

Following up on our series about Virtual Schemas, today we’re looking at what it takes to create you own adapter for a database that offers a JDBC driver. And as a word of warning, we’re going to be knee-deep in the code, so this article’s main audience are definitely software developers.
Sooner or later you might think about connecting Exasol’s analytics database with an external source for which no adapter exists yet. If that source offers a JDBC driver, you don’t need to implement a complete Virtual Schema adapter. Instead you can add a new SQL dialect adapter based on what we call the JDBC adapter.
In the following section we’ll walk through the process of developing such a SQL dialect adapter by looking at how the adapter for Amazon’s AWS Athena was created.
Athena is based on the Open Source project Apache Presto which in the own words of the Presto team is a”distributed SQL query engine for Loading...Big Data.”
In short it’s a cluster of machines digging through large amounts of data stored on a distributed file system. As the motto suggests, the user interface is SQL. That means that Presto looks at the source data from a relational perspective. It is no wonder a JDBC driver exist for both Presto and Athena.
Clean code
In this article we’ll be using Test-Driven Development to create the new adapter. That means we’re first going to write the unit tests, making sure they fail, implement the code – and then rerun the test. And we’ll do all of this in small, easily digestible bytes.
We are also going to check test coverage once we’re done.
How dialect adapters are integrated into the JDBC dapter
In the following class diagram you can see how SQL dialects are instantiated.
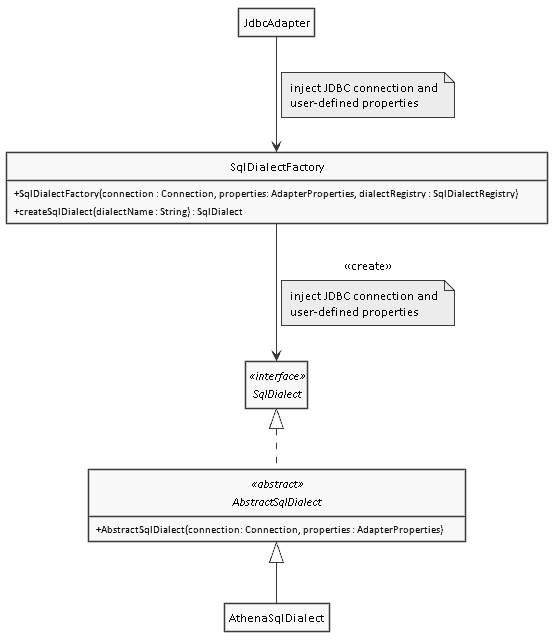
The Loading...java">JdbcAdapter uses the SqlDialectFactory to instantiate an implementation of the interface SqlDialect.
Developing an SQL Dialect Adapter
Start by creating a new package called com.exasol.adapter.dialects.athena for the dialect in both src/main/java and src/test/java.
Now create a stub class for the dialect: com.exasol.adapter.dialects.athena.AthenaSqlDialect that extends AbstractDialect.
Add a static method to report the name of the dialect:
private static final String NAME = "ATHENA";
public static String getPublicName() {
return NAME;
}
Add a constructor that takes a JDBC database connection and user properties as parameters.
/**
* Create a new instance of the {@link AthenaSqlDialect}
*
* @param connection JDBC connection to the Athena service
* @param properties user-defined adapter properties
*/
public AthenaSqlDialect(final Connection connection, final AdapterProperties properties) {
super(connection, properties);
}
Add the fully qualified class name to src/main/resources/sql_dialects.properties: com.exasol.adapter.dialects.athena.AthenaSqlDialect so that the class loader can find your new dialect adapter.
The following step is still necessary by the time of this writing, but will soon be obsoleted and replaced by an automatism.
In com.exasol.adapter.jdbc.JdbcAdapter/adapterCall(ExaMetadata, String) add the following line:
registerAdapterForSqlDialect(adapter, "ATHENA");
Create an empty unit test class for the dialect: com.exasol.adapter.dialects.athena.AthenaSqlDialectTest that tests class AthenaSqlDialectTest.
Now that you have the skeleton of the dialect adapter, it’s time to implement the specifics.
Acquiring information about the specifics of the dialect
There are three ways to find out what the specifics of the source that you want to attach to are. Knowing which of those works really depends on the availability and quality of the available information about that data source.
They’re listed in ascending order of the effort you need to spend on them :
- Read the documentation
- Read the source code
- Reverse engineering (here: fancy way of saying “trial and error”)
In most cases it is at least a combination of 1. and 3. If you’re lucky enough to attach to an Open Source product, 2. is incredibly helpful.
In our Athena example, the user guide is a good starting point for investigating capabilities, data mapping and special behavior.
