
Data Warehousing and Data Mining: From Theory to Practice

A data warehouse stores structured data from multiple sources for reporting and analytics. Data mining examines that data to identify patterns, trends, and correlations. Together, they turn raw records into usable business intelligence.
This relationship defines how modern analytics operates: the data warehouse provides organization and accessibility, while data mining delivers interpretation and prediction. Both depend on data quality, query performance, and scalable processing, areas where MPP systems like Exasol’s Analytics Engine significantly reduce query latency and resource strain.
What Is Data Warehousing?
A data warehouse is a centralized repository that aggregates and stores structured data from different operational systems. Its primary purpose is to create a consistent, query-ready foundation for analytics, reporting, and decision support.
Most data warehouses follow a layered structure:
- Staging area: temporary zone where raw data is copied from source systems.
- Integration layer: where transformation and cleansing occur.
- Presentation layer: where analysts access standardized tables and views through SQL or BI tools.
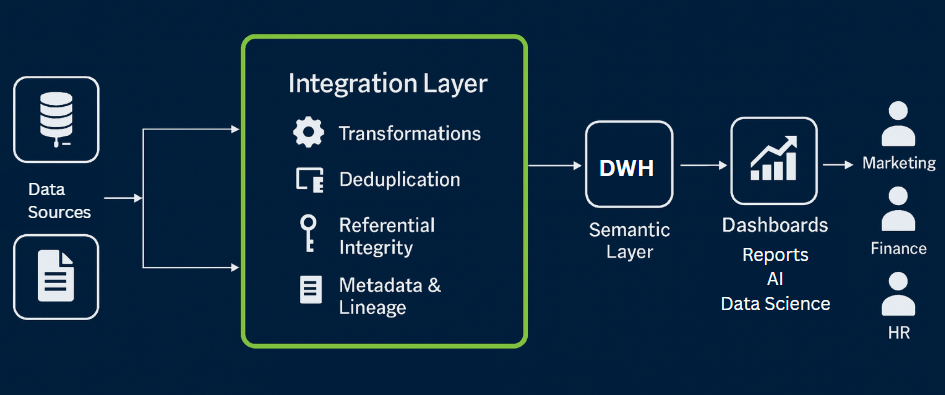
Unlike transactional databases that handle constant inserts and updates, a data warehouse is optimized for reading, aggregation, and large-scale joins. Queries often scan millions or billions of rows to produce summaries, KPIs, or trend analyses.
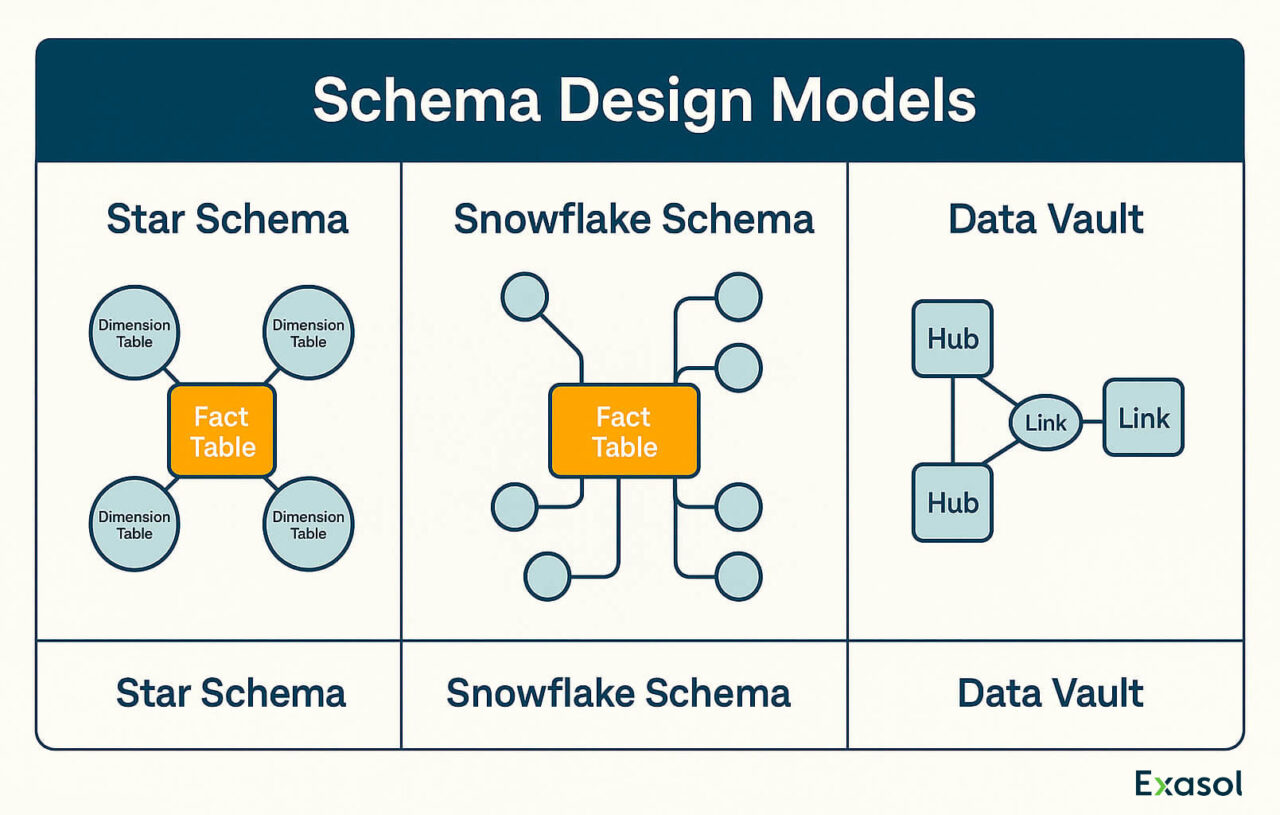
Common design patterns include:
- Star schema: a central fact table connected to dimension tables (e.g., customer, product, time).
