Data Warehouse Design: Complete Guide for 2026

Designing a data warehouse means translating business requirements into a reliable data architecture that enables consistent, fast, and governed analytics. The design phase defines how data is modeled, stored, and accessed, before any code or infrastructure is built.
A well-planned design matters because it directly impacts speed, scalability, and data sovereignty. Poor design slows queries, complicates maintenance, and increases compliance risks. Good design enables fast decision-making and long-term flexibility across cloud, on-prem, or hybrid environments.
This guide walks through every step of the design process: from modeling principles and data warehouse architecture choices to modern and agile methodologies.
What Is Data Warehouse Design?
Data warehouse design is the structured process of translating analytical requirements into a technical framework for data storage and retrieval. It defines how data is collected, modeled, organized, and served so that business users can query it efficiently and accurately.
Design sits between strategy and implementation. Before engineers build pipelines or load tables, architects decide how information will move through staging, integration, and presentation layers. Each design choice (schema type, storage model, or indexing strategy) affects cost, performance, and maintainability.
Unlike data warehouse architecture, which focuses on system components, design specifies how those components interact to achieve business outcomes. It is where data warehouse modeling, governance, and performance planning converge.
Quick overview and summary:
| Stage | Focus | Output |
|---|---|---|
| 1. Requirements | Identify data sources and business needs | Design scope defined |
| 2. Modeling | Choose schema (star, snowflake, vault) | Logical data model |
| 3. Architecture | Decide on cloud, on-prem, or hybrid | Architecture blueprint |
| 4. Integration | Plan ETL/ELT and data quality | Pipeline design |
| 5. Testing | Validate accuracy and performance | Benchmarked warehouse |
| 6. Governance | Define ownership and lineage | Audit-ready environment |
Design Principles and Objectives
Effective data warehouse design starts with clear objectives that guide every architectural and modeling decision. The goal is not just to store data, but to make it accessible, performant, and compliant throughout its lifecycle.
Every data warehouse runs fast on day one. The mark of good design is that it still runs predictably after a hundred more data sources and ten times the users.
Dirk Beerbohm, Global Partner Solution Architect, Exasol
Key principles include:
- Scalability: Plan for data growth and user concurrency from the start. A design that scales horizontally avoids costly rework later.
- Performance: Optimize for predictable query times through proper indexing, partitioning, and caching.
- Data Integrity: Maintain consistency between source systems and analytical models using controlled ETL or ELT processes.
- Security and Governance: Implement access control, auditing, and lineage tracking early in the design, not as add-ons.
- Cost Efficiency: Separate compute from storage and monitor query workloads to prevent budget overruns.
- Data Sovereignty: Keep sensitive data in compliant regions and align design choices with evolving data sovereignty trends, ensuring regional and industry-specific regulations are met.
Strong data warehouse design principles ensure that future migrations, integrations, and analytics layers can evolve without redesigning the entire system. They form the foundation for reliable architecture and should precede any tool or platform choice.
Data Warehouse Design Process
Designing a data warehouse follows a structured sequence that moves from understanding business needs to validating performance under production conditions. Each phase builds on the previous one to ensure the data warehouse supports accurate, timely, and governed analytics. Here is how to design a data warehouse in practice, moving from business needs to validated, production-grade performance.
- Requirement Gathering
Identify business questions, data domains, and analytical workloads. Engage stakeholders early to capture both functional and compliance requirements. - Conceptual Modeling
Outline entities, relationships, and high-level data flows. Focus on what needs to be represented, not yet on how it will be stored. - Logical Design
Translate the conceptual model into detailed schemas—defining tables, keys, and relationships. This is where dimensional, normalized, or hybrid approaches are chosen. - Physical Design
Map the logical structure to the actual platform. Specify partitioning, indexing, compression, and clustering. Optimize for query performance and load efficiency. - ETL or ELT Planning
Design data integration pipelines, transformation logic, and quality checks. The choice between ETL and ELT depends on platform capability and governance needs. - Testing and Optimization
Validate data accuracy, compare query times, and benchmark concurrency. Include end-to-end lineage verification and performance tuning before go-live. - Deployment and Governance
Move designs into production with version control, monitoring, and access policies. Governance at this stage prevents drift from original design standards.
A well-executed design process minimizes rework and ensures that later architectural changes (scaling, cloud migration, or model updates) happen within controlled boundaries rather than from scratch.

Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
Design Methodologies (Kimball, Inmon, Agile, Hybrid)
Choosing the right data warehouse design approaches shapes how data is modeled, integrated, and scaled over time. Each approach balances delivery speed, governance, and flexibility differently. Understanding their trade-offs helps teams match design logic to business priorities.
Kimball (Bottom-Up)
Focuses on quick delivery through dimensional modeling. Data marts are designed around specific business processes and later integrated into a larger data warehouse. This method prioritizes usability and rapid iteration but can introduce integration overhead as systems expand.
Inmon (Top-Down)
Begins with a unified enterprise data model, then builds data marts from that foundation. It enforces consistency and governance at scale but requires longer initial design cycles. Best suited for regulated or data-intensive environments where control outweighs speed.
Data Vault / Hybrid Approaches
Combine the agility of Kimball with Inmon’s structure. Data Vault modeling separates raw, business, and presentation layers to preserve auditability and support frequent schema changes without major redesign.
Agile and BEAM✲
Adapt traditional design to iterative delivery. Agile emphasizes stakeholder feedback and incremental modeling; BEAM✲ (Business Event Analysis & Modeling) captures requirements as user stories, reducing misalignment between analysts and engineers.
Selecting a methodology depends on organizational maturity, regulatory needs, and data volatility. Many enterprises use hybrid patterns (Inmon for governance, Kimball or Data Vault for analytics agility) to balance control and delivery speed.
Data Modeling Patterns
A strong data warehouse design relies on clear modeling patterns that balance usability, maintainability, and query performance. The three dominant data warehouse design patterns (Star, Snowflake, and Data Vault) address different business and technical priorities.
Star Schema
The simplest and most widely used model. Central fact tables store measurable business events, while surrounding dimension tables describe context such as time, product, or region. Star schemas deliver fast joins and are easy for analysts to query, making them ideal for BI and dashboard workloads.
Snowflake Schema
An extension of the star model that further normalizes dimensions into sub-tables. This reduces data redundancy but adds join complexity. Snowflake design suits environments with strict data-quality requirements or shared dimensions across departments.
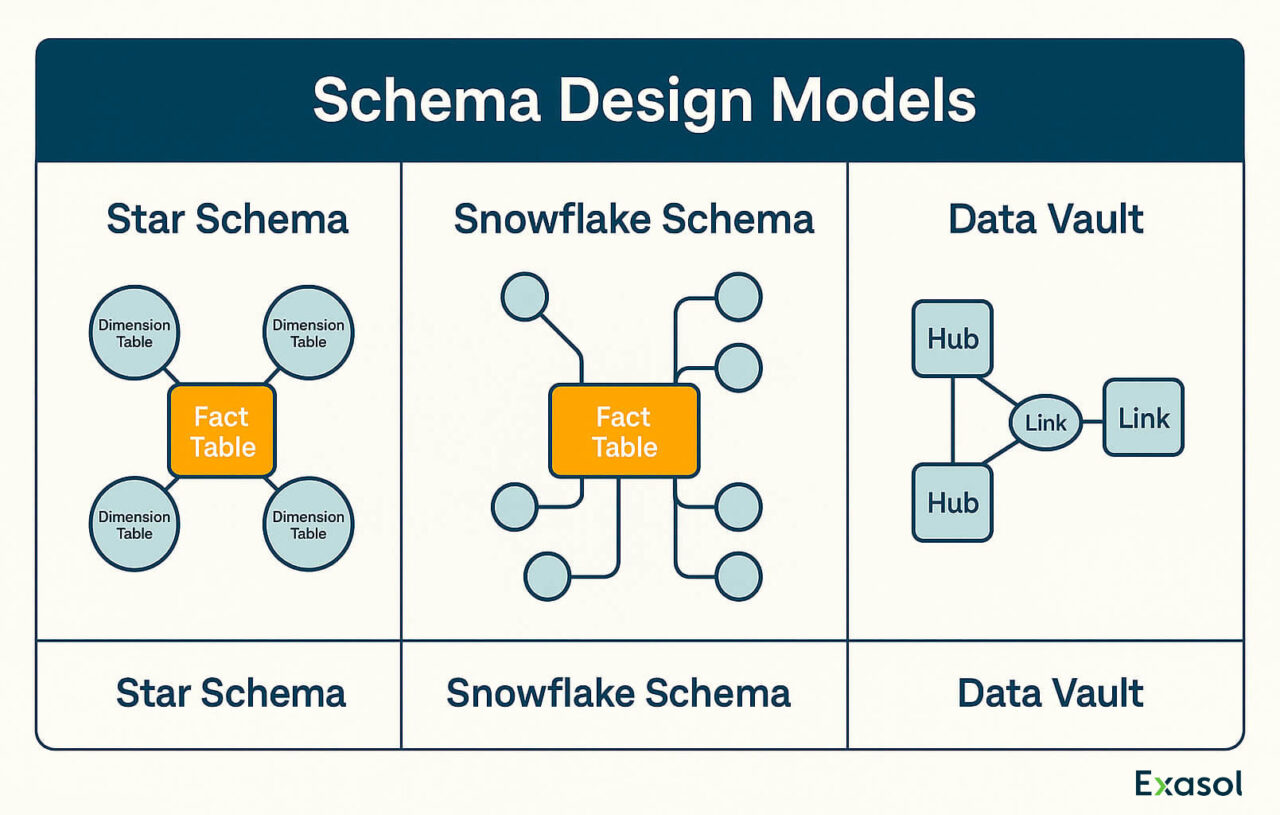
Data Vault
Separates data into hubs, links, and satellites to track both raw and business-processed states. The pattern supports large-scale integration, change tracking, and full auditability; important for regulated industries or frequently changing source systems.