Implementing the SQL dialect adapter’s main class
Defining the supported capabilities
For example, we need to find out which capabilities the source supports – and looking at the list of SQL queries, functions and operators you’ll see it contains what we need to assemble the capability list. All you have to to is read through the SQL reference and each time we come across a capability, mark that to the list.
The list of capabilities that Exasol’s Virtual Schemas know can be found in com.exasol.adapter.capabilities.MainCapabilities from the project virtual-schema-common-java. If you look at the JavaDoc of that class, you find helpful examples of what that capability means.
Write a unit test that checks whether the SQL dialect adapter reports the capabilities that you find in the documentation of the data source. Here is an example from the Athena adapter.
package com.exasol.adapter.dialects.athena;
import static com.exasol.adapter.capabilities.MainCapability.*;
import static org.hamcrest.Matchers.containsInAnyOrder;
import static org.junit.Assert.assertThat;
import org.junit.Test;
import org.junit.jupiter.api.BeforeEach;
import com.exasol.adapter.AdapterProperties;
public class AthenaSqlDialectTest {
private AthenaSqlDialect dialect;
@BeforeEach
void beforeEach() {
this.dialect = new AthenaSqlDialect(null, AdapterProperties.emptyProperties());
}
@Test
void testGetMainCapabilities() {
assertThat(this.dialect.getCapabilities().getMainCapabilities(),
containsInAnyOrder(SELECTLIST_PROJECTION, SELECTLIST_EXPRESSIONS,
FILTER_EXPRESSIONS, AGGREGATE_SINGLE_GROUP,
AGGREGATE_GROUP_BY_COLUMN, AGGREGATE_GROUP_BY_EXPRESSION,
AGGREGATE_GROUP_BY_TUPLE, AGGREGATE_HAVING,
ORDER_BY_COLUMN, ORDER_BY_EXPRESSION, LIMIT));
}
}
Reading through the Athena and Presto documentation I realized that while LIMIT in general is supported LIMIT_WITH_OFFSET is not. The unit test reflects that.
Run the test and it must fail, since you did not implement the the capability reporting method yet.
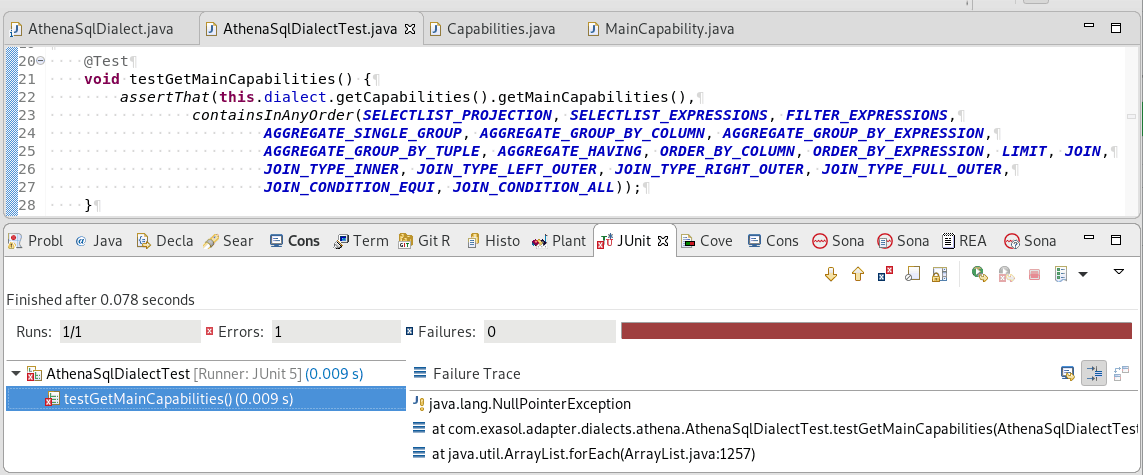
Now implement the method getCapabilities() in the dialect adapter so that it returns the main capabilities.
import static com.exasol.adapter.capabilities.MainCapability.*;
// ...
public class AthenaSqlDialect extends AbstractSqlDialect {
private static final Capabilities CAPABILITIES = createCapabilityList();
private static Capabilities createCapabilityList() {
return Capabilities //
.builder() //
.addMain(SELECTLIST_PROJECTION, SELECTLIST_EXPRESSIONS,
FILTER_EXPRESSIONS, AGGREGATE_SINGLE_GROUP,
AGGREGATE_GROUP_BY_COLUMN,
AGGREGATE_GROUP_BY_EXPRESSION,
AGGREGATE_GROUP_BY_TUPLE,
AGGREGATE_HAVING, ORDER_BY_COLUMN,
ORDER_BY_EXPRESSION, LIMIT) //
.build();
}
// ...
@Override
public Capabilities getCapabilities() {
return CAPABILITIES;
}
// ...
