Data Warehouse Architecture: Complete Guide with Models, Trends & Examples

Data warehouse architecture is the foundation behind how businesses collect, store, and analyze data at scale. Whether you’re modernizing analytics, building a hybrid stack, or connecting multiple data sources, your architecture choices shape everything — from performance and scalability to compliance and cost.
This guide breaks down everything you need to know. We’ll walk you through the core components, types of architectures (from classic three-tier models to modern cloud-native designs), schema patterns, and emerging trends like lakehouse, data mesh, and real-time pipelines. You’ll also find practical advice on design decisions, common pitfalls, and which architecture suits your specific needs.
Whether you’re designing a new data warehouse or optimizing an existing one, this guide is built to help you make informed, future-proof choices.
What Is Data Warehouse Architecture?
Data warehouse architecture refers to the structured design of how data flows from various source systems into a centralized data warehouse, and how it is processed, stored, and made accessible for analytics and reporting.
At its core, this architecture defines:
- Where the data comes from (e.g., databases, APIs, files)
- How the data is moved and transformed (ETL or ELT processes)
- Where the data lives (the warehouse itself)
- How the data is consumed (via BI tools, dashboards, or applications)
A well-designed architecture ensures:
- Consistent and accurate data across systems
- Scalable performance for complex queries
- Easy integration with modern analytics tools
- Compliance with security, governance, and data sovereignty requirements
The architecture you choose affects everything from query speed to operational cost to regulatory compliance, making it one of the most strategic decisions in your data infrastructure.
Example: A classic three-tier architecture moves data from source systems into a staging area, then into a central warehouse, and finally into reporting tools. But today’s data warehousing architectures may also include data lakes, real-time processing, and hybrid cloud environments.