- Snowflake schema: an extension of the star model that normalizes dimension data to reduce redundancy.
- Data vault: a model emphasizing auditability and historical traceability of all changes.
Data warehouses can be deployed on-premises, in the cloud, or as hybrid architectures combining both. Each approach has trade-offs. On-premises systems provide sovereignty and predictable performance. Cloud platforms offer elasticity but depend on network latency and cost per query. Hybrid setups attempt to balance both.
Performance characteristics:
A modern data warehouse can handle parallel query execution, columnar storage, and memory-based caching. Exasol’s architecture, for example, stores data in memory and distributes workloads across multiple nodes. This allows analysts to run complex SQL queries in seconds instead of minutes, even when multiple users query the same dataset concurrently.
Integration and governance:
ETL or ELT pipelines feed the data warehouse using connectors to relational databases, APIs, or file systems. Governance depends on metadata catalogs, lineage tracking, and access control. Standards such as ISO/IEC 11179 define how metadata registries should manage definitions and relationships between data elements.
A data warehouse’s value depends on three measurable factors: accuracy of data ingestion, query performance, and scalability under load. Every architectural decision (storage format, compression method, parallelism level) affects these outcomes.
When maintained properly, a data warehouse provides the single version of truth for all analytical workloads. It becomes the system of record that feeds dashboards, machine-learning models, and performance reports.
What Is Data Mining?
Data mining is the analytical process of identifying patterns, correlations, and anomalies within large datasets stored in a data warehouse or data lake. Its objective is discovery: finding relationships that are not immediately visible through basic aggregation or reporting.
A typical data mining workflow starts after the data warehouse has integrated and cleaned data from multiple sources. Analysts or data scientists use statistical models and algorithms to explore that data. Common techniques include:
Classification: grouping records into predefined categories using supervised learning models.
- Clustering: identifying natural groupings within data without labeled outcomes.
- Association rule data mining: uncovering dependencies such as “customers who buy X also buy Y.”
- Regression analysis: estimating relationships between variables for forecasting.
- Anomaly detection: spotting outliers that deviate from expected behavior, useful in fraud detection or network monitoring.
Data mining combines database querying with machine learning. SQL handles selection and aggregation. Algorithms (implemented in Python, R, or in-database functions) perform higher-level pattern recognition. In Exasol, user-defined functions (UDFs) allow these algorithms to run directly in the database layer, reducing data movement and latency.

On-Demand Webinar
Master User-defined Functions (UDFs)
Practical tips, advanced analytics, and AI.
Key requirements:
- Clean, well-structured, and complete data.
- Compute resources sufficient to process high volumes efficiently.
- Transparent results that can be interpreted and acted upon.
When data mining is effective, the outcome is actionable knowledge. A retailer might identify purchase sequences that predict churn. A bank could isolate variables influencing credit default risk. A logistics provider can find correlations between shipment delays and weather events.
Data mining methods vary depending on the problem domain:
- Descriptive mining looks at what happened.
- Predictive mining estimates what might happen next.
- Prescriptive mining recommends how to respond.
Exasol supports these approaches through parallel query execution, in-memory processing, and integration with data science tools. That allows analysts to train, test, and run models without exporting terabytes of data to external systems.
Data mining depends on both the quality and structure of the underlying data warehouse. Without a consistent schema, relationships between entities break down. Without sufficient query performance, even simple clustering can stall. The stronger the data warehouse foundation, the more effective the data mining outcomes.
To continue exploring how this foundation is built, see our data warehouse architecture guide for structural best practices.
