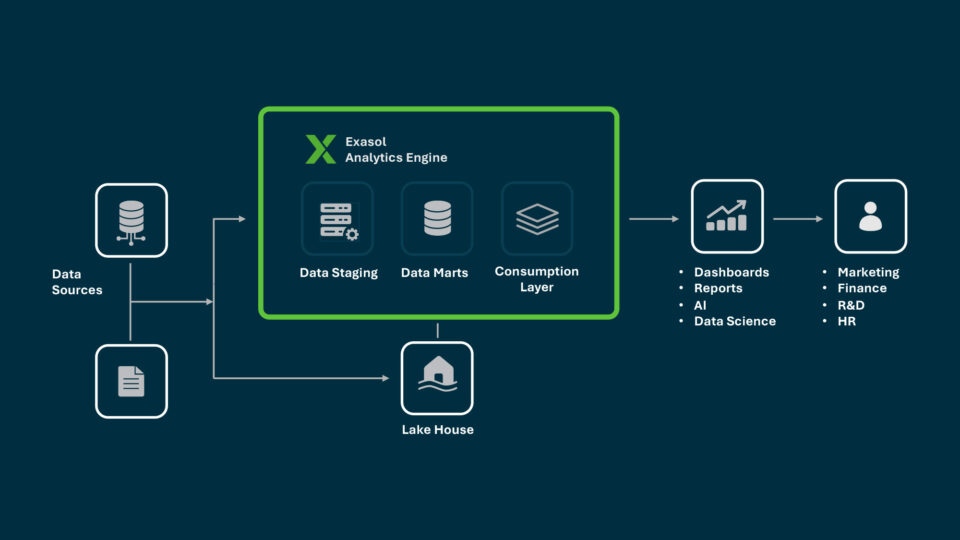
Data Warehouse Integration: Complete Guide

Data warehouse integration combines data from multiple operational and external sources into a unified repository built for analytics. The process removes silos, standardizes structures, and ensures that decision-makers and systems work from consistent information.
Integration extends beyond extract, transform, load (ETL). It covers real-time pipelines, streaming, and integration layers that enforce data quality, security, and governance. When designed correctly, integration enables faster reporting, supports advanced analytics, and creates a foundation for machine learning.
For readers who want to understand how these elements fit into the overall system design, the data warehouse architecture guide explains the structural components in more detail.
What Is Data Warehouse Integration?
Data warehouse integration is the process of consolidating structured and unstructured data from heterogeneous systems into a centralized data warehouse for analysis. It involves extracting records from transactional databases, APIs, and external feeds, transforming them into a consistent schema, and loading them into a storage layer optimized for queries.
Unlike basic data migration, integration requires maintaining referential integrity, resolving duplicates, and aligning time formats and identifiers. A well-designed integration layer enables analysts and applications to access reliable data without repeatedly reconciling source differences.
Why Integration Matters for Modern Data Warehouses
Integration creates a single source of truth, which accelerates reporting and removes delays caused by reconciling conflicting data sets. Consolidated pipelines also improve agility: new sources can be added without redesigning the entire data warehouse. These are the data warehouse benefits that drive return of investment. Compliance benefits follow from integration as well, since consistent identifiers and time formats make audits repeatable.
Exasol adds value at this stage through performance and analytics acceleration. Integrated datasets can be processed at high concurrency with predictable response times, which is critical when queries span billions of rows.
Governance sits at the core of integration. Controls for lineage, metadata, and access rights must be embedded early to enforce quality. Data integrity in a data warehouse means ensuring accuracy at the record level, while referential integrity in a data warehouse guarantees relationships between tables remain valid as sources evolve.

Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Core Integration Patterns
Data warehouse integration follows recurring patterns. Choosing the right one depends on latency requirements, source system capabilities, and governance needs.
Batch vs. Real-Time Integration
- Batch integration groups data into scheduled loads, often daily or hourly. It works well for finance, compliance, and domains where timing tolerance is measured in hours.
- Real-time integration ingests events continuously through streaming platforms or change data capture. It supports operational dashboards, fraud detection, and use cases where delays in seconds or minutes impact decisions.
| Pattern | How It Works | Typical Use Cases | Limitations |
|---|---|---|---|
| Batch | Data collected and loaded on a schedule (daily, hourly). | Financial reporting, compliance archives, historical analysis. | Latency; no immediate insight. |
| Real-Time | Continuous ingestion via streaming or change data capture. | Fraud detection, operational dashboards, IoT monitoring. | Higher infrastructure complexity, governance overhead. |
ETL vs. ELT vs. Streaming Pipelines
- ETL (Extract, Transform, Load): Transformations occur before the data reaches the data warehouse. This reduces load size but requires dedicated processing infrastructure.
- ELT (Extract, Load, Transform): Data lands in the data warehouse first, then transformations run inside the database. This leverages data warehouse performance and scales better for large, diverse inputs.
