
Database Design Principles and Best Practices

Database design principles are rule-based guidelines for structuring tables, keys, relationships, and constraints so data remains consistent, queryable, and maintainable under real workloads. They define how schemas should be modeled, validated, and evolved; independent of any specific database product.
This guide and principles apply to database design in general, with primary emphasis on relational systems. Where non-relational or distributed models follow different rules, those differences are noted explicitly. It covers integrity rules, normalization boundaries, key selection, constraint strategy, naming conventions, and workload-aware design decisions. These principles are consistent with standard relational database theory and normalization practice used across production database systems.
It does not provide a procedural build tutorial. For an implementation walkthrough, see the separate step-by-step database design guide.
Core Database Design Principles (Quick Reference List)
The following principles define the baseline quality criteria for relational database design. They are technology-agnostic and apply across transactional and analytical systems. Each principle acts as a constraint on schema decisions, not as a build step.
- Model entities and relationships explicitly
Represent real business objects as separate entities and define relationships with keys, not embedded values. - Keep data atomic at the column level
Store one fact per field. Avoid composite or multi-value columns that mix multiple attributes. - Normalize by default
Remove redundancy and dependency anomalies unless a measured workload requirement justifies denormalization. - Define keys and enforce integrity with constraints
Use primary keys, foreign keys, and domain constraints to prevent invalid states. - Design for query and workload patterns
Structure schemas around dominant access paths and aggregation needs. - Separate transactional and analytical models
Write-optimized and read-optimized schemas follow different structural rules and should not be forced into one pattern. - Use consistent naming conventions
Predictable table, column, and key names reduce ambiguity and migration risk. - Plan for schema evolution
Prefer additive, backward-compatible changes and explicit versioning over destructive refactors.
| Principle | What it prevents | What it enables |
|---|---|---|
| Entity & relationship clarity | Mixed entity tables, ambiguous records | Clear schema boundaries and reliable joins |
| Atomic columns (1NF) | Multi-value fields, parsing logic | Precise filtering and validation |
| Normalization by default | Redundancy and update anomalies | Consistent, dependency-safe data |
| Keys & constraints | Duplicate rows and orphan records | Enforced identity and referential integrity |
| Workload-aware design | Avoidable join and access inefficiencies | Query patterns aligned with schema structure |
| Transactional vs analytical separation | Conflicting write/read optimizations | Fit-for-purpose schema structures |
| Naming conventions | Schema ambiguity and query errors | Readable, maintainable models |
| Schema evolution planning | Uncontrolled breaking changes | Safer, staged schema updates |
These principles are expanded below with decision criteria, tradeoffs, and anti-patterns.

Test Real Analytical Workloads with Exasol Personal
Unlimited data. Full analytics performance.
Principle 1: Entity and Relationship Clarity
A database schema should represent real-world business objects and their relationships as separate, well-defined structures. Each entity must have a clear purpose, stable identity, and unambiguous boundaries. Relationship rules should be expressed through keys and constraints, not inferred from embedded values or duplicated attributes.
Entity design rules
- Model one entity per table based on business meaning, not UI screens or reports.
- Each entity should answer a single question: what type of thing does this row represent?
- Avoid multi-purpose tables that mix unrelated concepts under optional columns.
- Split entities when lifecycle, ownership, or update patterns differ.
Relationship design rules
- Represent relationships with foreign keys, not text references or repeated attributes.
- Define cardinality explicitly (one-to-one, one-to-many, many-to-many).
- Resolve many-to-many relationships with junction tables, not array or list fields.
- Make relationship optionality explicit through NULL vs NOT NULL foreign keys.
Boundary test for entity separation
Create a separate table when at least one of the following is true:
- The attributes change at a different frequency than the parent record.
- The data can exist independently.
- The relationship count can exceed one.
- Different access controls apply.
- Different retention rules apply.
Common anti-patterns
- Storing multiple entity types in one table with a “type” column and many nullable fields.
- Embedding child records as comma-separated values or JSON blobs in relational columns.
- Copying lookup attributes instead of referencing them.
