Interactive Text Mining mit Exasol und INDREX-MM
Our guest author Prof. Dr. habil. Alexander Löser conducts research and teaches in the areas of Database Systems and Text-based Information Systems at Beuth University of Applied Sciences Berlin since September 2013. He is also a founding member of the Data Science Research Group of the Beuth University and a member in the ERCIM EU Expert Group on Loading...Big Data Analytics.
Summary. Textual data is a core source of information in the enterprise. Example demands arise from sales departments (monitor and identify leads), human resources (identify professionals with capabilities in “xyz”), market research (campaign monitoring from the social web), product development (incorporate feedback from customers), supply chain management (check for product recalls) or from the medical domain (anamnesis).f
In this post we present INDREX-MM, our extension to the Exasol main memory database system for interactively executing two interwoven tasks, declarative relation extraction from text and their exploitation with SQL. INDREX- MM simplifies these tasks for the user with powerful SQL extensions for gathering statistical semantics, for executing open information extraction and for integrating relation candidates with domain specific data. We demonstrate these functions on 800k documents from Reuters RCV1 with more than a billion linguistic annotations and report execution times in the order of seconds.
1. Introduction to INDREX-MM
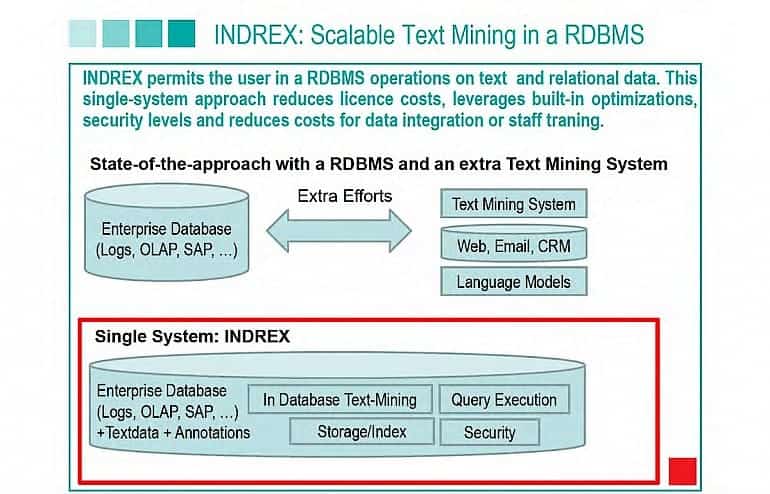
Our task is complement existing in-house relational data with insights from text. While browsing news, a supply chain analyst performs research on suppliers of a car rental company, product recalls. She desires to complement an existing table productrecall (supplier, product), with relations extracted from news text. Currently, the user performs these task with two separate systems, a system for extracting a relation productrecall (supplier, product) from news data and a relational database management system (RDBMS) for joining, grouping, aggregating and ordering. In a typical work flow, the user ships existing tables from the RDBMS to bootstrap text and ships back extracted relations to the RDBMS for analytical queries. This costly work flow is iterated until an analytical query shows desired results. Moreover, the user must learn to manage both systems.
Contribution. Ideally, users could execute both, analytical and relation extraction tasks, in a single database system and could leverage built-in query optimizations. Another crucial requirement is inter- active query execution, in particular for extracting rare relation types with high recall and precision. We demonstrate INDREX-MM, a Main-Memory Relational Database System (MM-RDBMS) based on Exasol that permits this functionality on SQL command line. INDREX-MM provides a broad and powerful set of SQL-based query operators for declarative relation extraction. These include query predicates for detecting span proximity, predicates for testing overlapping spans or span containment, scalar functions for returning the context of a span, or user defined table generating functions for consolidating spans. Further, the system supports executing regular expressions and built-in operators from the RDBMS, such as joins, unions or aggregation functions. These additional operators permit the user basic operations for looking up words in sentences describing entities or other potential relation arguments. The system also supports the user learning about potential open relation candidates where these words appear in, or about distributions of potentials synonymous relation names. Finally, we support the user in investigating new relations. Our work in (Kilias et al., 2015) shows details and extensive performance evaluations. INDREX-MM bases on Exasol, a parallel main-memory and column-oriented database. It permits integration via standard interfaces, such as JDBC, or business intelligence tools, like Tableau.
2. Demonstration Outline
We demonstrate how INDREX-MM supports the user in three elementary steps during the declarative relation extraction process, for which figure 1 gives a high-level overview. Each of these steps “filters out” irrelevant sentences and only keeps sentences containing relations of the type productrecall (supplier, product).
Figure 1: Relation Extraction process using Open Information Extraction in INDREX-MM.
Batch loading base annotations in a flat, sparse and cache affine data structure.
Text mining work- loads rarely require full scans of all table data, but do often require full scans of a small subset of the columns. Our base table layout from (Kilias et al., 2015) supports such work flows. This schema partitions data per (document, span); we denote a span with its beginning and ending character. Many operations on text are “local” on a single document. Hence, our partition scheme permits a MM-RDBMS to ship data for a single document “close” to the CPU and in orders of magnitudes faster cache structures. For each span we apply a NLP tagger and provide additional attributes denoting annotation types, such as tokenization, sentence recognition, part-of-speech tagging, named entity recognition, user-defined types, dependency tagging, or noun- and verb-phrase chunking. Too, we add attributes for referencing spans to containment relations in the same document. For example, a span for a sentence may contain additional spans denoting organisations. Our flat and sparse table layout pre-joins data already at data loading time and avoids most joins at query execution time. Because of the columnar layout in Exasol, NULL values in attributes do not harm query execution time.
