

In our last blog article about Exasol Virtual Schemas we started giving you an introduction into how Virtual Schemas work. We also hinted that we’re rewriting good parts of the code to make it more extensible. Today we are going to pick up where we left off and talk about how new architecture requests from the core database are dispatched to the responsible Virtual Schema Adapter.
The six Virtual Schema requests
At the time of this writing, our Virtual Schemas can recognize six different requests:
- Create a new Virtual Schema
- Drop an existing Virtual Schema
- Get fresh metadata from the external source, either for everything used or for selected tables only
- Set Virtual Schema properties
- Get a list of capabilities that the Virtual Schema Adapter supports
- Push an SQL statement down to the external source
Each Virtual Schema Adapter must be prepared to receive any of these requests. This doesn’t necessarily mean all Virtual Schema Adapters need be able to do something useful with each request type. In fact, having push-down capability is a rare commodity.
Virtual Schema request dispatching – communicating with external data sources
Imagine the Virtual Schema Adapter as a kind of a software driver that’s responsible for communicating with the external data source using a protocol that it understands. Talking to an Oracle database requires different mechanisms than talking to PostgreSQL.
The ‘control center’ that decides where Virtual Schema Adapter requests are routed is called the RequestDispatcher.
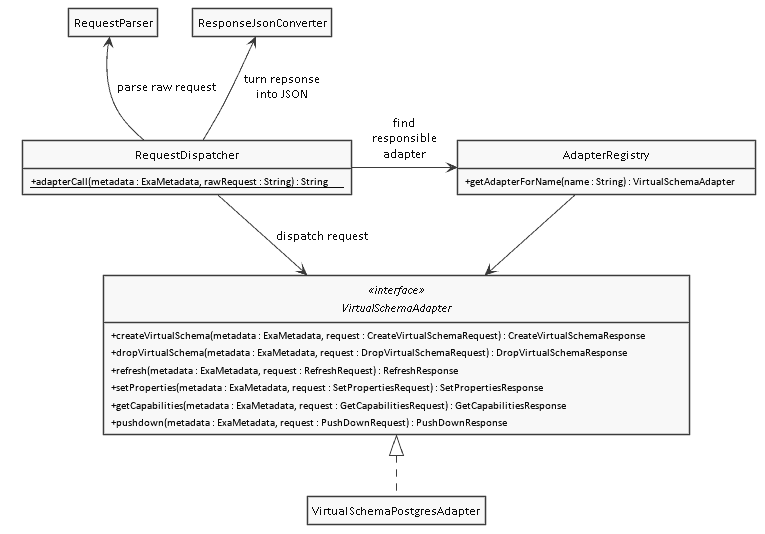
As you can see above, the main entry point into a Virtual Schema is a static method:
public static String adapterCall(final ExaMetadata metadata, final String rawRequest)
Right after that method is called, the RequestDispatcher uses the RequestParser to turn the string containing the raw request in a JSON format into a Loading...Java object representing the request. For example CreateVirtualSchemaRequest.
Next, the dispatcher queries the AdapterRegistry to find out which adapter is responsible for handling the request. Once that’s done, it dispatches the request to that adapter.
Users configure the parameter SQL_DIALECT during Virtual Schema creation. It’s AdapterRegistry that associates dialects with adapters. Adapters need to register and let the AdapterRegistry know which type of dialect they handle – how exactly that’s done is a story for another article.
For the moment it’s enough to understand that each loaded adapter can be found through the registry.
Virtual Schema Adapters handle requests – doing the heavy lifting
Each adapter implements an interface called VirtualSchemaAdapter. In this interface you find one method, per the type of request we discussed earlier . It’s the implementation of these request methods that do the actual heavy lifting inside a Virtual Schema.
What exactly happens inside those methods depends on the individual adapter. They all have in common though that they need to return a response object. This part is most important in case of requests where the response is more than just a confirmation. As you might have guessed already, the GetCapabilitiesResponse for example contains a list of capabilities that this particular adapter supports.
Responding to a request – and sending it back to the database core
As a last step the RequestDispatcher uses the ResponseJsonConverter to turn the Java object representing the adapter’s response into JSON, so that it can be sent back to the database core.
Where do you go from here?
In today’s blog article you learned how Virtual Schemas receive requests, dispatch them to the responsible Virtual Schema Adapter, and how to respond to them. Now you’re all set up to start writing you own Virtual Schema Adapters – and you can contribute to one of the Virtual Schema Adapters which are available as Open Source software on GitHub.
And, if there’s anything else you would like me to cover, or you have any burning questions feel free to get in touch with us. We’re always happy to help – especially if it involves tech, of course.