}
Since the capabilities of the adapter do not change at run time, I assigned them to a constant. This way the Capabilities object is instantiated only once, which makes querying the capabilities cheaper.
Now repeat that procedure for all other kinds of capabilities.
Defining Catalog and Schema Support
Some databases know the concept of catalogs, others don’t. Sometimes databases simulate a single catalog. The same is true for schemas. In case of a Loading...relational database you can try to find out whether or not catalogs and / or schemas are supported by simply looking at the Data Definition Language (DDL) statements that the SQL dialect provides. If CREATE SCHEMA exists, the database supports schemas.
If on the other hand those DDL commands are missing, that does not rule out that pseudo-catalogs and schemas are used. You will see why shortly.
A Virtual Schema needs to know how the data source handles catalogs and schemas, so that it can:
- Validate user-defined catalog and schema properties
- Apply catalog and schema filters exclusively to the places where those concepts are supported
A quick look at the Athena DDL tells us that you can’t create or drop catalogs and schemas. On the other hand the JDBC driver simulates catalog support with a single pseudo-catalog called AwsDataCatalog.
And the documentation of the SHOW DATABASES command state that there is a synonym called SHOW SCHEMAS. That means that Athena internally creates a 1:1 mapping of databases to schemas with the same name.
So we implement two very simple unit tests.
@Test
void testSupportsJdbcCatalogs() {
assertThat(this.dialect.supportsJdbcCatalogs(),
equalTo(StructureElementSupport.SINGLE));
}
@Test
void testSupportsJdbcSchemas() {
assertThat(this.dialect.supportsJdbcSchemas(),
equalTo(StructureElementSupport.MULTIPLE));
}
Both tests must fail. After that implement the functions supportsJdbcCatalogs() and supportsJdbcSchemas(). Re-run the test.
The methods requiresCatalogQualifiedTableNames(SqlGenerationContext) and requiresSchemaQualifiedTableNames(SqlGenerationContext) are closely related. They define under which circumstances table names need to be qualified with catalog and / or schema name.
Below you’ll find two unit tests. The first checks that the Athena adapter doesn’t require catalog-qualified IDs when generating SQL code. And the second states that schema-qualification is required.
@Test
void testRequiresCatalogQualifiedTableNames() {
assertThat(this.dialect.requiresCatalogQualifiedTableNames(null),
equalTo(false));
}
@Test
void testRequiresSchemaQualifiedTableNames() {
assertThat(this.dialect.requiresSchemaQualifiedTableNames(null),
equalTo(true));
}
Defining identifier quoting
Different products have different case-sensitivity and quoting rules for identifiers like table names. Exasol’s Loading...analytics database for example silently converts all unquoted identifiers to upper case. PostgreSQL on the other hand converts them to lower case. MySQL table names are case-sensitive since they directly map to the names of the files containing the table data. In order to translate identifiers correctly between Exasol’s analytics database and the remote source, we must define the behavior of the remote data source.
In our Athena example the situation is tricky. The documentation states that Athena itself is uses case-insensitive table names. On the other hand combining Athena with Apache Spark forces case-sensitive table handling. For now we implement the default behavior and let Exasol’s analytics database handle all unquoted identifiers as if they were upper case.
As always, start with the unit test:
@Test
void testGetUnquotedIdentifierHandling() {
assertThat(this.dialect.getUnquotedIdentifierHandling(),
equalTo(IdentifierCaseHandling.INTERPRET_AS_UPPER));
}
Let the test fail, implement getUnquotedIdentifierHandling() and repeat the test.
Exasol treats quoted identifiers with the exact case. Athena doesn’t. A simple SQL command on a table where all identifiers are lower case proves that.
SELECT "Price" FROM "SALES" LIMIT 10;
The above command would fail on Exasol’s analytics database, but runs just fine on Athena. So we can treat all identifiers as upper case again.
Since Athena requires special care when working with identifiers that contain numbers or start with an underscore, this give us the opportunity to write a unit test that verifies a little bit more complex quoting rules.
@CsvSource({ "tableName, "tableName"", "table123, "table123"",
"_table, `_table`", "table_name, "table_name"" })
@ParameterizedTest
void testApplyQuote(final String unquoted, final String quoted) {
assertThat(this.dialect.applyQuote(unquoted), equalTo(quoted));
}
@CsvSource({ "tableName, tableName", "table123, "table123"",
"_table, `_table`", "table_name, table_name" })
@ParameterizedTest
void testApplyQuoteIfNeeded(final String unquoted, final String quoted) {
assertThat(this.dialect.applyQuoteIfNeeded(unquoted), equalTo(quoted));
}
Again the tests must fail before we add the following implementation.