- Streaming pipelines: Events are processed on arrival with minimal staging. They handle continuous feeds but require careful governance to maintain consistency and replay capability.
| Approach | Process | Strenghts | Trade-offs |
|---|---|---|---|
| ETL (Extract → Transform → Load) | Data transformed before entering the data warehouse. | Reduces load size; suitable for legacy systems. | Extra infrastructure; less flexible when sources change. |
| ELT (Extract → Load → Transform) | Raw data loaded first, transformed in-database. | Leverages data warehouse performance; scalable with modern engines. | Larger initial storage footprint; governance relies on data warehouse features. |
| Streaming | Events processed as they arrive. | Supports continuous feeds; enables low-latency analytics. | Requires replay/recovery design; higher operational complexity. |
Integration patterns evolve as business requirements change. A data warehouse may combine batch ETL for legacy systems with ELT for modern APIs and streaming for IoT or web event data.
Most data warehouses adopt hybrids: batch ETL for legacy ERP, ELT for APIs, and streaming for web or IoT data.
The Integration Layer Explained
The integration layer is the point where raw inputs become consistent, governed data. It sits between source ingestion and the core data warehouse storage.
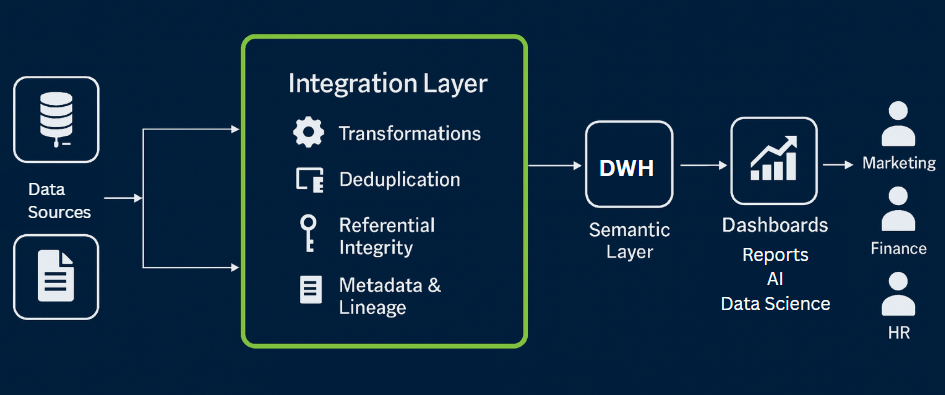
This layer aligns formats, enforces validation, and applies business rules so that downstream users and systems can work with uniform records. Without it, every new source introduces reconciliation work and increases the risk of inconsistent results.
A typical flow includes:
- Source systems – transactional databases, APIs, files, or event streams.
- Staging area – temporary storage for raw data before processing.
- Integration layer – transformations, integrity checks, deduplication, and reference data mapping.
- Core data warehouse – optimized tables for analytics and reporting.
- Semantic or access layer – business-facing views and BI tools.
In practice, the integration layer ensures that joins across systems remain valid and that referential integrity holds even when sources evolve. It also provides hooks for monitoring, lineage tracking, and auditability.
Organizations that operate an enterprise data warehouse or are building a data warehouse from the ground up depend on this layer to scale integration without sacrificing governance.
Integrating ML and Analytics Platforms
Machine learning platforms require structured, high-quality inputs. Without integration, feature engineering pipelines repeatedly solve the same problems of deduplication, timestamp alignment, and schema mapping. A data warehouse that consolidates and validates data before it reaches the ML environment reduces this overhead and improves reproducibility.
Assessment criteria include:
- Latency tolerance – whether the model needs streaming updates or can operate on daily refreshes.
- Data integrity – consistency of identifiers and referential links across training and production data.
- Governance – lineage, auditability, and security controls to protect sensitive attributes.
- Performance – ability of the data warehouse to process large volumes at concurrency without slowing model iteration.
For teams evaluating how to connect existing sources with ML services, the integration layer provides the bridge between operational feeds and analytical models. Organizations working with a modern data warehouse gain the flexibility to switch between batch training pipelines and low-latency feature stores.
Deploying Exasol’s integration solutions, such as Exasol MCP, reduces the gap between source systems and feature stores, improving both reproducibility and throughput.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Industry Examples of Integration
The term “warehouse integration” can describe either operational data warehouses or data warehouse concepts.
Clear distinction is necessary: in this context, integration refers to unifying digital data sources for analytics, not the coordination of physical logistics systems.
Examples of data integration in practice:
Healthcare: Piedmont Healthcare integrated clinical, financial, and operational data into a single data warehouse. The result was consistent reporting across 16 hospitals and thousands of staff, with query performance scaled to trillions of records.
Retail / Wholesale: Gintarinė Vaistinė unified sales and inventory data from more than 240 pharmacies. Query times dropped from about 30 seconds to under 2 seconds, with near real-time refresh cycles every 15 minutes.
Industrial / Predictive Maintenance: WashTec aggregated sensor, machine operation, and error-log data from diverse source formats (SQL, NoSQL, JSON) into Exasol. Integrated ML pipelines now drive maintenance predictions and and improve equipment uptime.

These examples show how integration enforces data integrity, preserves referential links across systems, and enables analytics that scale with business needs.
