
Advantages of a Data Warehouse (Top Benefits & Trade-offs)

A data warehouse is a centralized system that consolidates data from multiple sources to support reporting, analysis, and long-term decision-making.
This page digs deep into the core advantages of a data warehouse and the measurable benefits of data warehouse adoption, from creating a single source of truth to enabling historical analysis, improving data quality, and scaling analytics workloads. It also covers areas where challenges arise—such as cost management, vendor lock-in, and compliance overhead—and provides practical guidance on how to weigh these trade-offs.
By the end, you will understand both the strategic gains and the operational considerations that define successful enterprise use of a data warehouse.

Try a Modern Data Warehouse for Free
Run Exasol locally and test real workloads at full speed.
Key Benefits of a Data Warehouse
Single Source of Truth for All Data
A data warehouse integrates data from multiple systems—transactional databases, CRM platforms, ERP systems, and external feeds—into a consistent, structured repository. This removes conflicting versions of metrics and ensures every report is based on the same definitions.
For enterprises, this reduces disputes over “which number is correct” and enables teams to rely on a common dataset for forecasting, regulatory submissions, and performance analysis.
Architecture choices—such as layering, staging, and integration workflows—directly shape data consistency and flow. For a deeper breakdown of how these design decisions underpin consistency and performance, check our data warehouse architecture guide.
Historical Data & Long-Term Insights
Operational systems are built for current transactions, not long-term storage. A data warehouse retains years of historical data, optimized for analysis rather than day-to-day processing.
This historical depth allows enterprises to track performance across economic cycles, compare current results against long-term baselines, and identify patterns that would be invisible in short-term operational data. Examples include detecting seasonality in sales, monitoring customer lifetime value, or measuring the impact of regulatory changes over multiple years.
To revisit how foundational models support this capability, explore our basics on core data warehouse concepts.
Faster, Better Business Decisions
Because analytics run separately from operational systems, data warehouses handle complex queries without disrupting live transactions. Reports that once required overnight batches can be delivered in near real time.
The impact is practical: executives can base pricing, inventory, or compliance decisions on current data instead of outdated snapshots, a capability that defines the modern data warehouse.
Here is an example from our solution engineer, Larry Silverstein, who created a demo with Exasol and Tableau to showcase how fast data analysis can power business decisions:
Scalability & Flexibility
Flexibility extends to the data itself. Structured ERP tables, semi-structured logs, and streaming inputs can coexist in the same environment, making the data warehouse adaptable as business requirements evolve. This adaptability is critical for organizations scaling into an enterprise data warehouse environment.
Data Quality & Governance
Centralizing data in a data warehouse allows enterprises to apply standardized validation rules during loading. Inconsistent values, duplicate entries, and incomplete records are addressed before reaching dashboards.
Strong governance practices—such as metadata management, data lineage tracking, and role-based access control— strengthen trust in reporting and simplify audit preparation. This makes the data warehouse not only a technical platform but also a compliance asset.
These governance practices also highlight the differences in control between a data warehouse vs. data lake.
Security & Compliance Readiness
With proper configuration, a data warehouse enforces row-level security, column masking, and audit logging to control access and document usage.
For regulated industries, these controls align with frameworks such as GDPR, HIPAA, and SOC 2. Centralizing sensitive records reduces the burden of replicating security frameworks across multiple systems. Combined with encryption at rest and in transit, a data warehouse can demonstrate compliance in a way auditors can verify.
Compliance Mapping (Common Frameworks)
A data warehouse provides the technical controls that support—but do not replace—regulatory compliance.
| Control Area | Data Warehouse Capability | Relevant Frameworks |
|---|---|---|
| Access Control | Role-based access, integration with LDAP/SSO | GDPR, HIPAA, SOC 2, DORA |
| Audit Logging | Query history, user activity logs | GDPR, HIPAA, SOC 2, DORA |
| Data Retention | Partitioning, tiered storage, lifecycle policies | GDPR, HIPAA, DORA |
| Data Masking / Anonymity | Column-level security, dynamic data masking | GDPR, HIPAA |
| Encryption | In-transit (TLS) and at-rest encryption | GDPR, HIPAA, SOC 2, DORA |
| Disaster Recovery | Replication, failover, multi-region deployment | SOC 2, DORA |
| Liquidity / Risk Data | High-volume, auditable calculations and data lineage | Basel III (LCR, NSFR reporting) |
| Operational Resilience | Continuous availability, incident detection, recovery | DORA, SOC 2 |
Notes:
- GDPR & HIPAA → focused on personal/health data privacy and retention.