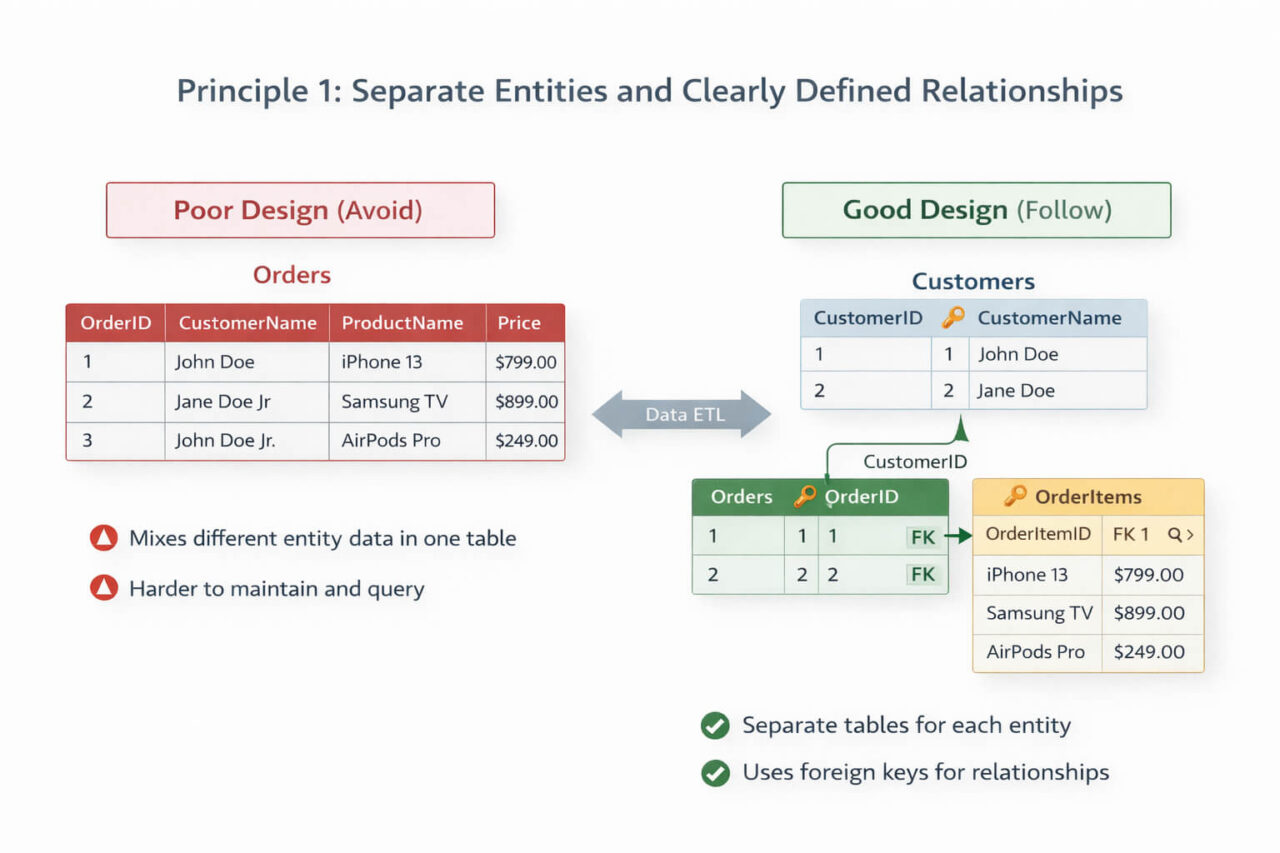
A minimal normalized transactional schema separates customers, orders, and line items into distinct tables linked by foreign keys:
Customers
- CustomerID (PK)
- Name
Orders
- OrderID (PK)
- CustomerID (FK)
- OrderDate
OrderItems
- OrderItemID (PK)
- OrderID (FK)
- ProductID (FK)
- Quantity
Each table stores one entity type, and relationships are enforced through foreign keys rather than repeated attributes.
Model note (non-relational systems)
Document and key-based relationship clarity still applies in non-relational databases, but enforcement may shift from foreign key constraints to application or model-layer validation.
Principle 2: Atomic Data and Column Design
Each column should store a single, indivisible fact about the entity it belongs to. Columns should be atomic (meaning they contain no nested or multi-valued fields), a requirement formally defined as first normal form (1NF). Queries, constraints, and joins depend on predictable column meaning and consistent value structure.
Atomicity rules
- Store one value per field, not compound values.
- Do not combine multiple attributes into one column.
- Avoid delimiter-based lists inside a single field.
- Prefer typed columns over encoded strings.