The best model often combines these structures: a Data Vault as the raw data layer, star schemas for analytics, and occasional snowflake normalization where data reuse is high. The decision depends on data volatility, governance standards, and expected query patterns.
Architecture Decisions in Design
Every data warehouse architecture design must translate its logical model into a physical architecture that supports scale, latency, and governance goals. These decisions define how data moves, where it’s stored, and how queries are processed under real workloads.
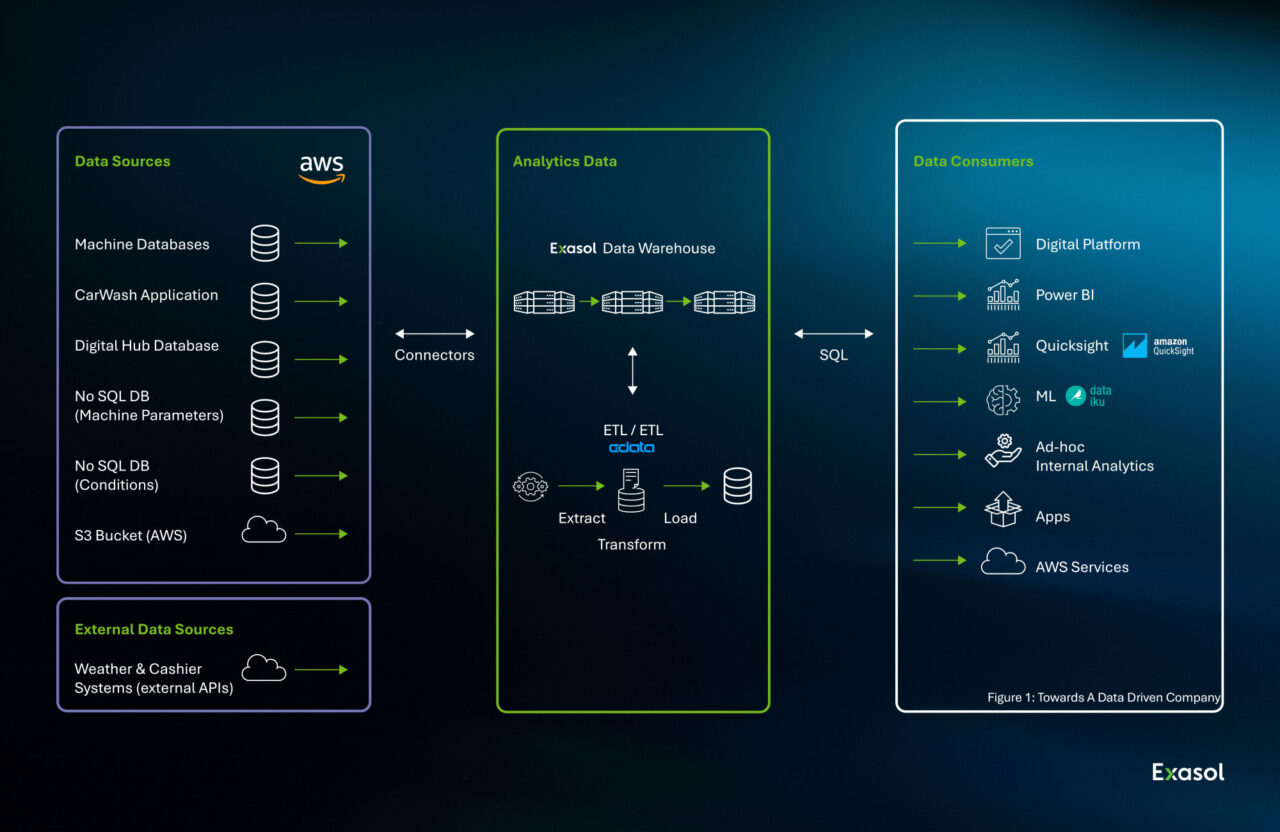
Centralized vs. Federated Architectures
A centralized design consolidates all data into a single repository, simplifying governance but increasing data movement. A federated or distributed approach leaves some data in domain systems and queries it virtually (useful for complex enterprises or multi-region compliance needs).
