Converting Human Language into SQL Statements

While working on AI-related topics with Exasol, I found an article from Aymeric Roucher about translating human language into SQL statements based on a Large Language Model (LLM) on the well-known Huggingface website, credits to his work. Firstly, I had to try it out immediately and adapt it to work with the Exasol database. It should be able to generate SQL statements spanning more than one schema. I tested it with various human-formulated questions and inspected the verbose log while translating it into SQL statements.
It showed me what is possible with an LLM and just a few lines of code. However, this is not ready for a production environment, but it is very impressive. The quality depends on the selected language model and how you formulate the question in natural language. Also, remember that utilizing an LLM has certain advantages and disadvantages, which I will discuss later in the article.
I use Exasol’s AI-Lab here for easy use to create my demo code. Secondly, and this is good to know for those who do not have an Exasol database up and running – AI-Lab comes with an integrated Exasol Docker-based database, which is suitable for data up to 10 GBytes. The Exasol AI-Lab and installation instructions for the Docker deployment I am using can be found here:
Before you start, please keep in mind that agents based on a Large Language Model can alter their output from execution to execution when providing them with identical tasks, in our case this may result in different, but in most times valid, SQL statements for the same question.
Additionally, you will require a token from Huggingface for the agent to log in to use the desired LLM.
from huggingface import login, InferenceClient
login(„<Your Huggingface token>“)First, we need the metadata describing the database schema structure. In my case, I am using a simple schema with RETAIL content spread over to two schemas to show multi-schema queries – as shown below:
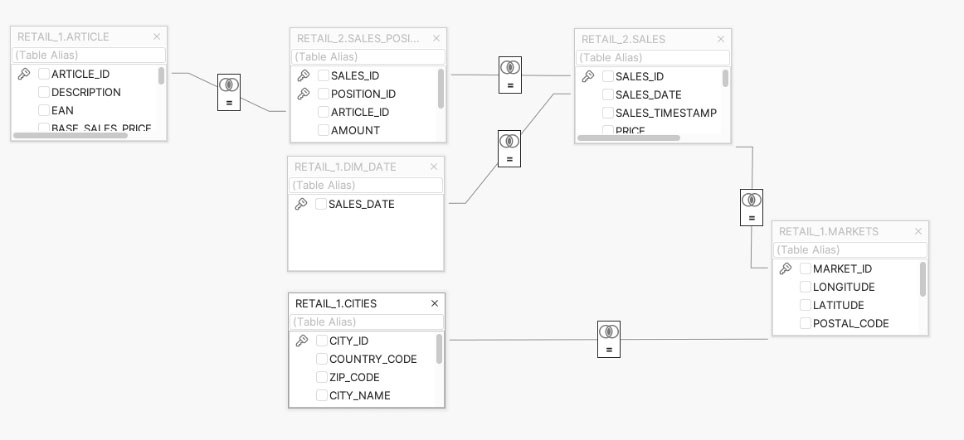
The first step is retrieving the metadata for my schemas from Exasol; luckily, this just requires a query to an Exasol system table and some output formatting. The output of this code will be used for the implicit prompt enrichment when presenting the human-formulated question to the agent.
import pyexasol
VERBOSE = True
dsn = ai_lab_config.db_host_name + ":" + ai_lab_config.db_port
C = pyexasol.connect(dsn=dsn,user=ai_lab_config.db_user, password=ai_lab_config.db_password,
schema=CONNECTING_SCHEMA)
stmt = C.execute(f"""
SELECT COLUMN_SCHEMA,
COLUMN_TABLE,
COLUMN_NAME,
COLUMN_TYPE
FROM SYS.EXA_ALL_COLUMNS
WHERE COLUMN_SCHEMA IN {WORKING_SCHEMAS}
ORDER BY COLUMN_SCHEMA ASC, COLUMN_TABLE ASC
""")
table_description = ""
table, old_table = "", ""
for row in stmt:
schema = row[0]
table = row[1]
if table != old_table:
table_description += f"\n Table '{schema}.{table}': \n Columns: \n"
table_description += "\t - " + row[2] + ": " + row[3] + "\n"
old_table = table
if VERBOSE:
print(table_description)You need to adapt your connection settings if you are not using the Exasol AI-Lab.