How Data Warehouse Architecture Works: Key Layers and Components
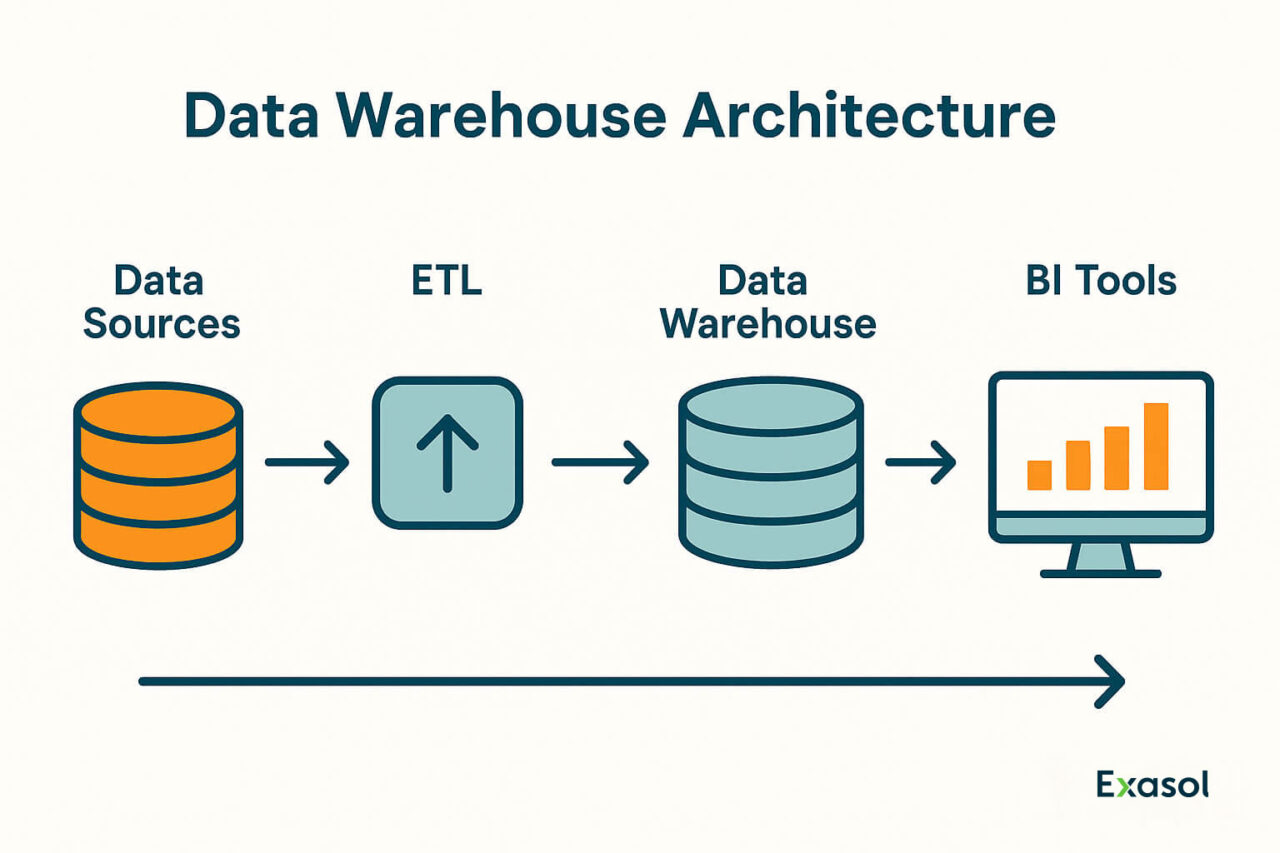
A well-designed data warehouse architecture transforms scattered, messy data into trusted, accessible insights. Whether you’re working with on-prem systems, cloud services, or real-time pipelines, the core structure remains consistent, but the components you choose make all the difference.
Let’s walk through each layer, adding clarity to the roles, technologies, and decisions involved.
1. Data Sources
Everything starts with the raw inputs. These can come from:
- Operational databases (e.g., PostgreSQL, Oracle, SQL Server)
- Enterprise applications like CRM or ERP systems
- External platforms via APIs (e.g., Salesforce, Google Ads)
- Cloud storage (e.g., Amazon S3, Azure Blob)
- Flat files and logs
- Streaming data from IoT devices or real-time feeds (e.g., Kafka)
The diversity of formats and update speeds requires a robust integration strategy upstream.
2. Data Integration Layer (ETL / ELT)
This is where raw data becomes analytics-ready. Traditionally, teams used ETL (Extract → Transform → Load), but modern platforms often use ELT (Extract → Load → Transform) — loading first, then transforming data inside the warehouse.
Common tasks in this layer include:
- Data cleansing and validation
- Normalization and schema mapping
- Merging duplicates and enriching records
- Ensuring compliance with privacy rules and data sovereignty
With platforms like Exasol, ELT becomes more efficient thanks to in-database processing and high-speed compute.
3. Central Data Warehouse
This is the heart of your architecture — a centralized system that stores structured, historical data and powers complex analytics. Key features include:
- Scalability for large data volumes
- Fast performance for real-time dashboards and queries
- Consistency as a single source of truth across departments
Modern enterprise data warehouses, including Exasol, are designed to handle demanding workloads while remaining cost-efficient and flexible — whether deployed on-premises, in the private cloud, or hybrid.

Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
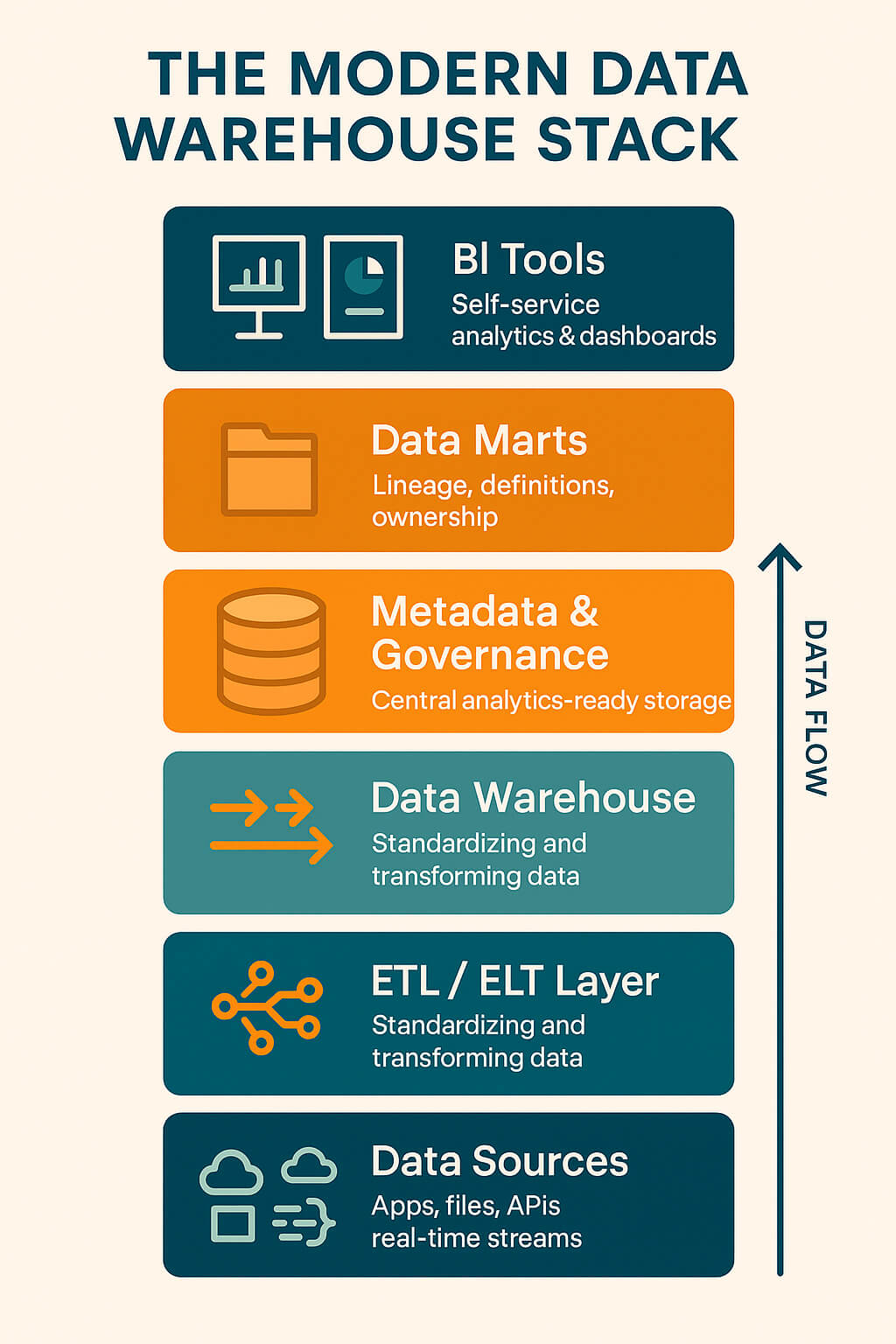
4. Metadata and Governance Layer
Sitting alongside the warehouse is the metadata layer, which documents:
- Where data comes from (lineage)
- How it’s defined and transformed
- Who owns or consumes it
This layer supports governance, discoverability, and compliance, especially important in regulated industries or multi-team environments.
5. Data Marts
Data marts are subject-specific subsets of the warehouse designed for particular departments or use cases — for example:
- A finance mart for revenue and forecasting data
- A marketing mart for campaign performance and attribution
They improve performance, reduce complexity for end users, and support role-based access control.
6. BI and Analytics Tools
The final layer is where users access insights:
- Executives viewing dashboards in Power BI
- Analysts building custom reports in Tableau
- Data scientists querying live data for models
These tools connect directly to the central warehouse or to data marts, depending on the use case. Performance at this layer depends heavily on the quality of everything upstream.
For more technical teams, creating a detailed dwh architecture diagram can support implementation planning and clarify how data flows through integration, storage, and access layers.
Types of Data Warehouse Architectures
While the core components of a data warehouse remain consistent, the way you structure them can vary significantly depending on your needs. Over time, several architecture types have emerged — each offering different levels of flexibility, performance, and complexity.
Here’s a breakdown of the most common warehouse architecture approaches:
1. Hybrid Architecture
A blend of traditional on-premises systems and modern cloud-native components. This model allows organizations to modernize gradually — keeping legacy systems where needed, while adding flexible, scalable cloud services on top.