- SOC 2 → security, availability, confidentiality (audits often request access logs, encryption, recovery).
- DORA (Digital Operational Resilience Act) → applies to financial services in the EU, emphasizes ICT resilience, logging, incident handling.
- Basel III → requires reliable, auditable data pipelines for liquidity ratios (LCR, NSFR). The data warehouse underpins these calculations but compliance requires models + governance.
⚠️ Disclaimer: Technology alone is not compliance. These features provide controls, but enterprises must pair them with policies, governance, and audits to satisfy regulators.
Performance & Architecture Advantages
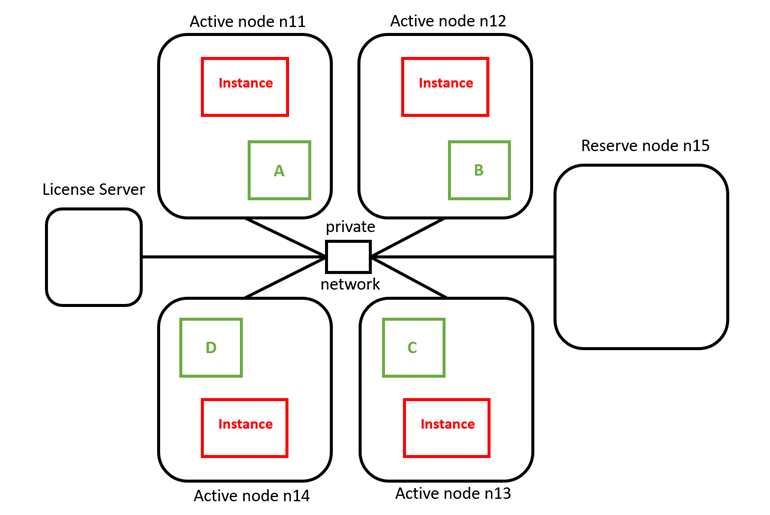
Concurrency & Workload Isolation
Companies run thousands of queries daily, often with sharp peaks during reporting cycles. Without workload isolation, ad-hoc analysis can compete with financial reporting or compliance checks, slowing both.
Modern data warehouses use resource queues and workload management policies to ensure predictable performance. Critical queries are prioritized, while exploratory analysis runs in parallel without disruption.
MPP Architecture
An MPP (massively parallel processing) architecture, like the one used in Exasol’s Analytics Engine, distributes data across multiple nodes. Queries are executed in parallel on each node, and results are aggregated, reducing runtime for large datasets.
This approach scales linearly: adding nodes increases both storage and processing capacity. For workloads that involve billions of rows, parallel execution can reduce query times from hours to minutes.
Columnar Storage & Compression
Analytical queries rarely need every attribute in a table. Columnar storage improves efficiency by reading only the required fields.
Combined with compression, this reduces both disk footprint and I/O. Ratios of 5:1 or higher are typical, cutting storage costs and allowing faster scans of large datasets.
Cost Considerations
Why Cost Modeling Matters
Companies rarely make decisions on features alone. A data warehouse that looks efficient in a demo can become expensive at scale if costs are not modeled. Finance and procurement teams expect a transparent view of total cost of ownership (TCO): not just license fees, but storage, compute, data movement, and administration.
Core Cost Drivers
To understand TCO, organizations must break down costs into measurable categories:
- Data volume — total data stored and queried per month.
- Concurrency — typical number of active users and queries.
- Query workload — reporting vs. ad-hoc analytics mix.
- Data transfer — movement between systems.
- Licensing and subscriptions — data warehouse software, integrations, support.
- Operations overhead — administration, monitoring, and optimization effort.
Each of these drivers scales differently. Storage grows steadily; compute can spike sharply during peak reporting. Ignoring these patterns leads to budget overruns.
By quantifying these factors, decision-makers can produce a return on investment (ROI) curve tailored to their own environment.
Data Warehouse Benefits as Offsets
Instead of generic ROI percentages, benefits should be quantified as offsets to cost drivers:
- Productivity gains — fewer hours spent reconciling reports.
- Faster cycles — reduced delay between data availability and business action.
- Risk avoidance — fewer compliance penalties from inconsistent data.
- Opportunity impact — better forecasting accuracy, higher retention, or lower churn (industry-specific).
These offsets won’t fit into a universal ROI figure. They need to be estimated per organization and compared against the actual TCO.
Try a Modern Data Warehouse for Free
Run Exasol locally and test real workloads at full speed.
Practical Example: Helsana (Healthcare, Switzerland)
When Swiss health insurer Helsana migrated its analytics workloads to Exasol, it achieved three measurable outcomes (for real):
- 65% lower license and maintenance costs in the first year.