Notably, a precise schema design with a good naming convention is critical for the agent to deliver reasonable results. This is especially valid when you ask questions that imply table joins on the database. Below, you can see an excerpt of the retrieved metadata for one table:
Table 'RETAIL_1.ARTICLE':
Columns:
- ARTICLE_ID: DECIMAL(9,0)
- DESCRIPTION: VARCHAR(100) UTF8
- EAN: DECIMAL(18,0)
- BASE_SALES_PRICE: DECIMAL(9,2)
- PURCHASE_PRICE: DECIMAL(9,2)
- PRODUCT_GROUP: DECIMAL(9,0)
- PRODUCT_CLASS: DECIMAL(9,0)
- QUANTITY_UNIT: VARCHAR(100) UTF8
- TMP_OLD_NR: DECIMAL(9,0)
- PRODUCT_GROUP_DESC: VARCHAR(100) UTF8
- DISTRIBUTION_COST: DECIMAL(9,2)The second part is the agent, part of the so-called transformers package; we only need a few lines of code to define it. The first step is to define a so-called tool, which accepts a query created by the agent and executes it against the database:
from transformers.agents import tool
import pandas as df
@tool
def sql_engine(query: str) -> str:
"""
Here go the table descriptions, will be updated at a later step
with the table descriptions from the desired database schema(s)
Args:
query: The query to perform as a SQL statement
"""
output = ""
dsn = ai_lab_config.db_host_name + ":" + ai_lab_config.db_port
C = pyexasol.connect(dsn=dsn, user=ai_lab_config.db_user, password=ai_lab_config.db_password, schema=CONNECTING_SCHEMA)
df = C.export_to_pandas(query)
C.close()
print(query)
return dfThe descriptive block of the Python function is the location where the schema metadata will be added dynamically later. Interestingly, returning a Pandas Data Frame, in contrast to the original code, has a significant positive impact on the agent when it comes to formatting the output.
Next, you specify the Large Language Model (LLM) to use. This can be a publicly available or an LLM you are hosting on your premises. I am just using the repository name of the desired LLM on Huggingface, and the agent does the rest – utilizing the „HfApiEngine“ module:
from transformers.agents import ReactCodeAgent, HfApiEngine
agent = ReactCodeAgent(
tools = [sql_engine],
llm_engine = HfApiEngine("Qwen/Qwen2.5-72B-Instruct"),
)As a final step, we have to update the tool’s metadata, the content will finally become part of the so-called prompt engineering:
description_intro = "On database, it allows to execute SQL queries on tables listed below: \n\n"
description_outro = """Args:
query (str): The query to perform as a SQL statement \n
"""
sql_engine.description = description_intro + table_description + description_outroWe are done; only a few lines of code are needed for the agent to translate human language into SQL statements. We are now able to check how well the agent is performing. Starting with a simple question by executing the following line:
>> agent.run(“How many distinct transactions do we have?“)To answer this question, only one table is required. The question will be translated into the following SQL statement based on the metadata we have extracted from the Exasol database:
SELECT
COUNT(DISTINCT SALES_ID) AS DISTINCT_TRANSACTIONS
FROM
RETAIL_2.SALESAnd you guessed it, the agent delivered a correct SQL statement and, therefore, an accurate result. Let’s check how the agent handles a more complex question requiring database table joins.
“Show me the performance with regards to price and units sold of the product group descriptions for Alcohol drinks with similar names per area, order by area ascending?”Again, we pass this question to the agent and check the generated SQL statement:
SELECT
m.AREA,
a.PRODUCT_GROUP_DESC,
SUM(sp.AMOUNT)AS UNITS_SOLD,
SUM(sp.PRICE * sp.AMOUNT) AS TOTAL_REVENUE
FROM
RETAIL_2.SALES_POSITIONS sp
JOIN
RETAIL_1.ARTICLE a ON sp.ARTICLE_ID = a.ARTICLE_ID
JOIN
RETAIL_2.SALES s ON sp.SALES_ID = s.SALES_ID
JOIN
RETAIL_1.MARKETS m ON s.MARKET_ID = m.MARKET_ID
WHERE
a.PRODUCT_GROUP LIKE ‘%Alcohol%‘
GROUP BY
m.AREA, a.PRODUCT_GROUP
ORDER BY
m.AREA ASCWow, the question presented to the agent was translated into an SQL statement with three table joins. The ask for similarity was translated correctly in the WHERE clause, and the agent correctly translated the phrase performance into a multiplication of price and sold units of the articles regarding revenue. Of course, the question leaves enough room for speculation or discussion of what performance means. However, this is a well-known problem in BI.