- ✅ Pros: Flexibility, cost control, easier modernization
- ❌ Cons: Complexity in orchestration, governance, and latency management
- 📌 Best for: Enterprises transitioning from legacy systems or operating in highly regulated environments
Example: Keeping sensitive data on-premises while using cloud-based tools for analytics or machine learning.
To get a better understanding of the pros and cons, we’ve built an extensive guide: on premise vs cloud.
2. Single-Tier Architecture
A rare, simplified setup where all functions — storage, transformation, analytics — are handled in a single layer.
- ✅ Pros: Minimal latency, easy to set up
- ❌ Cons: Poor scalability and limited governance
- 📌 Best for: Prototyping or very small-scale deployments
3. Two-Tier Architecture
Separates the storage layer from the presentation layer. Transformations may happen in the warehouse or within BI tools.
- ✅ Pros: Simpler than 3-tier, faster data access
- ❌ Cons: Can create performance bottlenecks at scale
- 📌 Best for: Small to mid-sized businesses
4. Three-Tier Architecture
The traditional enterprise model is often mapped out in an enterprise data warehouse architecture diagram, highlighting how data flows through sources, transformation layers, and BI tools.
- Data sources (bottom tier)
- ETL and staging layer (middle tier)
- BI and analytics (top tier)
- ✅ Pros: Scalable, secure, modular
- ❌ Cons: Not optimized for real-time or cloud-native use cases
- 📌 Best for: Organizations with complex governance needs and well-defined reporting flows
5. Hub-and-Spoke Architecture
Uses a central warehouse (hub) and departmental data marts (spokes). Each team gets tailored data, while still aligning with central governance.
- ✅ Pros: Department-level flexibility
- ❌ Cons: Risk of data duplication or inconsistency
- 📌 Best for: Large companies with federated team structures
6. Federated Architecture
Data stays in multiple, independent systems and is queried on demand via virtualization layers or APIs — no central repository required.
- ✅ Pros: No data movement; quick to implement
- ❌ Cons: Lower performance; harder to manage complex joins
- 📌 Best for: Organizations with strict data residency or real-time access needs
7. Cloud-Native Architecture
Built on cloud data warehouses and designed for scale, speed, and elasticity. Separates storage from compute and supports ELT, streaming, and auto-scaling.
- ✅ Pros: Extremely scalable, high performance, low infrastructure overhead
- ❌ Cons: Requires cloud expertise and strong cost monitoring
- 📌 Best for: Digital-first and analytics-driven organizations
Choosing the Right Architecture
Your architecture should reflect your business goals, not just your tech stack. Factors to consider:
- How fast your data grows
- Regulatory or security constraints
- Real-time vs batch processing needs
- Budget, team maturity, and existing infrastructure
In enterprise environments, teams often use an edw architecture diagram to compare different architecture types and communicate how staging areas, data marts, and analytics layers align across models.
In 2025, most enterprise architectures are hybrid by default — blending traditional and cloud components to balance control, performance, and agility.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Schema Design Models: Star, Snowflake & Beyond
Once you’ve chosen your data warehouse architecture, the next key decision is how to organize your data inside the warehouse — and that’s where schema design comes in.
Schemas define the logical data warehouse structure, including how fact and dimension tables relate to each other. The right schema design ensures fast queries, easy maintenance, and a structure your BI tools can easily understand. In other words, schema impacts everything from query performance to data governance and scalability.
Let’s explore the most common models and how they apply in practice, using Exasol as an example of a high-performance Analytics Engine.