Examples
Non-atomic:
- full_name storing first and last name together
- address storing street, city, and postal code in one field
- product_ids storing comma-separated identifiers
Atomic:
- first_name, last_name
- street, city, postal_code
- junction table for product relationships
Why atomic design matters
- Enables precise filtering and indexing
- Supports constraint enforcement per attribute
- Prevents partial-update errors
- Improves join reliability
- Reduces parsing logic in queries
Composite data exceptions
Composite storage can be acceptable when:
- The value is never queried by sub-parts
- The value is always consumed as a whole
- No validation is required on internal components
- The field is treated as opaque payload
Typical examples include hashes, signatures, or externally defined IDs.
Typed column principle
- Use the most specific data type available.
- Avoid storing numeric, date, or boolean values as text.
- Enforce domain ranges where supported.
Analytics note
Atomic columns improve aggregation accuracy and feature extraction in analytical workloads. Denormalized analytical tables may duplicate values across rows, but each column should still remain atomic.
Test Real Analytical Workloads with Exasol Personal
Unlimited data. Full analytics performance.
Principle 3: Normalization (and When to Break It)
Normalization organizes data into related tables to eliminate redundancy and dependency anomalies. A normalized schema reduces update errors, improves consistency, and makes constraints enforceable. For transactional systems, normalization is the default design posture.
Normalization is not an absolute rule. It is a bias toward integrity that can be relaxed when measured workload requirements justify controlled redundancy.
A complementary theoretical rule within relational schema design is the Principle of Orthogonal Design in relational schema theory, which states that relations should not represent the same facts redundantly.
Why normalization exists
Normalization prevents three common failure modes:
- Update anomalies: the same fact must be changed in multiple places
- Insert anomalies: new facts cannot be stored without unrelated data
- Delete anomalies: removing one record unintentionally removes another fact
A normalized model stores each fact once and references it by key.
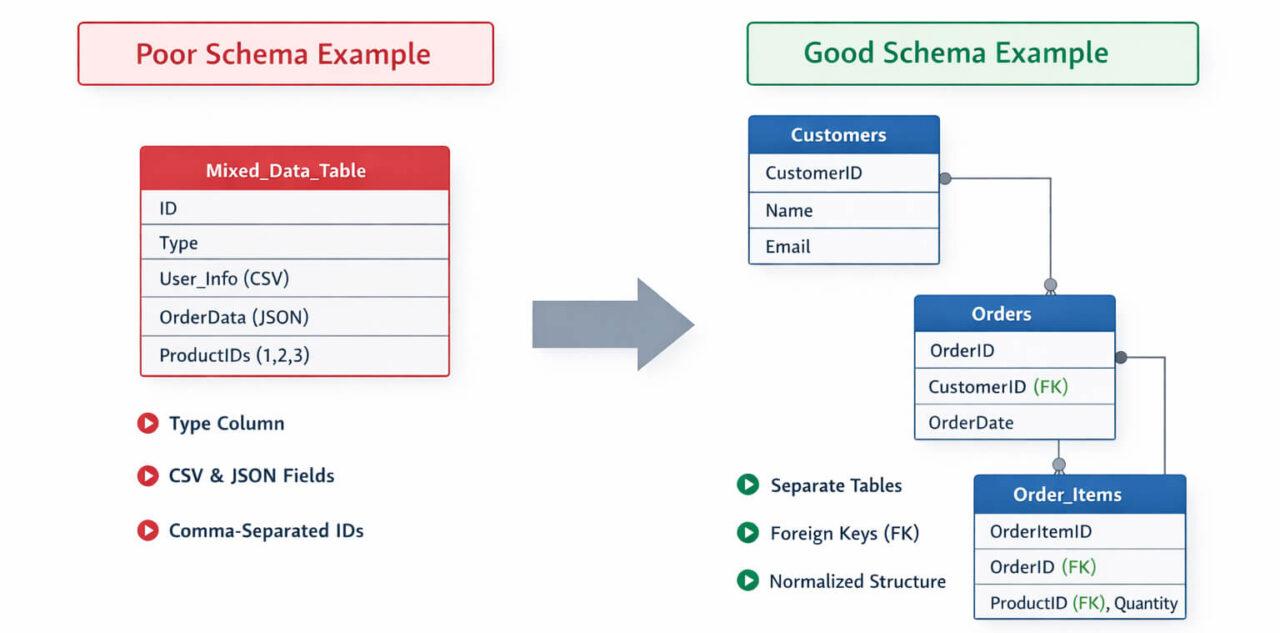
Left: multiple entity types and multi-value fields stored in one table. Right: normalized relational structure using separate tables and foreign keys. JSON or nested fields can be valid in document or staging layers, but violate atomicity rules in normalized OLTP schemas.