I leave it up to you to challenge this agent any further and find an even better-performing Large Language Model. However, there are also some findings where the agent did not perform well or failed to produce a result.
For another question, the agent generated an SQL statement where a database function name was used as a column alias, which is not allowed in the Exasol database. But you can aid the agent here by telling him to use a different name for the alias, e.g.:
“ <your question...>, use ‚YEAR_OF_REVENUE’ as alias name for YEAR……”or precise the question, e.g. from:
“Show me the revenue per year?”to
“Show me the annual revenue per year?”Again, that is impressive!
Also, the agent tried to use pure alias names in a GROUP BY section, which failed on some tests because Exasol requires here the alias to be prepended with the local. keyword. Interestingly, on some tests, the agent discovered the problem and used the expression of the selection list instead of the alias in the GROUP BY section and successfully delivered a valid SQL statement, which let me conclude that the LLM is not working fully deterministic.
A final test demonstrates how tolerant the agent is to typos or misspellings:
>> The tob perfoming cytys label for units sold by region?Some typos or wrong spellings combined with an attribute name not included in the schema, here the attribute region, which exist as an attribute named area. A good test of how well the LLM can abstract the input. The agent created the following SQL statement, which returns the correct result but has yet to be inspected for possible improvement or simplification. Additionally, it was using Common Table Expressions (CTE) for the first time during my tests:
WITH SalesData AS (
SELECT
s.SALES_DATE,
sp.ARTICLE_ID,
sp.AMOUNT AS UNITS_SOLD,
m.CITY,
m.AREA
FROM
RETAIL_2.SALES s
JOIN
RETAIL_2.SALES_POSITIONS sp ON s.SALES_ID = sp.SALES_ID
JOIN
RETAIL_1.MARKETS m ON s.MARKET_ID = m.MARKET_ID
),
CitySales AS (
SELECT
CITY,
AREA,
SUM(UNITS_SOLD) AS TOTAL_UNITS_SOLD
FROM
SalesData
GROUP BY
CITY, AREA
),
RankedCitySales AS (
SELECT
CITY,
AREA,
TOTAL_UNITS_SOLD,
RANK() OVER (PARTITION BY AREA ORDER BY TOTAL_UNITS_SOLD DESC) AS RANK
FROM
CitySales
)
SELECT
CITY,
AREA,
TOTAL_UNITS_SOLD
FROM
RankedCitySales
WHERE
RANK = 1
ORDER BY
AREA, TOTAL_UNITS_SOLD DESCAgain, the agent performed well and created an even more complex SQL statement, being able to abstract from typos, misspellings, and similar but not identical attribute names.
You have seen that an agent, combined with an LLM, can translate human questions into correct SQL statements. But this impressive integration is not without cost. The LLM I am using here has 72 billion so-called parameters, or in other words, connection weights between the neurons of the LLM model. That is a lot and too heavy for many machines to use. Deploying such a heavy LLM into a database could be too much if your database does not support GPUs or does not have GPUs deployed in the database environment. Therefore, in most cases, the inference of the LLM tends to happen outside of the database, either to an external service like Huggingface or through an on-premises GPU server. You may want to experiment with smaller LLMs, but the build quality of the SQL statements could decrease.
Possible next steps are to embed the code into a so-called User-Defined Function (UDF), which still inferences a remote-located LLM but run directly on the database. Another next step would be extending the metadata by phrases, which helps the agent understand how suitable SQL statements for Exasol are to be created.
One final note: This code in this blog is not ready for a production environment; it is intended to be inspiration. The agent is not guaranteed always to return the correct SQL code. Therefore, use it at your own risk!
Happy Experimenting and, more importantly, Happy Exasoling!