Governance and Integrity in Data Warehouse Integration
Integration does not stop with data movement. Governance defines how information is validated, documented, and secured as it enters the data warehouse. Without governance, pipelines may deliver fast but unreliable results.
Data integrity in a data warehouse requires that individual records remain accurate and consistent throughout their lifecycle. Checks for duplicates, null values, and type mismatches must occur during ingestion, not after the data is already in use.
Referential integrity in a data warehouse ensures that relationships between tables hold as sources evolve. Keys linking customers to transactions or patients to visits must remain valid even when systems are upgraded or new feeds are introduced. Violations at this level break reports and can lead to compliance failures.
Effective governance embeds controls into the integration layer:
- Metadata and lineage tracking to document how each field was transformed.
- Access rights that restrict sensitive data to authorized users.
- Auditability for internal and external reviews.
The data sovereignty revolution underscores how geographic, legal, and privacy constraints require integration architectures to account for where data is stored and who controls it.
Large-scale deployments rely on these controls to keep analytics consistent across business units. Even specialized platforms like a SQL Server data warehouse need referential checks and lineage records to maintain trust in outputs.
When governance and integrity checks are part of integration, data warehouses scale without sacrificing trust in their outputs.
8 Steps for a Successful Integration
A structured process prevents integration projects from drifting into ad hoc fixes. Each step builds the foundation for reliable, scalable pipelines.
- Identify sources
Catalog every system that produces or stores relevant data: transactional databases, ERP, CRM, sensor feeds, log files, or third-party APIs. Include metadata such as refresh frequency, ownership, and data volume to understand dependencies before design begins. - Define objectives
Translate business questions into technical requirements. If finance requires consolidated cash flow, or operations needs real-time monitoring, specify latency, granularity, and retention targets up front. Objectives prevent scope creep and guide method selection. - Map schemas
Create a blueprint that shows how fields align across sources. Resolve conflicts in naming conventions, data types, and units of measure. Decide whether to preserve source identifiers or standardize them into global keys. Schema mapping is closely tied to the choice of data warehouse models, which define how structures such as dimensions and facts are represented for analysis. - Select integration method
Match requirements to architecture: batch ETL for nightly reconciliations, ELT for high-volume APIs, or streaming for event-driven use cases. Hybrid models are common, but each method must be justified against latency, cost, and operational complexity. - Set governance controls
Define validation rules, metadata capture, and access rights before production loads. Establish who can change transformation logic, how lineage is recorded, and which datasets require masking. Governance prevents silent corruption and ensures compliance audits can be repeated. - Build the integration layer
The integration layer applies transformations and integrity checks that align raw inputs into consistent, governed tables. Deduplication, referential integrity enforcement, and handling slowly changing dimensions ensure that records remain both accurate and historically traceable.
Change Data Capture (CDC) techniques are often applied at this stage to capture inserts, updates, and deletes from source systems in real time. CDC reduces load volumes and keeps the data warehouse synchronized with operational databases.
Slowly Changing Dimensions (SCD) strategies manage attributes that evolve over time, such as customer addresses or product categories. By tracking changes systematically, the data warehouse preserves both current and historical context, supporting accurate trend analysis.
The integration layer becomes the foundation for trust in analytics, allowing downstream models and reports to operate on reliable, versioned data. - Test pipelines
Validate both performance and accuracy. Compare row counts against source systems, confirm that key relationships hold, and measure query response times under load. Testing should include failure scenarios such as late-arriving files, schema drift, and incomplete batches. - Monitor and optimize
Deploy monitoring for latency, error rates, and data quality metrics. Alerts should trigger when referential integrity breaks or when loads exceed defined thresholds. Continuous optimization adapts schedules, improves transformation efficiency, and incorporates new sources without disrupting existing analytics.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Frequently Asked Questions
Integrated data in a data warehouse is information combined from multiple operational and external systems into a uniform schema. It eliminates duplication, aligns identifiers, and allows queries to return consistent results across business functions.
The three common types are:
Enterprise Data Warehouse (EDW): a central repository for all organizational data.
Operational Data Store (ODS): focuses on current, operational reporting with frequent updates.
Data Mart: a subject-specific data warehouse optimized for a department such as sales or finance.
An example is combining customer records from CRM, e-commerce, and support systems. Once integrated, analysts can view a single customer profile that includes purchases, service interactions, and billing data.
Yes. A core characteristic of a data warehouse is integration—data from diverse sources is standardized and stored in a central structure for analytics.
Data warehousing integration is the process of extracting, transforming, and loading information from multiple systems into a centralized data warehouse. It ensures consistency, accuracy, and accessibility for analysis.
A data warehouse is the platform where information is stored and analyzed. Data integration is the process of combining and preparing information from heterogeneous sources before or as it enters the data warehouse.
“Integrated” means data from different systems is standardized in terms of keys, formats, and definitions, so users can query it without resolving discrepancies manually.
The main goal is to provide a single, reliable source of truth for analytics by ensuring that data from various systems is accurate, complete, and consistent.