On-Premises, Cloud, or Hybrid Deployment
Choice of infrastructure shapes performance, cost, and sovereignty. Many organizations still evaluate the trade-offs between cloud vs on premise setups, weighing control and data locality against elasticity and operational simplicity.
- On-premises: maximum control and data locality, higher maintenance overhead.
- Cloud: elasticity and managed operations, but limited control over residency.
- Hybrid: keeps critical or regulated data local while using the cloud for scale-out analytics.
ETL vs. ELT Data Processing
In ETL, transformations happen before loading; in ELT, they occur inside the data warehouse engine. ELT suits modern, compute-rich architectures; ETL remains practical for strict quality control and legacy integration.
Security, Governance, and Observability
Embed security policies, lineage tracking, and workload monitoring directly into the design. Modern architectures increasingly rely on metadata catalogs and automated lineage to maintain trust across layers.
Architects who design data warehouse environments should serve design principles, not dictate them. A good design stays platform-agnostic; portable across new technologies and governance frameworks.
Modern and Automated Design Considerations
Modern data warehouse design extends beyond schema and storage decisions. It accounts for automation, elasticity, and metadata-driven processes that keep data platforms adaptable under continuous change.
Metadata and Automation
Automated modeling, lineage extraction, and performance tuning reduce manual work and human error. Tools for data warehouse automation (DWA) generate schemas and pipelines from metadata definitions, accelerating deployment while maintaining governance standards.
Elasticity and Resource Management
Cloud-native engines scale compute and storage independently, aligning capacity with workload peaks. Well-designed architectures include workload isolation (dedicated compute clusters for development, testing, and production) to ensure predictable performance.
DataOps and Continuous Improvement
Modern design integrates DataOps practices such as version control, CI/CD for data pipelines, and automated testing. This approach shortens release cycles and maintains stability across schema updates.
Hybrid and Sovereign Models
Organizations balancing performance with compliance increasingly adopt hybrid or sovereign architectures. These designs localize sensitive datasets while using cloud elasticity for transient workloads. Sovereignty-aware design frameworks combine regulatory control with operational agility.
Automation and modern design principles transform data warehouses from static systems into continuously optimized data services; faster to adapt, easier to audit, and more cost-efficient to scale.
Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
Best Practices and Common Pitfalls
Even the most advanced data warehouse design can fail if its foundations (validation, documentation, and governance) are neglected. Design quality determines long-term performance more than any specific tool or hardware choice.
Data Warehouse Design Best Practices
- Design for evolution: Anticipate schema expansion, new sources, and changing data domains. Modular design prevents costly rebuilds.
- Document early: Record data lineage, transformations, and business rules during design. Good documentation enables traceability and smoother audits.
- Validate with production-scale workloads: Use realistic data volumes and representative queries to expose performance bottlenecks before deployment.
- Integrate performance testing into CI/CD: Treat query speed and load time as measurable KPIs. Automated testing during design highlights regressions before they reach production.
- Bake in data quality rules: Define thresholds for completeness, duplication, and referential integrity. Designing controls upfront prevents pipeline failures later.
- Security by design: Embed access policies, encryption, and retention logic in schema definitions, not as operational add-ons.
- Measure efficiency, not just speed: Track concurrency, cost per query, and idle resource utilization.
Common Pitfalls
- Over-normalization: Adds unnecessary joins and slows queries without tangible governance benefits.
- Ignoring metadata: Leads to orphaned datasets, unclear ownership, and weak governance.
- Tool-driven design: Copying vendor defaults instead of aligning structure with business logic.