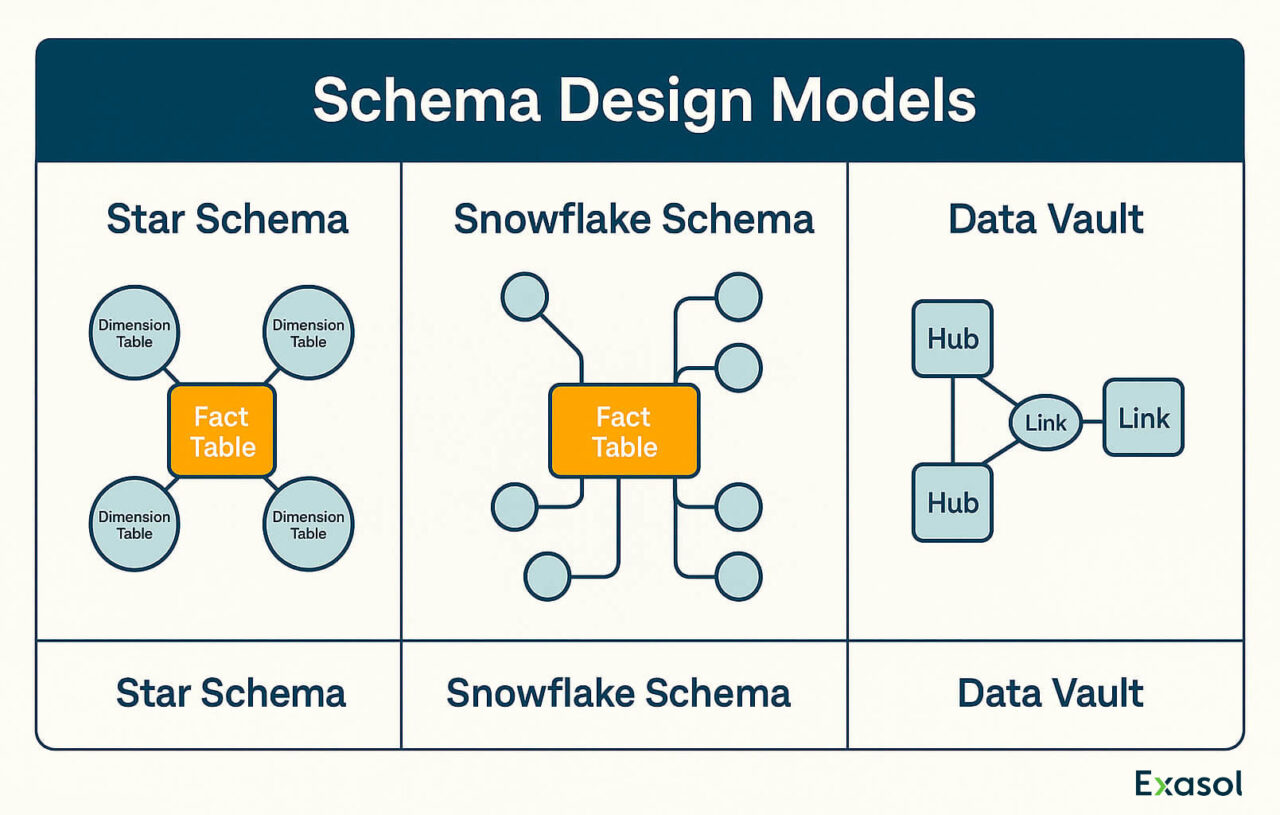
Star Schema
The star schema is widely used for analytical workloads. It features:
- A central fact table containing measurable events (e.g., sales, clicks)
- Several dimension tables describing the context (e.g., product, customer, region)
Each dimension connects directly to the fact table, creating a “star” pattern.
- ✅ Strengths: Simpler design, excellent for BI tools and dashboards
- ❌ Trade-offs: Some data redundancy due to denormalization
Real-world use: In Exasol implementations, star schemas are often used for reporting layers where low-latency querying is essential. Its in-memory analytics engine supports fast joins even across large fact tables.
Snowflake Schema
The snowflake schema builds on the star model by further normalizing dimensions:
- Dimensions are split into related sub-tables (e.g., Region → Country → City)
This reduces redundancy but adds complexity.
- ✅ Strengths: Better storage efficiency, stronger data integrity
- ❌ Trade-offs: Requires more joins, which can slow down performance in less-optimized systems
Real-world use: Some Exasol users choose snowflake schemas to align with strict governance policies, especially when working with shared dimensions across multiple business units. The system handles multi-join queries efficiently, making it a viable choice without performance bottlenecks.