Practical normalization levels (working set)
Full academic normal forms are rarely applied exhaustively in production design. In practice, most stable schemas satisfy these levels:
First Normal Form (1NF)
- One value per field
- No repeating groups
- No array-like columns
Second Normal Form (2NF)
- Non-key attributes depend on the whole key
- No partial dependency on part of a composite key
Third Normal Form (3NF)
- Non-key attributes depend only on the key
- No transitive dependencies between non-key columns
BCNF (selective use)
- Every determinant is a candidate key
- Applied where dependency ambiguity creates risk
Design to 3NF by default. Apply BCNF when dependency conflicts are observable, not theoretical.
When denormalization is justified
Denormalization introduces controlled redundancy to reduce join cost or simplify access paths. It is justified only when query workload and performance constraints are known.
Valid denormalization conditions:
- Dominant queries require repeated multi-table joins
- Read volume greatly exceeds write volume
- Aggregations are stable and frequently reused
- Data duplication risk is bounded and monitored
- Refresh or rebuild processes are defined
Common acceptable denormalizations:
- Precomputed aggregates
- Dimension attribute duplication in fact tables
- Materialized summary tables
Transactional vs analytical models
Normalization strategy depends on workload type:
Transactional (OLTP) systems
- Favor higher normalization
- Optimize for write correctness
- Enforce strict constraints
- Minimize redundancy
Analytical (OLAP / warehouse / lakehouse) systems
- Allow selective denormalization
- Optimize for scan and aggregation
- Use star or wide-table patterns where justified
- Accept duplication in exchange for query speed
Do not force one normalization strategy across both workloads.
Denormalization risk controls
When denormalizing, add safeguards:
- Document duplicated fields
- Define refresh ownership
- Add validation queries
- Monitor divergence risk
- Prefer derived tables over manual duplication
Denormalization without governance converts performance optimization into integrity risk.
Principle 4: Keys, Constraints, and Integrity Rules
Keys and constraints define identity and validity at the database level. They prevent duplicate records, broken relationships, and invalid values before queries run. Integrity rules should be enforced by the schema wherever the database engine supports it, not left solely to application logic.
A schema without enforced keys and constraints is structurally incomplete.
Primary key design rules
Every table should have a primary key that uniquely and permanently identifies each row.
Primary keys should be:
- Unique: no duplicates across the table
- Non-null: always present
- Stable: value does not change over time
- Minimal: smallest column set that guarantees uniqueness
Avoid primary keys that depend on business attributes that can change, such as email addresses, usernames, or external codes.
Prefer:
- Surrogate keys for mutable domains
- Natural keys only when guaranteed stable and governed
Surrogate vs natural keys (decision criteria)
Use surrogate keys when:
- Business identifiers can change
- Multiple candidate identifiers exist
- Values are long or composite
- Keys are reused across systems
- Privacy rules restrict exposure
Use natural keys when:
- The identifier is globally stable
- It is already constrained and validated
- It is short and immutable
- It has business meaning required in joins
Mixed strategy is valid: surrogate primary key + natural key with UNIQUE constraint.
Foreign keys and referential integrity
Foreign keys enforce valid relationships between tables. They prevent orphan records and ensure referenced rows exist.
Rules:
- Define foreign keys for all persistent relationships
- Match data types exactly between parent and child keys
- Index foreign key columns in high-join tables
- Make optional relationships explicit with NULL allowance
Avoid storing reference IDs without a declared foreign key constraint when the engine supports enforcement.
Constraint enforcement principles
Use constraints to block invalid states at write time.
Apply where applicable:
- NOT NULL: required attributes
- UNIQUE: alternate identifiers
- CHECK: domain rules and value ranges
- DEFAULT: controlled fallback values
Constraint logic should be deterministic and side-effect free.
Do not encode domain rules only in application code when they can be enforced by the database.
Cascading action rules
Cascading updates and deletes must be deliberate, not default.