- No version control: Schema drift causes data mismatches and undermines reproducibility.
- Reactive optimization: Attempting to fix structural inefficiencies after deployment rather than validating them through proper data warehouse testing during design.
Testing should be a design discipline, not a final checkpoint. Comparing row counts, query times, and concurrency during the modeling phase prevents expensive retrofits once systems go live. Incorporating structured data warehouse testing ensures that scalability, integrity, and performance remain consistent as workloads evolve.
Example Framework
A complete data warehouse design integrates methodology, modeling, and governance into one repeatable framework. Strong design accelerates smooth data warehouse implementation and reduces post-launch tuning.
The structure below illustrates how most enterprise teams organize the process, balancing speed of delivery with long-term maintainability.
- Business Understanding
Define measurable outcomes: reporting latency, concurrency targets, or compliance SLAs. These metrics turn vague “faster analytics” goals into design requirements. - Conceptual and Logical Modeling
Translate business events into data entities and relationships. Choose between dimensional or normalized models based on query patterns and update frequency. - Architecture Definition
Select the deployment strategy (on-prem, cloud, or hybrid) and define data movement between staging, integration, and presentation layers. Align choices with sovereignty and governance policies. - Implementation Blueprint
Specify schema templates, data ingestion logic, and naming conventions. Include automation scripts or metadata generators if available. - Testing and Optimization
Validate accuracy, load time, and concurrency. Use systematic data warehouse testing to benchmark transformations, query plans, and schema evolution before production. - Governance and Change Management
Document lineage, assign ownership, and enforce version control. Governance at design level prevents inconsistency as new data sources join the system.
This framework converts design into an operational discipline: repeatable, measurable, and auditable across technologies. It ensures the data warehouse evolves predictably instead of reacting to every new data source or tool.
Case Study: From Legacy Systems to Modern Data Warehouse Design
Austrian bank bank99 redesigned its data warehouse architecture to consolidate multiple legacy systems into a unified analytics platform.
The project focused on scalability, performance, and data governance (core objectives of effective data warehouse design).
By aligning business modeling with regulatory requirements and modern ETL automation, bank99 achieved faster data delivery and simplified compliance reporting.
The implementation demonstrates how sound design principles reduce maintenance complexity while supporting future expansion.
Try the Community Edition for Free
Run Exasol locally and test real workloads at full speed.
Final Thoughts
Sound data warehouse design is not a one-time technical exercise; it’s an architectural discipline that determines how well an organization can adapt to change. Every decision made at the design stage influences performance, governance, and scalability years later.
The strongest designs follow a consistent logic: capture business intent early, model data transparently, enforce quality through testing, and maintain flexibility for future integration. Whether the data warehouse runs on-prem, in the cloud, or across hybrid environments, a design grounded in clear principles always outlasts a design tied to tools.
As data volumes, regulations, and analytical demands grow, design quality becomes a competitive advantage. Investing time in structured modeling, governance, and continuous validation turns a data warehouse from a storage system into a dependable decision platform.
Frequently Asked Questions
Data warehouse design is the structured process of defining how data is modeled, stored, and accessed to support analytics. It includes choosing schema types, integration methods, and governance rules that ensure consistency, performance, and scalability across the entire data lifecycle.
Effective design focuses on subject orientation, integration, time variance, and non-volatility. These characteristics make data consistent across systems, historical for trend analysis, and stable for reliable reporting without affecting source operations.
Key considerations include scalability, data quality, governance, security, and query performance. Designers must balance technical efficiency with compliance and future flexibility, ensuring the architecture supports growth, regulatory change, and evolving analytical needs.
The process follows sequential stages: gather requirements, create conceptual and logical models, choose architecture and schema types, plan ETL or ELT pipelines, validate through testing, and document governance. Design decisions should align with business goals, data sovereignty, and cost efficiency.
Typical patterns are star schema, snowflake schema, data vault, and galaxy schema. Each pattern defines how fact and dimension tables connect to balance performance, storage, and data integrity.
In analytics, design patterns usually refer to structural, behavioral, integration, and governance patterns. These describe repeatable solutions for data modeling, transformation, workflow, and access control.
The most used patterns are batch ETL, real-time streaming, API-based integration, change data capture (CDC), and federated query. Each suits different latency and data-quality requirements.
Marketing data warehousing centralizes campaign, customer, and channel data for analytics. It enables unified performance tracking, segmentation, and attribution by integrating sources such as CRM, ad platforms, and web analytics into one governed structure.