
Blog snapshot:
This post will:
- Give you an introduction to the Delta Lake storage format
- Detail the problems the storage layer solves
- Demonstrate how Delta Lake works
Delta Lake is an open-source storage layer that introduces ACID transactions, history in form of commit logs and other features to Apache Spark and other Loading...big data workloads. It allows you to access your dataset consistently at all times stored on fast, cost efficient and highly scalable object storages. Let’s take a look at how this could apply to you.
What problem does the Delta Lake format address?
Apache Spark is a distributed computing engine. That is, it does not come with a storage system. Instead it usually relies on the other storage systems such as Amazon S3, Google Cloud Storage or Azure Blob Storage. However, all these storage systems are non-transactional file systems. Similarly, Spark itself does not provide any transactional guarantees.
Spark can save the data in several SaveMode modes. Unfortunately, none of these save modes use any locking and they are not atomic. When performing an Overwrite operation, Spark deletes the data before writing out the new data.
However, this breaks consistency of your dataset if Spark fails in between. Because public cloud storage systems can only guarantee consistency of a single file, and Spark itself does not offer consistent operations on the dataset, Delta Lake tracks the state change of your dataset and allows consistent access to it.
In order to better understand why the Delta Lake storage format is necessary, let’s first recap how Apache Spark works.
How Apache Spark works with Amazon S3
In regular execution, Spark writes data in two separate steps.
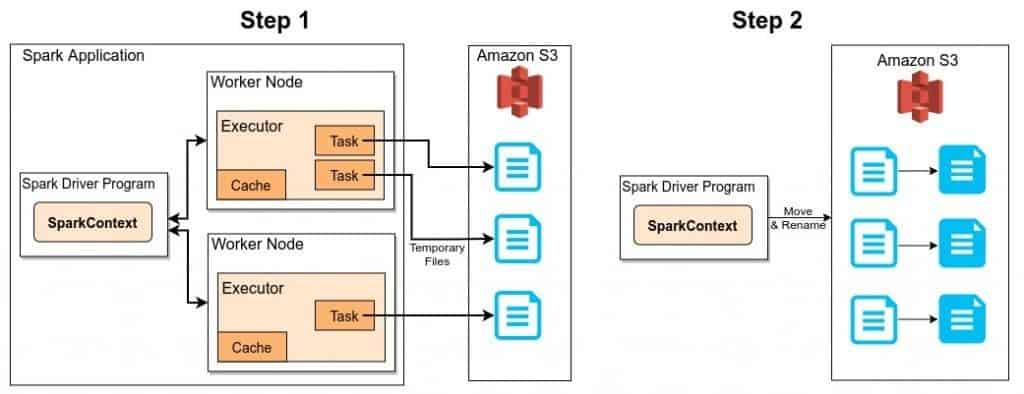
The example above shows how Apache Spark stores the data in an Amazon S3 bucket in two steps:
- The Spark task processes write the partitions allocated to them to a temporary path on S3. Then they report either success or failure to the driver.
- Assuming all tasks reported success, the driver then sequentially executes a mv (move) operation for each of the temporary files to their final path.
Issues with Blob Storage Systems
Due to the design principles of blob storage systems, the two step process of the Spark execution violates the ACID properties.
First, the move operation executed by the driver is not atomic. If the network connection fails or the driver process crashes while moving the files, the target location will only contain a part of the dataset. In other words: you end up with inconsistent data. Furthermore, during the move another application can read the data and observe the inconsistent state of the dataset.
The second issue with cloud storage systems is that the move operation makes a copy of the files. Therefore, it is a sequential operation that can take a long time which increases the risk of inconsistent reads by consumers of the dataset.
Another issue occurs when using Overwrite mode in Spark. It is two operations (delete and write), if the driver fails in between the operation, it will delete previous data and does not write the new data. This results in data loss.
Finally, even if the driver does not fail, there is a point in time that data is deleted and then written. The fact that the data is not always persisted in a valid state can cause consistency problems.
Delta Lake is an additional layer between Apache Spark and storage systems, that addresses these issues by providing ACID transactions.
How does the Delta Lake format work?
Delta Lake uses a transaction log (also known as DeltaLog) in order to implement ACID transactions. The transaction log is an ordered record of every transaction that has been committed since the Delta Lake creation.
When a user creates a Delta Lake table, a new transaction log is automatically created in the _delta_log/ subdirectory. Any new change users apply to the table is recorded as ordered atomic commits in the transaction log. Delta Lake writes every commit into a JSON file, with a name starting as 00000000000000000000.json. Similarly, the subsequent changes to the table produce new JSON files in the ascending numerical order.