Use cascading deletes only when:
- Child records have no independent meaning
- Deletion is always logically coupled
- Recovery strategy exists
Avoid cascading deletes when:
- Child data has audit or historical value
- Relationships are optional
- Regulatory retention applies
Prefer explicit delete logic over broad cascades in shared domains.
Integrity validation checklist
Minimum integrity baseline for production tables:
- Primary key defined
- Foreign keys defined where relationships exist
- NOT NULL on required fields
- UNIQUE on alternate identifiers
- Domain constraints where ranges are known
Schemas that meet these rules fail earlier and debug faster.
Test Real Analytical Workloads with Exasol Personal
Unlimited data. Full analytics performance.
Principle 5: Design for Query and Workload Patterns
Schema design should reflect how data is actually accessed, filtered, joined, and aggregated. A structurally correct model that ignores workload patterns will pass integrity checks but fail performance and usability expectations. Query behavior is a first-class design input, not a later optimization step.
Design decisions should be validated against dominant query shapes, not hypothetical flexibility.
Start from access patterns, not only data structure
Entity modeling defines what data exists. Workload modeling defines how it is used.
Capture and classify:
- Most frequent queries
- Join paths
- Filter columns
- Aggregation dimensions
- Sort patterns
- Update frequency
Schemas should make common queries simple and rare queries possible, not the reverse.
Join depth and table shape tradeoffs
Highly normalized schemas increase join depth. That improves integrity but raises query complexity and cost.
Use these rules:
- Keep frequently joined attributes close when read patterns are stable
- Avoid deep join chains in high-frequency queries
- Prefer reference tables over duplicated text attributes
- Introduce derived or summary tables for repeated multi-join reports
Join count is not a fixed limit, but repeated multi-join patterns should trigger review.
Index design is workload-driven
Indexes exist to support query patterns, not schema symmetry.
Index candidate columns include:
- Frequent filters
- Join keys
- Group-by dimensions
- Sort keys
- High-selectivity attributes
Avoid:
- Indexing every foreign key without query evidence
- Over-indexing write-heavy tables
- Duplicate indexes with reordered columns and identical prefixes
Composite indexes should follow query predicate order.
Read-heavy vs write-heavy bias
Schema and index strategy should reflect workload bias.
Read-heavy workloads
- More secondary indexes acceptable
- Derived tables acceptable
- Controlled denormalization acceptable
- Wider tables acceptable
Write-heavy workloads
- Fewer indexes preferred
- Higher normalization preferred
- Derived data minimized
- Constraint checks kept efficient
Do not optimize both extremes in the same table design.
Aggregation and analytical query patterns
Analytical queries favor:
- Stable dimensions
- Repeatable grouping keys
- Predefined aggregation paths
- Time-based partitioning
Design implications:
- Separate fact and dimension roles
- Keep dimension keys stable
- Avoid recalculating the same aggregates repeatedly
- Use materialized summaries where refresh logic is defined
This is a structural principle, not a reporting convenience.
Validation rule
A schema design is workload-aligned when:
- Top queries are simple to express
- Critical joins are indexed
- Aggregations do not require repeated restructuring
- Query plans remain stable under expected scale
If common queries require complex rewrites or repeated workarounds, the schema shape is misaligned with workload.
Principle 6: Separate Transactional and Analytical Models
Transactional and analytical systems follow different design priorities and should not share the same schema patterns by default. Understanding how databases differ from data warehouses clarifies when to separate models.
Transactional models optimize for correctness and write consistency. They favor higher normalization, strict constraints, and minimal redundancy. The goal is to make inserts and updates safe and unambiguous.
Analytical models optimize for read efficiency and aggregation. They allow selective denormalization, wider tables, and duplicated dimension attributes where this reduces join cost and stabilizes query performance.
A single schema rarely serves both workloads well. When the same data supports both operations and analytics, use separate logical models or derived layers rather than forcing one structure to satisfy conflicting requirements.
In distributed or hybrid data environments, schema abstraction layers like virtual schemas can enable flexible access to structured and semi-structured data without physically centralizing it.
Design decision rule: if write integrity and read efficiency pull the structure in opposite directions, split the model.
Principle 7: Naming and Schema Conventions
Naming conventions are structural controls, not stylistic preferences. Consistent object names make schemas easier to query, review, migrate, and audit. Inconsistent naming increases error rates in joins, filters, and schema changes.
Every schema should follow one documented naming standard that applies to tables, columns, keys, indexes, and constraints.