- 5–10× faster queries compared to the previous data warehouse.
- Migration completed within one year.
To illustrate what this means in practice, let’s create a hypothetical scenario:
If Helsana’s annual license and maintenance spend was $1 million (again, hypothetical baseline and scenario for illustration), a 65% reduction equals $650,000 saved in year one.
On the performance side, if analysts previously waited 30 minutes for large reports and now receive results in 3–6 minutes, that is a time saving of ~25 minutes per query. Across 200 analysts running one report daily, that equates to ~1,667 hours saved per week. Even at a conservative labor rate of $50/hour, that is an additional $83,000 in weekly productivity reclaimed, or more than $4 million annually.

This example combines direct cost savings with productivity gains to show how a data warehouse can deliver tangible business value. Actual results vary by workload, concurrency, and licensing, but the framework remains the same: quantify cost reductions, measure performance improvements, and translate the difference into financial impact.
Migration & Adoption Playbooks
Zero-Downtime Migration (CDC & Backfill)
Companies rarely have the option of taking core systems offline during migration. Change Data Capture (CDC) pipelines combined with a backfill process allow data warehouses to be populated in parallel while production systems continue running. Once synchronization is stable, workloads can be cut over with minimal disruption.
Schema Evolution & Drift Handling
As applications evolve, so do schemas. Without controls, mismatched field names, dropped attributes, or unexpected types can break pipelines. A robust data warehouse strategy includes schema evolution policies: version tracking, automated validation, and staging areas where changes are reconciled before reaching production. This prevents downstream analytics failures caused by “silent” schema drift.
Rollback & Testing Plans
No migration is risk-free. Companies reduce exposure by running parallel environments and defining rollback procedures before cutover. Testing plans typically include:
- Benchmarking query performance against the legacy system
- Validating row counts and aggregations for critical tables
- Stress testing concurrency at projected user loads
By treating migration as a phased process with rollback safeguards, companies avoid the costly scenario of a failed cutover.
Trade-offs and Disadvantages
Common Challenges
Adopting a data warehouse brings measurable benefits, but it also introduces costs and risks that need to be addressed:
- Vendor lock-in — long contracts or proprietary formats can limit flexibility.
- Concurrency spikes — high numbers of simultaneous queries can drive compute costs beyond budget.
- Governance overhead — consolidating data adds responsibility for access policies, audit trails, and regulatory reporting.
- Cold-start latency — data warehouses that suspend idle resources may add seconds of delay when users run their first query of the day.
Mitigation Strategies
Each of these challenges can be managed with deliberate planning:
- Reduce lock-in by asking for transparent pricing and negotiating exit clauses.
- Cap concurrency spend through workload management and query prioritization.
- Simplify governance with centralized policies, automated lineage tracking, and integration with existing identity systems.
- Limit latency impact by pre-warming clusters or using caching strategies for common queries.
Enterprise Data Warehouse Benefits
Why Enterprises Need More Than a Standard DW
Large organizations operate with thousands of users, petabytes of data, and strict regulatory obligations. A traditional data warehouse can handle basic consolidation and reporting, but scaling to enterprise needs requires additional capabilities. An enterprise data warehouse (EDW) provides:
- High concurrency support — sustaining hundreds or thousands of simultaneous queries without resource contention.
- Advanced workload management — isolating critical queries from exploratory analysis to keep service levels predictable.
- Stronger governance — integration with enterprise identity systems, audit logging, and fine-grained access policies.
- Regulatory compliance — alignment with data residency laws, GDPR, HIPAA, and industry-specific standards.
- Disaster recovery and resilience — multi-region deployments and replication for business continuity.
Try a Modern Data Warehouse for Free
Run Exasol locally and test real workloads at full speed.
Finance KPI Pack Example (Liquidity & Risk)
Financial institutions use data warehouses to meet regulatory reporting requirements and monitor liquidity risk. One of the most important measures is the Liquidity Coverage Ratio (LCR), ensuring that high-quality liquid assets (HQLA) cover projected net cash outflows over a 30-day horizon.
Key KPIs
- Liquidity Coverage Ratio (LCR) = HQLA / Net Cash Outflows (30d)
- Net Stable Funding Ratio (NSFR) = Available Stable Funding / Required Stable Funding (not included here, but commonly paired with LCR)
- Capital Adequacy (e.g., Tier 1 capital ratios — outside scope of this pack)
Example Schema (Simplified)
This schema illustrates how to store liquid assets and projected cashflows. Real implementations require more asset classes, regulatory adjustments, and detailed stress factors.