Data Mining vs Data Warehousing: Key Differences
Data warehousing and data mining often appear together, but they serve distinct functions in the analytics pipeline. The data warehouse manages storage and access. Data mining extracts insight. Both depend on structure, governance, and computational efficiency.
| Aspect | Data Warehousing | Data Mining |
|---|---|---|
| Purpose | Collect, organize, and store historical data for reporting and analytics. | Identify hidden patterns and relationships within stored data. |
| Process | Extract, transform, and load (ETL/ELT) from multiple sources into a unified schema. | Apply statistical, machine learning, or rule-based algorithms to existing datasets. |
| Data Type | Primarily structured, modeled in relational or columnar format. | Structured, semi-structured, or unstructured data depending on the technique. |
| Output | Clean tables and data marts for analysis. | Predictive insights, clusters, correlations, or decision rules. |
| Tools and Methods | SQL, BI tools, query optimizers, metadata catalogs. | Python, R, UDFs, or specialized frameworks integrated with SQL engines. |
| User Profile | Data engineers, architects, analysts. | Data scientists, analysts, domain experts. |
| Storage Focus | Capacity, consistency, scalability. | Computation, model accuracy, interpretability. |
| Dependency | Prerequisite for data mining: supplies clean, integrated data. | Consumes data warehouse data and generates analytical outcomes. |
Both processes complement each other. Data warehousing enables consistent access and performance. Data mining converts that foundation into measurable business outcomes.
Practical workflow:
- Data sources load into the data warehouse through ETL or ELT processes.
- The data warehouse standardizes structure and ensures referential integrity.
- Analysts run exploratory queries to understand distributions and relationships.
- Data mining algorithms operate on those datasets, producing models or associations.
- Results feed back into dashboards, applications, or decision systems.
When performance becomes a constraint, in-memory MPP systems can remove most I/O delays. Learn how this works in practice in our analytics acceleration use case.
When this loop works efficiently, organizations move from static reporting to adaptive intelligence. Data warehousing ensures reliability; data mining delivers foresight.
How Data Warehousing and Data Mining Work Together
A data warehouse and a data mining layer function as two halves of one analytical system. The data warehouse stores, integrates, and secures data. Data mining turns that foundation into intelligence.
The relationship follows a consistent flow:
- Data integration. Multiple operational sources (CRM, ERP, IoT, or logs) feed into the data warehouse through ETL or ELT. The goal is uniform structure and reliable lineage.
- Data preparation. The data warehouse enforces schema consistency, applies transformations, and exposes curated tables. Without this step, data mining models inherit noise and bias.
- Exploration. Analysts query data to detect distributions and anomalies before applying algorithms.
- Modeling. Data mining uses that same data warehouse data to build statistical or machine-learning models.
- Feedback. Insights flow back into business systems or dashboards, improving forecasts, segmentation, and operational planning.
This closed loop only works when the data warehouse engine handles parallel execution and high concurrency. Performance characteristics that matter:
- Query latency under heavy load.
- Efficient joins across billions of rows.
- Ability to execute complex algorithms directly in SQL or UDFs.
- Stable throughput as concurrent users increase.
Exasol’s in-memory MPP architecture is designed for that environment. It lets data mining workloads run close to the data instead of exporting large volumes to external tools. Each node processes part of the dataset in parallel, then merges results through distributed joins.
Example workflow:
A telecom company logs millions of daily transactions. Its Exasol data warehouse ingests this data in real time. Data scientists then apply churn prediction models directly within the data warehouse using Python UDFs. Because the data never leaves the system, training iterations finish in minutes. Marketing receives predictive lists before the next campaign launch.
This model avoids two common issues: slow data export and version drift between datasets. Data mining runs on the same governed tables that reporting teams use, keeping all metrics consistent.
Modern Context: From BI to AI
The boundary between data warehousing and data mining has blurred as analytics has evolved from historical reporting to predictive and generative models. What began as structured SQL queries now includes machine learning, vector embeddings, and language model integration.
Shift in analytical maturity:
- Traditional BI: focused on what happened; dashboards, KPIs, and static reports.
- Predictive analytics: estimates what will happen next through regression and classification.
- Prescriptive analytics: recommends specific actions using optimization or simulation models.
- AI-driven analytics: automates discovery and decision-making through natural language, semantic search, and LLM agents.
Each stage increases computational demand. These four approaches (from descriptive through prescriptive analytics) frame the evolution from BI to AI. Data mining algorithms that once ran offline now execute continuously as part of streaming or real-time pipelines. That change exposes weaknesses in architectures that separate storage and compute too strictly.
In-memory systems such as Exasol’s Analytics Engine address this by collapsing those boundaries. Queries, transformations, and AI workloads operate in one execution layer. That minimizes data movement and improves concurrency under multi-user load.
