

In the case of Apache Spark, there seems to be a real need to shed light on it in order to understand how it interacts with other technologies and how to integrate it in your existing IT environment.
Apache Spark – is it really the Swiss Army Knife for analytics? Or does that sound too good to be true?
Well, positioning Spark as the solution for everything does indeed sound great, but it’s just not the case. We all know that data processing and analytics is not that simple. And yet, people do like to hear about simple solutions to complex problems.
That might be the reason why I seem to have conversations that go something like this:
Prospect:
How would you compare Exasol to Spark?
Me:
Spark is general purpose platform. It is based on a modern, Loading...in-memory concept for distributed processing. From our perspective at Exasol, it’s a superb add-on and partial replacement for the Loading...Hadoop file system processing platform. We integrate very seamlessly with Spark, but I wouldn’t say Exasol is like Spark as the concepts and application scenarios vary too much.
Prospect:
But it’s also an Loading...in-memory database, right? Just like Exasol?
Me:
Well, there is a database module called Spark SQL that you can run on top of the general purpose processing platform.
Prospect:
(panicked) So, why aren’t you worried? Surely you should be, after all there is now another in-memory database that’s free. Who will buy an Exasol license when you can run Spark for free?
Me:
(serene) Calm down. Take a seat. Before we get carried away, let’s look at the facts:
| Exasol Analytic Database | Apache Spark | |
|---|---|---|
| What is it? | A system designed from the ground up as in-memory analytic database system for Loading...big data | Multi-purpose computing platform for big data processing |
| What is the technology that it’s based on? | Exasol is implemented in C++ based on low-latency high-performance algorithms and specialized sub-systems | Spark & Spark SQL are implemented on JVM basis (to be more precise: in Scala). The usage of Scala permits fast development cycles but is not well suited for near-realtime applications. |
| Optimization | Optimized for fast query execution, high query throughput, and high concurrency | As Spark SQL uses the general purpose Spark framework, optimization for database purposes is limited. |
| Performance | Fastest Loading...relational database available (1) | Pretty fast but not even the fastest database on Hadoop (2) and much slower than Exasol |
| Maturity | Founded in 2000. First customer in production: 2006. A large number of customers use it in business critical environments | Development of Spark SQL started in 2013. First release in 2014. |
| Ease of use | Simple to install & simple to administrate. Focus on low TCO | Very technical platform and a shared platform- therefore careful resource management is crucial |
| Enterprise readiness | Comprehensive backup functionalities, remote administration interfaces, remote datacenter replication and and many more enterprise features. More than 100 customers run their analytics and their businesses on Exasol. |
No specific enterprise database functionalities. |
(1) According to TPC-H: www.Exasol.com/en/in-memory-database/tpc-h/
(2) https://blog.cloudera.com/blog/2016/02/new-sql-benchmarks-apache-impala-incubating-2-3-uniquely-delivers-analytic-database-performance/
Prospect:
OK, so that means Spark is not an alternative to Exasol when maximum query performance and enterprise functionality are required. So why are you nervous because of Spark?
Me:
I never said we were worried. We know that Exasol is much better-suited to large scale analytics, not Spark. Period.
Prospect:
OK, but do you think that Spark is a good data processing platform?
Me:
Yes, Spark translates the old sluggish Hadoop MapReduce-based concept into our fast agile world very well. It is a great solution
for data solutions to use with streaming data and polystructured data.
Prospect:
So now I can have two solutions that are isolated? Exasol for my high performance relational back-end for
business-critical applications, and Spark as my data processing workbench?
Me:
Well, they don’t have to be isolated at all. Let’s have a look at this illustration:
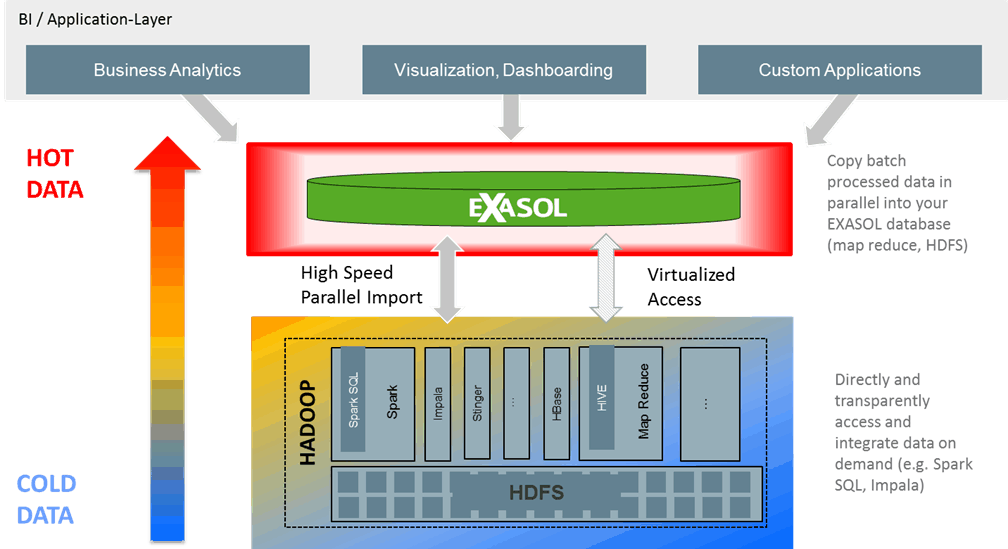
Me:
We integrate with Spark and Hadoop on different levels.
- Import data – typically you analyze your raw data stored in different formats in Spark/Hadoop first. Afterwards you would like to make the data available for further interactive analysis or operational system. To do so, just import the data in parallel into Exasol at high speeds (several GB per minute) from HDFS using our high-speed parallel importer or import from Hive, Impala or Spark SQL via JDBC.
- Sometimes you don’t want to replicate the data. You want to access exactly the data set that has been generated just seconds ago on your Spark platform. Here our data virtualization framework comes into play: just connect Spark SQL to Exasol through “virtual schemas” and the Spark SQL schemas are instantly visible in Exasol.
From a client’s perspective it is fully transparent whether data is stored in Exasol or in the remote SPARK system. The client just sees one single data source: Exasol. As soon as you access the virtually connected schema the (sub-)query is pushed down to Spark SQL, the query is being executed and the result is returned to Exasol. You want to access the data more quickly ? No problem: Just materialize the data returned by the Spark SQL query in Exasol and use for lightning fast Loading...in-database analytics in Exasol.
Got it?
Prospect:
Got it!
For more information on Exasol and how to get started for free, simply go to https://www.exasol.com/en/download/