Data Vault Modeling
Data Vault is a modular, scalable modeling technique designed for agility. It splits data into:
- Hubs: unique business keys (e.g., customer ID)
- Links: relationships (e.g., transactions)
- Satellites: descriptive or historical attributes
- ✅ Strengths: Scalable, audit-friendly, easy to evolve
- ❌ Trade-offs: Complex to query; often needs additional data marts for consumption
Real-world use: Exasol is sometimes used as a presentation layer on top of a Data Vault model managed in another system. Teams load cleansed, modeled data into Exasol for fast access and visualization.
Schema design isn’t one-size-fits-all. Many teams use a combination: normalized models for loading, star schemas for analytics, and data marts tuned for business users.
While Star, Snowflake, and Data Vault are the most commonly used schema models for modern data warehouses, others like the Galaxy schema (used for multi-fact table models) and Flat schema (used for quick, denormalized reporting) also appear in specific use cases — though they’re typically variations or extensions of the core approaches above.
Galaxy Schema (aka Fact Constellation)
A galaxy schema connects multiple fact tables that may share dimension tables — essentially a collection of interconnected star schemas.
- ✅ Pros: Allows you to model multiple business processes (e.g., sales and inventory) using shared dimensions
- ❌ Cons: More complex to manage and query
- 📌 Best for: Large enterprise models with overlapping domains
Example in Exasol: A company using one fact table for web sales and another for store sales, both referencing the same “Customer” and “Product” dimension tables.
Flat Schema (Denormalized)
This schema has all relevant data in a single wide table — no joins needed.
- ✅ Pros: Easy to understand, very fast for small-scale dashboards
- ❌ Cons: Not scalable; duplicative and hard to maintain
- 📌 Best for: Lightweight use cases, rapid prototyping, exports to BI tools
Example in Exasol: Teams exporting flattened views to Tableau or Power BI where performance is prioritized over maintainability.
Modern Trends in Data Warehouse Architecture
Data warehousing has evolved rapidly over the past decade. While traditional models still exist, today’s architectures are increasingly shaped by flexibility, speed, and cloud-native design — often blended into hybrid deployments.
Here are the most important trends shaping modern data warehouse architecture today:
1. Hybrid Architecture
We’ve already mentioned hybrid architecture, but it’s well worth a separate mention in the trends section. A hybrid data ware architecture combines on-premises systems with cloud-based components, often used by organizations that:
- Have regulatory or data sovereignty requirements
- Want to modernize gradually
- Need local compute power with cloud scalability
Typical setup:
Critical workloads (e.g., financial data) stay on-premises, while analytics and AI workloads run in the cloud.
Insider tip: Exasol is often used in hybrid setups where speed, flexibility, and deployment neutrality are required.
Hybrid Architecture: What Works in 2025
Learn from real-world setups in this expert-led webinar.
2. Cloud-Native Data Warehousing
Platforms like Snowflake, BigQuery, and Redshift are designed to:
- Separate storage and compute
- Scale elastically based on demand
- Reduce infrastructure management overhead
This enables rapid experimentation, global access, and tight integration with cloud-native tools.
Use case: Running scalable analytics workloads with zero hardware maintenance.
3. Real-Time and Streaming Data
With the rise of IoT and fast-changing customer behavior, more businesses need real-time analytics.
Architectures now often include:
- Streaming pipelines using Kafka, Flink, or Kinesis (here you can find a great technical overview of Kafka’s stream processing model)
- Change data capture (CDC) tools to reflect DB updates in real time
Example: Fraud detection systems that analyze transaction patterns as they happen.
4. Lakehouse Architecture
A lakehouse combines the scalability of data lakes with the structure and performance of data warehouses, as explored in this deep dive on lakehouse vs. warehouse vs. data lake.
Key features:
- Supports both structured and unstructured data
- Enables machine learning, BI, and data science in one platform
- Reduces duplication and improves governance
Often built on technologies like Delta Lake, Apache Iceberg, or cloud-native platforms like Databricks.
5. Data Mesh
Data Mesh moves away from centralized monoliths and toward domain-oriented, decentralized data ownership, a concept outlined by Martin Fowler, who helped formalize its core principles for modern data architecture.