CREATE TABLE dim_reporting_period (
period_id INT PRIMARY KEY,
start_date DATE NOT NULL,
end_date DATE NOT NULL
);
CREATE TABLE fact_hqla (
hqla_id BIGINT PRIMARY KEY,
period_id INT NOT NULL REFERENCES dim_reporting_period(period_id),
asset_class VARCHAR(30) NOT NULL, -- e.g., Level1, Level2A, Level2B
market_value_usd NUMERIC(20,2) NOT NULL,
haircut_pct NUMERIC(5,2) NOT NULL -- Basel regulatory haircut
);
CREATE TABLE fact_cashflows (
cf_id BIGINT PRIMARY KEY,
period_id INT NOT NULL REFERENCES dim_reporting_period(period_id),
direction CHAR(3) NOT NULL CHECK (direction IN ('IN','OUT')),
tenor_days INT NOT NULL, -- settlement horizon
amount_usd NUMERIC(20,2) NOT NULL,
stress_factor NUMERIC(6,4) DEFAULT 1.0 -- scenario multiplier
);
KPI Query: Liquidity Coverage Ratio (LCR)
This query applies Basel rules: haircut HQLA values, cap inflows at 75% of outflows, divide adjusted HQLA by net outflows.
WITH hqla_adjusted AS (
SELECT
period_id,
SUM(market_value_usd * (1 - haircut_pct/100.0)) AS hqla_adjusted_usd
FROM fact_hqla
GROUP BY period_id
),
out_inflows AS (
SELECT
period_id,
SUM(CASE WHEN direction = 'OUT' AND tenor_days <= 30
THEN amount_usd * stress_factor ELSE 0 END) AS out_30d,
SUM(CASE WHEN direction = 'IN' AND tenor_days <= 30
THEN amount_usd * stress_factor ELSE 0 END) AS in_30d
FROM fact_cashflows
GROUP BY period_id
),
net_calc AS (
SELECT
period_id,
out_30d - LEAST(in_30d, 0.75 * out_30d) AS net_cash_outflows_30d
FROM out_inflows
)
SELECT
r.label,
h.hqla_adjusted_usd,
n.net_cash_outflows_30d,
CASE WHEN n.net_cash_outflows_30d > 0
THEN h.hqla_adjusted_usd / n.net_cash_outflows_30d
ELSE NULL END AS lcr_ratio
FROM hqla_adjusted h
JOIN net_calc n USING (period_id)
JOIN dim_reporting_period r USING (period_id)
ORDER BY r.start_date DESC;
Notes & Assumptions:
- HQLA classes and haircuts follow Basel III; refine asset types and multipliers per jurisdiction.
- Stress factors (e.g., outflow run-off rates, inflow assumptions) should be populated from risk models.
- Inflows capped at 75% of outflows — standard Basel rule.
- Partitioning: in production, partition tables by reporting period or snapshot date for performance.
Final Thoughts
A data warehouse delivers clear advantages — from consistent data and faster reporting to regulatory compliance and enterprise-scale performance. At the same time, adoption requires weighing costs, governance overhead, and migration risks.
The most successful enterprises treat warehousing not just as a reporting tool, but as an enabler of trustworthy, auditable decision-making. Benefits are maximized when return on investment is measured, migrations are staged carefully, and KPI frameworks are built into operations.
FAQs About Data Warehouse Benefits
A data warehouse centralizes information from multiple systems, creating a single source of truth. It improves consistency, accuracy, and decision-making speed by supporting historical analysis, compliance reporting, and enterprise-scale queries.
The major benefit is the ability to run complex, cross-functional analytics on consolidated data. Unlike transactional systems, warehouses are optimized for reporting, trend analysis, and forecasting at scale.
The primary purpose is to store and organize historical and current data for analytical use. It enables enterprises to track performance over time, support business intelligence, and meet compliance obligations.
Classic warehouse features include:
Subject orientation – data organized around business domains.
Integration – consolidation from multiple sources.
Time-variance – historical snapshots preserved for trend analysis.
Non-volatility – data is stable once loaded, ensuring consistent reporting.
A fully managed warehouse reduces operational overhead by automating scaling, patching, and backups. It allows teams to focus on analytics instead of infrastructure maintenance.
Advantages: high scalability, advanced governance, SLA-backed availability, and compliance support.
Disadvantages: higher licensing costs, potential complex migrations.
An enterprise data warehouse (EDW) provides a centralized, governed environment that serves all departments. It ensures consistency across finance, operations, and compliance by aligning data models to enterprise standards.
Pros: centralized data, faster queries, compliance readiness, long-term insights.
Cons: infrastructure cost and the need for migration planning.