(a) Extractor query and result example:
(b) Dependency parse and phrase chunks used in extractor query:
Figure 2: Query example of an Open Information Extraction pattern.
Step 1: Filtering relation candidates with Open Information Extraction.
Open Information Extraction (OIE) is the task of extracting relations from large corpora and without requiring a pre-specified vocabulary. Relations are n-ary and arguments do not follow a pre-defined type set. From the perspective of a database, we understand OIE as selective filters connecting arguments in sentences. We provide the user in INDREX-MM a set of “ready-to-use” OIE filters in SQL as views as shown in figure 2. The user can add SQL-predicates for OIE and can debug directly on her corpus, while the MM-RDBMS takes over on optimizing the execution.
(a) Join of the Union OIE table with in house data regarding:
(b) Relation candidates grouped, counted and ordered by pattern and verb.
The most frequent combination is OIE-Pattern 4 and the verb “recall”:
Figure 3: Use of in-house data to spot patterns of productrecall(supplier, product) in a OIE schema.
Step 2: Joining OIE relations with domain data into a universal schema and spotting patterns.
After step 1 relations connect two or more relation arguments. However, we need to filter out irrelevant relations and only keep relations that belong to our desired relation type productrecall. For example, we keep relations connecting a company with predicates, such as “recalls”, “withdraws” and discard relations with “sold” or “has refused”. For executing this task we join arguments of OIE-relations with in-house domain specific relations representing the same semantic type, such as a table describing product recalls of the suppliers of a company. As a result, our universal schema represents relations, mainly candidate patterns of our desired relation type, and few patterns for other semantic types (see figure 3a). The fast execution performance of INDREX-MM on Exasol permits the user to filter out these irrelevant patterns manually. For example, she aggregates, groups and counts patterns with standard SQL, orders patterns by frequency and marks unsuitable patterns (see figure 3b). For spotting additional semantic patterns, we provide synonyms from Wordnet. The user can execute a join and utilize these patterns as additional filters for OIE candidates.
Step 3: Applying selectional restriction and enhancing recall.
For further enhancing recall, the user keeps lexical patterns for predicates from the last step but applies various selectional restrictions to arguments. INDREX-MM supports selectional restrictions to one or many argument types. For example, the user may keep the company name of relations from step 2, but relaxes the second argument. As a result, she may spot new relations of productrecall(supplier, product), in particular relations between previously known companies and previously unknown products.
3 Discussion
Execution on one billion annotations in seconds. We measure the relation extraction process from above in INDREX-MM on Reuters RCV1 with 800k documents and 1.2 billion annotations. For each of the four steps mentioned above we measure the execution time and how selective each filtering step prunes sentences. For evaluating precision, we asked two independent students to draw a sample of 100 sentences randomly after each step and to count the number of correct relations for our desired type.
| Step | Time | Relations | RL100 | Examples |
|---|---|---|---|---|
| BL
1 OIE |
180 min
9,9s |
15.785.155
13.695.006 |
0
10 |
–
All OIE pattern (Mitsubishi, raised its production plan, October) |
| 2 PR
3 PR |
49ms
619ms |
134
921 |
31
61 |
Product recall(GM, recalls, 1,400 1997 Corvettes)
Product recall(Tensor, recalls, halogen bulbs) |
| 2 AL
3 AL |
16.64s
2.505s |
662
3.265 |
35
91 |
Alliance(LUKoil, signed, a $2-billion deal, with SOCAR)
Alliance(Xillix, signed, an agreement, with Olympus) |
| 2 AC
3 AC |
5.643s
7.031s |
112
1654 |
41
73 |
Acquisition(Quaker, reviews, Snapple)
Acquisition(Quaker, acquired, Snapple, for, $1.8 billion) |
Table1: Performance for each step.
After phase BL, we loaded 15.7 Mio sentences and estimate one relation per sentence. In step 1, we extract OIE relations from sentences using the 7 basic patterns from ClausIE resulting in slightly fewer OIE relations than sentences. For phase 2 and 3 we show results for productrecall(supplier, product), alliance(company, company) and acquisition(company, company). We count correct relations on a randomly taken sample of 100 sentences (RL100).
Table 1 shows our measurements and example sentences. One-time batch loading (denoted with BL in Table 1) takes roughly 180 minutes, because the MM-RDBMS executes compressions and builds index structures before we can run queries. In a streaming scenario the MM-RDBMS uses delta indexing techniques and permits hitting queries while new data is inserted.
INDREX-MM exploits data locality and leverages multi-core shared memory architectures.
INDREX-MM avoids data shipping, rather ships functionality to data, and even leverages multiple built-in optimizations of main memory RDBMSs, such as massive parallel execution with multi-cores, compression techniques and columnar based table layouts, cache affine data structures, single instruction multiple data (SIMD) or result materializations.
INDREX-MM comes with predefined rule sets for Open Information Extraction.
Often the SQL user is not familiar with current approaches for extracting relations. INDREX encapsulates this knowledge in views. The user may start with predefined views and may add further rules if necessary. As a result, we could ask master students familiar with SQL and very basic knowledge in NLP in applying INDREX to an unknown corpus and domain, while the students quickly gathered first results. The very fast performance of Exasol permitted the students iteratively extending the predefined views to the domain without learning a new programming language.
Acknowledgements: Our work is funded by the German Federal Ministry of Economic Affairs and Energy (BMWi) under grant agreement 01MD16011E (Project: Medical Allround-Care Service Solutions).
INDREX is a project of the DATEXIS.COM research group of the Beuth University of Applied Sciences Berlin, Germany. The team conducts research at the intersection of Database Systems and Text-based Information Systems.
For more information on this topic, watch this video (only in German).