Core principles:
- Data as a product
- Domain teams own and serve their own data
- Federated governance ensures consistency
Common in complex organizations with multiple business units, each managing their own pipelines and schemas.
6. Serverless and Elastic Architectures
Serverless models abstract infrastructure completely — you just run queries, and the system scales automatically.
Benefits:
- Zero maintenance
- Pay-per-use efficiency
- Great for unpredictable workloads
Example: Running on-demand analytics jobs without pre-provisioned compute clusters.
7. AI/ML-Integrated Warehousing
Modern data warehouses increasingly support AI/ML workloads alongside traditional BI.
Capabilities include:
- In-database ML model training or inference
- Native Python, R, or SQL extensions
- Support for feature stores and data prep at scale
Trend: Unified platforms for business intelligence and data science workflows.
Many modern architectures are not defined by a single trend, but by how these elements are combined.
Implementation Considerations
Designing the right architecture is only half the battle — executing it successfully requires thoughtful decisions around infrastructure, people, and process. Whether you’re modernizing a legacy system or building from scratch, these implementation factors will shape the long-term success of your data warehouse.
1. Performance Optimization
A fast data warehouse isn’t just about compute power — it’s about efficient design:
- Partitioning large tables to reduce scan times
- Materialized views to cache frequent aggregations
- Optimizing joins and query logic in BI tools
Tip: Monitor query patterns early, and design with real workloads in mind, not theoretical ones.
2. Cost Management
With cloud platforms and hybrid models, cost efficiency is an ongoing concern:
- Track compute vs storage usage separately (especially in elastic architectures)
- Use auto-scaling and pause/resume features where possible
- Avoid long-running queries or unoptimized dashboards
- Watch for hidden costs in orchestration or data movement (e.g., cross-region transfers)
Tip: Define chargeback models early if multiple teams will use the same platform.
3. Data Governance & Compliance
Modern architectures must meet evolving requirements around:
- Data privacy (e.g., GDPR, CCPA)
- Access controls and role-based security
- Data lineage and audit logs
- Metadata management and cataloging
Tip: Build governance into your architecture, not as an afterthought.
4. Tooling & Orchestration
Smooth operations depend on a well-integrated toolchain:
- ETL/ELT orchestration: Airflow, dbt, Fivetran, Matillion
- Monitoring & observability: Monte Carlo, OpenLineage, Prometheus
- Version control & CI/CD pipelines for data workflows
- Metadata management tools (e.g., DataHub, Collibra)
Tip: Choose tools based on team maturity, and integrate them gradually.
5. Team Structure & Skills
Whether you’re a data engineer, BI developer, or data warehouse architect, your architecture must align with how your team builds, operates, and maintains it. Consider:
- Does your team have cloud experience or SQL/data modeling skills?
- Are responsibilities split clearly between data engineers, BI developers, and analysts?
- Can you support DevOps-style workflows for data?
Tip: The most scalable architectures align with clear team ownership, not just technical excellence.
A great data warehouse isn’t just designed well — it’s managed, optimized, and understood by the people who rely on it.
Try Exasol Free: No Costs, Just Speed
Run Exasol locally and test real workloads at full speed.
Real-World Examples: From Legacy to Hybrid Analytics
To bring these concepts to life, let’s walk through real-world examples of how two companies re-architected their data warehouse to improve performance, flexibility, and scalability — using a hybrid model and modern schema design.
Helsana: Modernizing Healthcare Analytics with Hybrid Architecture
Challenge: Helsana, a leading Swiss health insurer, faced challenges with a fragmented data infrastructure. Disparate business units relied on various reporting tools and fragmented data warehouses, leading to inefficiencies and complexity.
Solution: Helsana consolidated its fragmented data and analytics infrastructure onto a single platform, underpinned by consistent standards, centralized governance, and metadata-driven automation. The adoption of Exasol’s Data Warehouse, alongside WhereScape for ETL and MicroStrategy for self-service reporting, streamlined operations and unleashed newfound agility.
Results:
- Query speeds improved up to 10x, data loads cut from 26 to 4 hours, and license & maintenance costs reduced by 65%.