/tmp/deltaPath7589771148223852481/
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── partitionId=0
│ ├── part-00000-1db4932a-a7d6-4478-93a0-99488999d584.c000.snappy.parquet
│ └── part-00000-52cffe75-e13c-4bf2-988a-a7b64e9304a6.c000.snappy.parquet
├── partitionId=1
│ ├── part-00000-9ba571bc-8256-46c9-870a-905e4e32c7c3.c000.snappy.parquet
│ └── part-00000-a15e768e-fd1a-43e4-bc0c-1eaa4bd83157.c000.snappy.parquet
└── partitionId=2
├── part-00000-0e7b64dc-d183-4f9e-a7b2-abfbf0637de8.c000.snappy.parquet
└── part-00000-8a97f406-5ce3-4227-89b8-714f60f495e9.c000.snappy.parquet
Each commit log contains a series of steps known as actions such as INSERT, UPDATE or DELETE.
For example, the contents of the /tmp/deltaPath7589771148223852481/_delta_log/00000000000000000001.json commit log:
{
“commitInfo”:{
“timestamp”:1583312472793,
“operation”:”WRITE”,
“operationParameters”:{
“mode”:”Overwrite”,
“partitionBy”:”[“partitionId”]”
},
“readVersion”:0,
“isBlindAppend”:false
}
}{
“add”:{
“path”:”partitionId=0/part-00000-1db4932a-a7d6-4478-93a0-99488999d584.c000.snappy.parquet”,
“partitionValues”:{
“partitionId”:”0″
},
“size”:632,
“modificationTime”:1583312468000,
“dataChange”:true
}
}{
“add”:{
“path”:”partitionId=1/part-00000-a15e768e-fd1a-43e4-bc0c-1eaa4bd83157.c000.snappy.parquet”,
“partitionValues”:{
“partitionId”:”1″
},
“size”:643,
“modificationTime”:1583312468000,
“dataChange”:true
}
}{
“add”:{
“path”:”partitionId=2/part-00000-0e7b64dc-d183-4f9e-a7b2-abfbf0637de8.c000.snappy.parquet”,
“partitionValues”:{
“partitionId”:”2″
},
“size”:632,
“modificationTime”:1583312468000,
“dataChange”:true
}
}{
“remove”:{
“path”:”partitionId=2/part-00000-8a97f406-5ce3-4227-89b8-714f60f495e9.c000.snappy.parquet”,
“deletionTimestamp”:1583312472792,
“dataChange”:true
}
}{
“remove”:{
“path”:”partitionId=0/part-00000-52cffe75-e13c-4bf2-988a-a7b64e9304a6.c000.snappy.parquet”,
“deletionTimestamp”:1583312472793,
“dataChange”:true
}
}{
“remove”:{
“path”:”partitionId=1/part-00000-9ba571bc-8256-46c9-870a-905e4e32c7c3.c000.snappy.parquet”,
“deletionTimestamp”:1583312472793,
“dataChange”:true
}
}
As you can see, the log contains some add and remove actions. In this case, the user overwrote the previous dataset with new data. As a result, Delta Lake recorded that transaction by removing files that contain previous data and adding new files containing the new data.
Even though the removed files are no longer needed, the Delta Lake keeps these commits so that we can go back in time and check the table at any particular point in time. Moreover, this also helps with table audit, governance and compliance requirements since an exact record of every change ever made is retained.
So how does this help with ACID?
The actual execution is still similar to previous process, only now there is the additional step to write the JSON log file.
- The Spark tasks write the partitions into the _temporary folder as parquet files. They report their statutes to the driver.
- Once all tasks report success, the driver sequentially moves the parquet files from the temporary location to their final location.
- Additionally, now the driver writes the JSON file into the _delta_log folder in order to describe the transaction operations.
The important part is the last step: a single, atomic JSON file write operation.
For example, S3 supports it as single atomic write operation (read-after-write consistency). Therefore, it prevents users from reading an inconsistent dataset as the JSON file would not be written yet. The readers would not see the new added or removed actions.
What’s next?
In this blog we’ve given you an introduction to the Delta Lake and how it achieves ACID transactions on top of the affordable cloud storage systems. There are many more features Delta Lake offers ranging from optimistic concurrency control, checkpointing, schema enforcement and schema evolution to vacuum optimization. Please refer to the references for more information.
In the next article we are going to explore the DeltaLog API and describe how we import from Delta Lake into an Exasol table, so keep an eye on this blog. In the meantime, check out our latest insights for more on our technical offering.