Table names should reflect the entity they store and remain stable over time. Use clear nouns with one meaning per table. Avoid overloaded names, UI-driven labels, and unexplained abbreviations. A reader should understand the table’s purpose without external context.
Column names should describe the stored attribute, not its presentation label. Use consistent suffix patterns for common fields such as identifiers and timestamps. The same attribute should use the same name everywhere it appears. Unit meaning should be explicit where relevant.
Key and constraint names should follow predictable patterns so they are recognizable in logs and migration scripts. Primary keys, foreign keys, unique constraints, and checks should be distinguishable by prefix. Auto-generated constraint names are acceptable for prototypes but not for long-lived production schemas.
Index names should identify both the table and indexed columns. This allows fast verification of coverage when reviewing execution plans or tuning queries.
If a name requires explanation, it is poorly chosen. Good schema names are self-describing and repeatable across teams.
Principle 8: Plan for Schema Evolution
Database schemas change over time. New attributes are added, relationships are refined, and constraints are tightened. A stable design anticipates change and reduces the risk of breaking queries, pipelines, and applications when the schema evolves.
Schema evolution should follow backward-compatible patterns by default. Additive changes are safer than destructive ones. Adding columns, tables, or constraints with safe defaults is preferred over renaming or removing existing structures in place.
Destructive changes — such as column drops, type changes, or key rewrites — should be staged. Use deprecation periods, compatibility views, or parallel columns so dependent queries can migrate gradually. Direct in-place changes create avoidable outage risk.
Version awareness should exist at the schema level, not only in application code. Migration scripts must be repeatable, ordered, and reversible where possible. Each structural change should have an explicit reason and rollback path.
Derived and analytical layers should be treated as rebuildable. Base transactional structures should be treated as durable. This separation limits the blast radius of change.
Design rule: if a schema change would silently change query meaning, it must be introduced through a compatibility layer, not a direct replacement.
Test Real Analytical Workloads with Exasol Personal
Unlimited data. Full analytics performance.
Common Database Design Anti-Patterns
Design failures are usually structural, not syntactic. The following anti-patterns appear frequently in production schemas and lead to integrity issues, query complexity, and migration risk. Each one violates one or more core design principles defined above.
Mixing Multiple Entity Types in One Table
A single table stores different entity types distinguished by a “type” column and many nullable fields.
Why it fails:
- Constraints cannot be enforced consistently
- Most columns are conditionally valid
- Indexing becomes inefficient
- Query logic becomes branch-heavy
Preferred pattern: separate tables per entity with explicit relationships.
Multi-Value Fields in Relational Columns
Multiple values are stored in one column using delimiters, arrays, or encoded text.
Why it fails:
- Breaks atomicity
- Prevents correct indexing
- Makes filtering and joins unreliable
- Requires parsing in every query
Preferred pattern: child table or junction table.
Missing Foreign Keys for Real Relationships
Reference IDs are stored without foreign key constraints.
Why it fails:
- Orphan records accumulate
- Integrity depends on application behavior
- Data quality cannot be enforced centrally
Preferred pattern: declare foreign keys wherever the engine supports them.
Natural Keys That Change
Business attributes (email, username, external code) are used as primary keys even though they can change.
Why it fails:
- Key updates cascade across relationships
- History becomes inconsistent
- Migrations become high risk
Preferred pattern: surrogate primary key + unique natural key constraint.
Over-Denormalization Without Workload Evidence
Redundant attributes are duplicated across tables without measured query need.
Why it fails:
- Update anomalies increase
- Data drift risk grows
- Validation cost shifts to queries
Preferred pattern: normalize first, denormalize only with measured query justification.
Encoded Meaning Inside Column Values
Status, type, or category meaning is encoded inside free-form text or composite codes.
Why it fails:
- Domain rules cannot be constrained
- Queries depend on string parsing
- Semantics are not machine-verifiable
Preferred pattern: lookup tables with constrained keys.
Schema Coupled to UI or Reports
Tables and columns are shaped around screens or reports instead of domain entities.
Why it fails:
- Model becomes unstable when UI changes
- Reuse across use cases is limited
- Redesign frequency increases
Preferred pattern: domain model first, presentation layer second.
Constraint-Free Optionality Everywhere
Most columns allow NULL without semantic justification.
Why it fails:
- Required data is not enforced
- Query filters become ambiguous
- Downstream assumptions break
Preferred pattern: require NOT NULL where the attribute is logically mandatory.