- Established a foundation for AI-powered analytics, empowering deeper exploratory analysis and paving the way for AI-driven data visualization and reporting.
WashTec: Leveraging Hybrid Architecture for Predictive Maintenance
Challenge: WashTec, a global leader in car wash solutions, needed to enhance its operations and customer experience by leveraging advanced data infrastructure and machine learning.
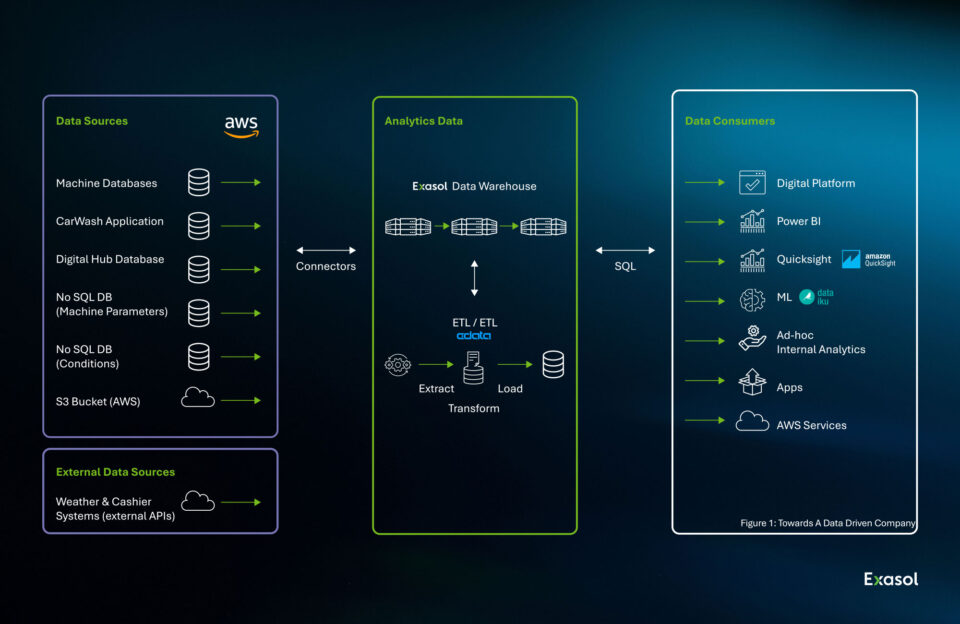
Solution: WashTec implemented Exasol as its central data warehouse, chosen for its high performance and scalability. This move allowed WashTec to consolidate and analyze large volumes of data from its connected machines. The company then integrated multiple data sources into this central repository, including SQL databases, NoSQL databases, and JSON documents from machine software.

Results:
- Substantial reduction in unexpected machine downtime.
- Optimized resource allocation and markedly improved customer satisfaction.
- Established new benchmarks for efficiency and service quality in the car wash industry.
These examples illustrate how organizations across different industries successfully modernized their data infrastructures using hybrid architectures, leading to significant performance improvements and operational efficiencies.
Conclusion & Key Takeaways
Designing and implementing the right data warehouse architecture is no longer just a technical decision — it’s a strategic one. As businesses scale, modernize, and adapt to real-time demands, the underlying architecture determines how fast, trustworthy, and cost-effective data-driven decisions can be.
The key isn’t chasing the latest trend — it’s building the architecture that fits your organization’s needs, existing infrastructure, and future ambitions.
- Start with clarity: Understand your current data flows, team capabilities, and reporting needs before jumping into tooling or models.
- Choose a scalable architecture: Hybrid and cloud-native setups offer the flexibility to evolve over time.
- Design for performance and governance: Schema design, ETL/ELT strategies, and metadata management directly affect how fast and trusted your data becomes.
- Modern doesn’t mean complex: Many successful companies use simple, efficient star schemas combined with smart tooling to achieve outstanding results.
- Don’t go it alone: Tools and platforms like Exasol, when used strategically, allow teams to focus less on infrastructure and more on insight.
There’s no one-size-fits-all approach — but there is a well-structured, future-proof path for every organization.