private static final Pattern IDENTIFIER_WITH_NUMBERS =
Pattern.compile(".*\d.*");
@Override
public String applyQuote(final String identifier) {
if (identifier.startsWith("_")) {
return quoteWithBackticks(identifier);
} else {
return quoteWithDoubleQuotes(identifier);
}
}
private String quoteWithBackticks(final String identifier) {
final StringBuilder builder = new StringBuilder("`");
builder.append(identifier);
builder.append("`");
return builder.toString();
}
private String quoteWithDoubleQuotes(final String identifier) {
final StringBuilder builder = new StringBuilder(""");
builder.append(identifier);
builder.append(""");
return builder.toString();
}
@Override
public String applyQuoteIfNeeded(final String identifier) {
if (identifier.startsWith("_")) {
return quoteWithBackticks(identifier);
} else {
if (containsNumbers(identifier)) {
return quoteWithDoubleQuotes(identifier);
} else {
return identifier;
}
}
}
private boolean containsNumbers(final String identifier) {
return IDENTIFIER_WITH_NUMBERS.matcher(identifier).matches();
}
The pre-compiled pattern is a performance measure. You could have used identifier.matches(".*\d.*") instead, which is a little bit slower. But since quoting happens a lot, I felt that it didn’t want to waste performance here.
Defining how NULL values are sorted
Next we tell the virtual schema how the SQL dialect sorts NULL values by default. The Athena documentation states that by default NULL values appear last in a search result regardless of search direction.
So the unit test looks like this:
@Test
void testGetDefaultNullSorting() {
assertThat(this.dialect.getDefaultNullSorting(),
equalTo(NullSorting.NULLS_SORTED_AT_END));
}
Again run the test, let it fail, implement, let the test succeed.
Implement string literal conversion
The last thing we need to implement in the dialect class is quoting of string literals. Athena uses an approach typical for many SQL-capable databases. It expects string literals to be wrapped in single quotes and single quotes inside the literal to be escaped by duplicating each.
@ValueSource(strings = { "ab:'ab'", "a'b:'a''b'", "a''b:'a''''b'",
"'ab':'''ab'''" })
@ParameterizedTest
void testGetLiteralString(final String definition) {
final int colonPosition = definition.indexOf(':');
final String original = definition.substring(0, colonPosition);
final String literal = definition.substring(colonPosition + 1);
assertThat(this.dialect.getStringLiteral(original), equalTo(literal));
}
You might be wondering why I did not use the CsvSource parameterization here. This is owed to the fact that the CsvSource syntax interprets single quotes as string quotes which makes this particular scenario untestable.
After we let the test fail, we add the following implementation in the dialect:
@Override
public String getStringLiteral(final String value) {
final StringBuilder builder = new StringBuilder("'");
builder.append(value.replaceAll("'", "''"));
builder.append("'");
return builder.toString();
}
Checking the code coverage of the dialect adapter
Before you move on to mapping metadata, first check how well your unit tests cover the dialect adapter.
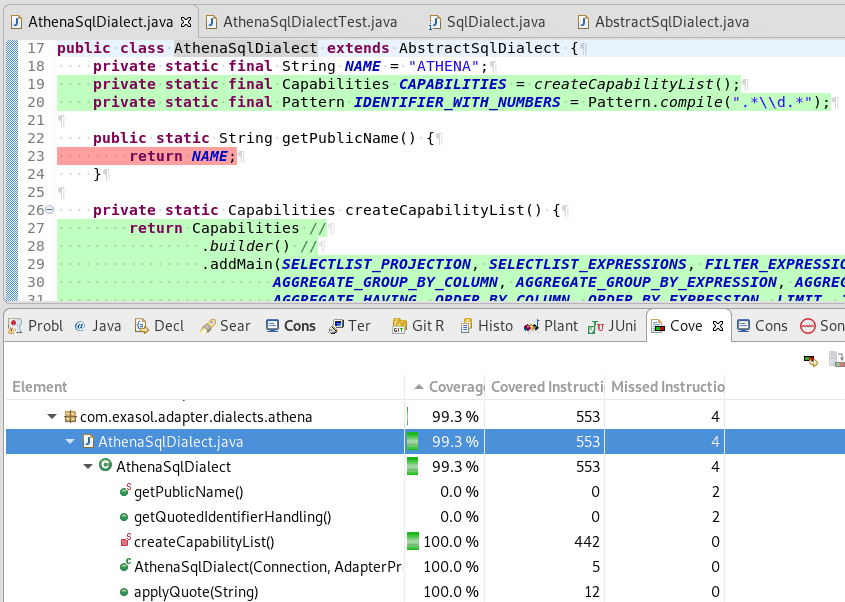
In my example I forgot to test the static method getPublicName() and the code coverage showed that clearly.
To be continued…
In part 2 of this blog post we’ll talk about reading metadata from the remote data source. And we will address data type conversion.