Database Design Principles: Review Checklist
Use this checklist to review an existing schema or validate a new design before production use. Each item should be answerable with yes/no based on the schema itself, not application behavior.
Structure and Modeling
- Each table represents exactly one entity type
- Entity purpose is clear from the table name
- Many-to-many relationships are resolved with junction tables
- No tables mix multiple entity types with a type flag
- Relationship cardinality is explicitly modeled
Column Design and Atomicity
- Each column stores a single value only
- No comma-separated or encoded value lists exist
- Composite attributes are split into separate columns
- Data types match the stored value domain
- Units and formats are explicit where relevant
Keys and Integrity
- Every table has a primary key
- Primary keys are stable and non-null
- Natural identifiers that can change are not primary keys
- Foreign keys are declared for real relationships
- Foreign key data types match parent keys exactly
Constraints and Validation
- NOT NULL is applied to required attributes
- UNIQUE constraints protect alternate identifiers
- Domain rules are enforced with CHECK constraints where possible
- Defaults are defined only where logically valid
- Integrity does not rely only on application code
Normalization and Redundancy
- Redundant attributes are minimized
- Lookup values are stored in reference tables
- Denormalized fields are documented and justified
- Derived values are not stored without refresh logic
- Update anomalies cannot occur by design
Workload Alignment
- Frequent filter columns are indexed
- Join keys are indexed where query volume is high
- Dominant queries are simple to express
- Repeated heavy joins are reviewed for redesign
- Aggregation paths are structurally supported
Naming and Conventions
- Table names follow one consistent pattern
- Column names are descriptive and unambiguous
- Key and constraint names follow a standard prefix pattern
- Index names identify table and columns
- Reserved keywords are not used as object names
Evolution and Change Safety
- Additive schema changes are preferred
- Destructive changes are staged or versioned
- Migration scripts are ordered and repeatable
- Deprecated columns are phased out, not removed immediately
- Schema changes have rollback paths
Test Real Analytical Workloads with Exasol Personal
Unlimited data. Full analytics performance.
FAQs
Relational database design is the process of structuring data into tables, keys, and relationships so it can be stored and queried consistently. It defines entities, attributes, and foreign-key relationships, and applies normalization and constraints to prevent redundancy and integrity errors. The result is a schema where data dependencies are explicit and enforceable.
Database design principles are rules that guide how tables, columns, keys, and relationships are structured. Core principles include entity clarity, atomic columns, normalization, primary and foreign key enforcement, constraint-based validation, workload-aware modeling, consistent naming, and change-safe schema evolution. These principles reduce anomalies and improve long-term maintainability.
The golden rule of database design is to store each fact once and reference it by key. This minimizes redundancy and prevents update anomalies. In practice, this means normalizing transactional data, enforcing keys and constraints, and avoiding duplicated attributes unless a measured workload requirement justifies denormalization.
A relational database model is designed by defining entities, attributes, keys, and relationships based on business data requirements, then validating the structure against normalization and integrity rules. Query patterns and workload type should influence indexing and selective denormalization decisions. Detailed build steps belong in a procedural design tutorial, not in principles guidance.
Database design is commonly divided into requirement analysis, conceptual modeling, logical modeling, normalization, physical design, indexing and optimization, and validation. These phases describe a workflow for building schemas. They complement design principles, which define the structural rules the schema should satisfy.
Typical steps include defining requirements, identifying entities, defining attributes, assigning keys, modeling relationships, applying normalization, and validating against queries. These steps describe execution order. Design principles, by contrast, describe the quality rules the final schema must meet.
Four widely accepted guidelines are: model entities clearly, keep columns atomic, enforce keys and constraints, and normalize by default. Additional guidelines include workload-aware indexing and consistent naming. Together, these rules reduce redundancy, ambiguity, and integrity risk.
Common baseline rules are: every table has a primary key, each field is atomic, relationships use foreign keys, and constraints enforce valid values. These rules ensure identity, consistency, and referential integrity at the schema level.
The five core components are tables (data storage), columns (attributes), keys (identity), relationships (links between tables), and constraints (validity rules). Together they define structure, identity, and integrity in relational systems.
The four basic database operations are create, read, update, and delete (CRUD). They describe how data is written and retrieved. Schema design principles ensure these operations remain safe and consistent as data volume and query complexity grow.