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Performance and Cost Management
- Partitioning and clustering: improve query speed on large fact tables.
- Materialized views: speed up heavy joins (e.g., snowflake or constellation queries).
- Storage considerations: Snowflake schemas and Data Vaults reduce duplication but increase joins. Wide tables increase storage but reduce query time for simple ML workloads.
Industry-Specific Data Warehouse Models
Different industries face unique requirements. While the modeling principles remain the same, domain-specific facts and dimensions change. Below are simplified blueprints that highlight how core models adapt in healthcare, banking, and retail.
Healthcare Data Warehouse Model
- Fact tables: Patient Encounters, Procedures, Billing Claims.
- Dimensions: Patient, Provider, Diagnosis, Facility, Date.
- Modeling considerations:
- Track patient history with SCD Type 2 to preserve address, insurance, or physician changes.
- Regulatory compliance (HIPAA, GDPR) requires auditability → Data Vault satellites fit well in Silver layer.
Case Example – Piedmont Healthcare
Piedmont Healthcare manages data from 16 hospitals, 1,400 physician practices, and over 2 million patient visits annually. Their environment includes electronic health records (EHR), claims, ERP, CRM, and survey systems, generating more than 15 TB of data.
By migrating from SQL Server to Exasol, Piedmont Healthcare reduced dashboard refresh times from 10 minutes to seconds and scaled to deliver around 20 new metrics per month.
This illustrates the reality that data warehouses in healthcare must integrate and query vast, heterogeneous healthcare data sources — EHRs, claims, and operational systems — which poses significant modeling challenges. Choosing a model that balances history tracking, auditability, and query speed is critical in healthcare contexts.
Banking Data Warehouse Model
- Fact tables: Account Transactions, Loan Applications, Payments.
- Dimensions: Customer, Account, Product, Branch, Time.
- Modeling considerations:
- Strong lineage for compliance with Basel/DORA → Data Vault recommended for full history.
- Reporting marts in Gold can use star schema for KPIs such as loan approval rates or NPL ratios.
Retail Data Warehouse Model
- Fact tables: Sales, Inventory Movements, Returns.
- Dimensions: Product, Store, Promotion, Supplier, Date.
- Modeling considerations:
- High-volume sales facts → partition fact tables by Date/Store.
- Promotions and price changes fit SCD handling for Product Dimension.
Case Example – Flaconi
Flaconi, a leading European online beauty retailer, migrated from a legacy analytics system to a cloud-based Exasol deployment. Their environment integrates Python and Pentaho ETL pipelines with AWS services, processing around 3 TB of sales, product, and customer data.
With Exasol, Flaconi accelerated ETL and reporting, enabling ~120 self-service BI users to access real-time dashboards. They also improved forecasting models for stock levels and campaign performance. This demonstrates a common retail challenge: data warehouses must handle large data volumes and diverse sources while still delivering fast, user-ready insights for marketing, inventory, and operations.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
How to Choose the Right Model
Different models solve different problems. The choice depends on data volume, complexity, governance requirements, and the skills of the team building and maintaining the data warehouse. Established research on data modeling shows how different approaches trade off flexibility and complexity.
Decision Factors
Data Volume and Complexity
- Small to medium volumes with straightforward reporting → Star schema.
- High complexity or multiple subject areas → Snowflake or Galaxy.
- Petabyte scale, multi-source integration, and frequent schema changes → Data Vault.
Governance and Compliance
- Strong auditability or regulatory reporting (e.g., banking, healthcare) → Data Vault or 3NF/ER in Silver layer.
- Business intelligence with less regulatory overhead → Star/Snowflake in Gold layer.
Team Skills and Tooling
- BI analysts and SQL developers → Dimensional models.
- Advanced data engineering teams comfortable with automation → Data Vault or Anchor Modeling.
- Data science and ML teams → Wide Tables or curated Gold layer extracts.
Performance and Cost Priorities
- Fast query response for dashboards → Star schema.
- Storage efficiency and reduced duplication → Snowflake schema.
- Balanced performance and auditability → Hybrid (Data Vault in Silver + Dimensional marts in Gold).
Recommended Hybrid
Most modern data warehouses blend approaches:
- Silver layer: Data Vault or 3NF for history, auditability, and integration.
- Gold layer: Star or Snowflake marts for BI usability.
- Optional: Wide Tables for ML feature stores.
This hybrid addresses both compliance requirements and business agility.
FAQs about Data Warehouse Models
A model in a data warehouse defines how information is structured for storage and querying. It specifies fact tables, dimension tables, and relationships, so that data can be integrated from multiple sources and queried efficiently.
In data management, the four standard types of data models are Conceptual, Logical, Physical, and Dimensional. Conceptual shows high-level entities, logical defines relationships and keys, physical specifies implementation in a database, and dimensional structures data for analytics. These explain how data is represented at different levels. In the context of data warehouses, “modeling” usually refers to schema patterns such as star, snowflake, or Data Vault.
The data model of a data warehouse is its schema design — how fact tables and dimension tables are defined and linked. It governs how raw data becomes structured for reporting, and can be dimensional (star, snowflake) or historical (Data Vault, 3NF).
The three commonly referenced data warehouse models are the Enterprise Data Warehouse, Data Mart, and Operational Data Store (ODS). Each serves a different purpose: enterprise data warehouses cover the whole organization, data marts focus on a single department, and ODS supports short-term operational reporting.
The four core components are:
Data sources (operational systems, external feeds),
ETL/ELT processes (extraction and transformation),
Storage (centralized data warehouse schema), and
Presentation layer (dashboards, BI, analytics tools).
Data warehousing modeling is the process of designing fact and dimension tables in a structure that supports analytics. It includes approaches like star schema, snowflake schema, galaxy schema, and Data Vault, depending on governance and performance needs.
The four stages are Data Extraction, Data Staging, Data Storage, and Data Presentation. Data is pulled from sources, cleansed and transformed, stored in the data warehouse schema, and then exposed for analytics and BI.
A data warehouse is the system where integrated, historical data is stored for analysis. A data model is the blueprint of how that data is organized, defining tables, keys, and relationships. The model is the design; the data warehouse is the implementation.
No. Data modeling defines how data is structured in the data warehouse, while ETL/ELT are the processes that move and transform the data before it lands in that structure. Modeling comes first; ETL/ELT implements the pipeline.