Governance and sovereignty matter more than before.
Standards such as the IEEE SA initiative on Autonomous and Intelligent Systems provide frameworks for ethical and accountable design.
AI models can generate predictions, but without context, they risk amplifying bias or exposing private data. When models run directly within a governed data warehouse, access control and lineage remain intact. Exasol’s architecture supports this by enforcing SQL-level permissions while still allowing Python, R, or Java execution through UDFs.
This design supports sovereign AI: computation under full data control, often required in regulated sectors such as finance or healthcare. It also enables text-to-SQL translation through model context protocols (MCP), where a language model receives schema metadata and generates SQL safely within policy constraints.
Performance implications:
- AI workloads require vector processing, parallel joins, and high memory bandwidth.
- Data warehouses that already support distributed execution can integrate these features faster.
- Systems without such architecture depend on external pipelines, adding latency and cost.
Data warehousing and data mining no longer exist as separate stages. They form a single analytical substrate capable of traditional BI, predictive modeling, and AI-assisted querying. The closer those layers operate, the faster and safer an enterprise can iterate on its data-driven initiatives.
Florian Wenzel, VP of Product, Exasol
Practical Example: WashTec AG
WashTec AG operates over 50,000 car-wash installations that clean more than three million vehicles per day across multiple continents. Each machine generates operational, maintenance, and transaction data. Before implementing Exasol, that data lived in disconnected systems, making performance tracking and predictive maintenance slow and inconsistent.
Step 1: Data Warehousing
WashTec consolidated telemetry and sales data into a central Exasol data warehouse. ETL pipelines load readings from sensors, usage counters, and service logs into fact tables connected to time, location, and equipment dimensions. The data warehouse replaces dozens of local databases and provides one analytical source of truth.
Step 2: Preparation
Data engineers model usage metrics and derive aggregates such as “average wash duration,” “chemical consumption per cycle,” and “error frequency per nozzle.” The data warehouse maintains both granular and summarized views so analysts can query operational trends in real time.
Step 3: Data Mining
Data scientists apply statistical and machine-learning models directly in the database through Python UDFs. Algorithms identify early signs of component wear and flag sites where consumption patterns deviate from expected norms. Because Exasol executes the code inside its in-memory MPP engine, each model run processes millions of rows in seconds without exporting data to external compute clusters.
Step 4: Operationalization
Predictions feed back into maintenance planning. Service teams receive prioritized task lists generated from model outputs. Store managers view local performance dashboards that update automatically as new sensor data arrives.

Outcomes:
- Query execution improved by more than 10× compared with the legacy setup.
- Analytical cycles shortened from hours to minutes.
- Machine downtime decreased as predictive maintenance replaced reactive scheduling.
This project illustrates how data warehousing and data mining reinforce each other. The Exasol data warehouse provides the unified, governed base layer. Data mining transforms it into proactive intelligence that drives measurable operational gains.
Key Takeaways
- Data warehousing and data mining are inseparable. One organizes data for access; the other extracts value from it. Treating them as separate projects slows insight delivery.
- Performance determines usefulness. Data mining algorithms only work as fast as the data warehouse allows. Exasol’s in-memory MPP design minimizes I/O and enables direct in-database modeling.
- Governance is not optional. Clean metadata, access control, and lineage make analytical results trustworthy. Weak governance breaks model reliability and auditability.
- AI and ML extend, not replace, data mining. Advanced models depend on high-quality, well-modeled data warehouse data. Without that base, predictions degrade quickly.
- Integration reduces latency. Keeping warehousing, querying, and data mining within one execution layer avoids duplication, data drift, and cost.
- Real-world impact is measurable. WashTec’s deployment shows how warehousing and data mining together cut processing time, reduced downtime, and delivered continuous operational visibility.
These principles define a modern analytical environment. A data warehouse without data mining is storage; data mining without data warehousing is guesswork. Together, they create the analytical backbone for reliable, high-speed decision-making.
Frequently Asked Questions
The four main stages are data preparation, pattern discovery, evaluation, and deployment. Preparation cleans and integrates data. Pattern discovery applies algorithms such as clustering or classification. Evaluation checks accuracy and relevance. Deployment embeds results into business workflows.
No. ETL belongs to data warehousing, not data mining. ETL extracts and transforms data before loading it into a data warehouse. Data mining begins only after the data is already integrated and modeled.
Typical components are the data source layer, ETL or ELT process, storage layer, and presentation or access layer. Each ensures data moves from raw collection to a structured environment for analytics.
They are data extraction, transformation, loading, and presentation. Extraction collects from multiple systems, transformation standardizes and cleanses, loading writes data into data warehouse tables, and presentation provides access for BI tools or data mining applications.